1.项目介绍
本项目用于爬取前程无忧招聘网站发布的招聘信息,包括岗位名称、岗位要求、公司名称、经验要求等近30个字段,可用于对目前不同地区、行业招聘市场的数据分析中。
所用工具(技术):
IDE:pycharm
Database:MySQL
抓包工具:Fiddler
爬虫框架:scrapy
信息抓取:scrapy内置的Selector
数据存储:Twisted+MySQL(python3.7安装不了MySQLdb这个模块,应该安装mysqlclient)
2 APP抓包分析
我们先来感受一下前程无忧的APP,当我们在首页输入搜索关键词点击搜索之后APP就会跳转到新的页面,这个页面我们姑且称之为一级页面。一级页面展示着我们所想找查看的所有岗位列表。

当我们点击其中一条岗位信息后,APP又会跳转到一个新的页面,我把这个页面称之为二级页面。二级页面有我们需要的所有岗位信息,也是我们的主要采集目前页面。

分析完页面之后,接下来就可以对前程无忧手机APP的请求(request)和回复(response)进行分析了。本文所使用的抓包工具为Fiddler,关于如何使用Fiddler,请查看博客《网络爬虫中Fiddler抓取PC端网页数据包与手机端APP数据包》,在该博文中已对如何配置Fiddler及如何抓取手机APP数据包进行了详细的介绍。链接如下:
https://www.cnblogs.com/chen8023miss/protected/p/11398116.html
本文的目的是抓取前程无忧APP上搜索某个关键词时返回的所有招聘信息,本文以“Python”为例进行说明。APP上操作如下图所示,输入“Python”关键词后,点击搜索,随后Fiddler抓取到4个数据包,如下所示:

事实上,当看到第2和第4个数据包的图标时,我们就应该会心一笑。这两个图标分别代表传输的是json和xml格式的数据,而很多web接口就是以这两种格式来传输数据的,手机APP也不列外。选中第2个数据包,然后在右侧主窗口中查看,发现第二个数据包并没有我们想要的数据。在看看第4个数据包,选中后在右侧窗体,可以看到以下内容:

右下角的内容不就是在手机上看到的招聘信息吗,还是以XML的格式来传输的。我们将这个数据包的链接复制下来:
https://appapi.51job.com/api/job/search_job_list.php?postchannel=0000&&keyword=Python&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
我们爬取的时候肯定不会只爬取一个页面的信息,我们在APP上把页面往下滑,看看Fiddler会抓取到什么数据包。看下图:

手机屏幕往下滑动后,Fiddler又抓取到两个数据包,而且第二个数据包选中看再次发现就是APP上新刷新的招聘信息,再把这个数据包的url链接复制下来:
https://appapi.51job.com/api/job/search_job_list.php?postchannel=0000&&keyword=Python&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=2&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
接下来,我们比对一下前后两个链接,分析其中的异同。可以看出,除了“pageno”这个属性外,其他都一样。没错,就是在上面标红的地方。第一个数据包链接中pageno值为1,第二个pageno值为2,这下翻页的规律就一目了然了。
既然我们已经找到了APP翻页的请求链接规律,我们就可以在爬虫中通过循环赋值给pageno,实现模拟翻页的功能。
我们再尝试一下改变搜索的关键词看看链接有什么变化,以“java”为关键词,抓取到的数据包为:
https://appapi.51job.com/api/job/search_job_list.php?postchannel=0000&&keyword=java&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比后发现,链接中也只有keyword的值不一样,而且值就是我们在自己输入的关键词。所以在爬虫中,我们完全可以通过字符串拼接来实现输入关键词模拟,从而采集不同类型的招聘信息。同理,你可以对求职地点等信息的规律进行寻找,本文不在叙述。
解决翻页功能之后,我们再去探究一下数据包中XML里面的内容。我们把上面的第一个链接复制到浏览器上打开,打开后画面如下:

这样看着就舒服多了。通过仔细观察我们会发现,APP上每一条招聘信息都对应着一个<item>标签,每一个<itme>里面都有一个<jobid>标签,里面有一个id标识着一个岗位。例如上面第一条岗位是<jobid>109384390</jobid>,第二条岗位是<jobid>109381483</jobid>,记住这个id,后面会用到。
事实上,接下来,我们点击第一条招聘信息,进入二级页面。这时候,Fiddler会采集到APP刚发送的数据包,点击其中的xml数据包,发现就是APP上刚刷新的页面信息。我们将数据包的url链接复制出来:
https://appapi.51job.com/api/job/get_job_info.php?jobid=109384390&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
如法炮制点开一级页面中列表的第二条招聘,然后从Fiddler中复制出对应数据包的url链接:
https://appapi.51job.com/api/job/get_job_info.php?jobid=109381483&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比上面两个链接,发现规律没?没错,就是jobid不同,其他都一样。这个jobid就是我们在一级页面的xml中发现的jobid。由此,我们就可以在一级页面中抓取出jobid来构造出二级页面的url链接,然后采集出我们所需要的所有信息。整个爬虫逻辑就清晰了:
构造一级页面初始url->采集jobid->构造二级页面url->抓取岗位信息->通过循环模拟翻页获取下一页面的url。
好了,分析工作完成了,开始动手写爬虫了。
3 编写爬虫
本文编写前程无忧手机APP网络爬虫用的是Scrapy框架,下载好scrapy第三方包后,通过命令行创建爬虫项目:
scrapy startproject job_spider .
job_spider就是我们本次爬虫项目的项目名称,在项目名后面有一个“.”,这个点可有可无,区别是在当前文件之间创建项目还是创建一个与项目名同名的文件然后在文件内创建项目。
创建好项目后,继续创建一个爬虫,专用于爬取前程无忧发布的招聘信息。创建爬虫命名如下:
scrapy genspider qcwySpider appapi.51job.com
注意:如果你在创建爬虫项目的时候没有在项目名后面加“.”,请先进入项目文件夹之后再运行命令创建爬虫。
通过pycharm打开刚创建好的爬虫项目,左侧目录树结构如下:

在开始一切爬虫工作之前,先打开settings.py文件,然后取消“ROBOTSTXT_OBEY = False”这一行的注释,并将其值改为False。
# Obey robots.txt rules ROBOTSTXT_OBEY = False
完成上述修改后,打开spiders包下的qcwySpider.py,初始代码如下:

# -*- coding: utf-8 -*-
import scrapy
class QcwyspiderSpider(scrapy.Spider):
name = 'qcwySpider'
allowed_domains = ['appapi.51job.com']
start_urls = ['http://appapi.51job.com/']
def parse(self, response):
pass
这是scrapy为我们搭好的框架,我们只需要在这个基础上去完善我们的爬虫即可。
首先我们需要在类中添加一些属性,例如搜索关键词keyword、起始页、想要爬取得最大页数,同时也需要设置headers进行简单的反爬。另外,starturl也需要重新设置为第一页的url。更改后代码如下:
name = 'qcwySpider'
keyword = 'python'
current_page = 1
max_page = 100
headers = {
'Accept': 'text / html, application / xhtml + xml, application / xml;',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'appapi.51job.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
allowed_domains = ['appapi.51job.com']
start_urls = ['https://appapi.51job.com/api/job/search_job_list.php?postchannel=0000&&keyword='+str(keyword)+
'&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=97932608&key=a8c33db43f42530fbda2f2dac7a6f48d5c1c853a&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0']
然后开始编写parse方法爬取一级页面,在一级页面中,我们主要逻辑是通过循环实现APP中屏幕下滑更新,我们用上面代码中的current_page来标识当前页页码,每次循环后,current_page加1,然后构造新的url,通过回调parse方法爬取下一页。另外,我们还需要在parse方法中在一级页面中采集出jobid,并构造出二级页面的,回调实现二级页面信息采集的parse_job方法。parse方法代码如下:
def parse(self, response):
"""
通过循环的方式实现一级页面翻页,并采集jobid构造二级页面url
:param response:
:return:
"""
selector = Selector(response=response)
itmes = selector.xpath('//item')
for item in itmes:
jobid = item.xpath('./jobid/text()').extract_first()
url = 'https://appapi.51job.com/api/job/get_job_info.php?jobid='+jobid+'&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0'
yield scrapy.Request(url=url, headers=self.headers, dont_filter=False, callback=self.parse_job)
if self.current_page < self.max_page:
self.current_page += 1
neext_page_url = 'https://appapi.51job.com/api/job/search_job_list.php?postchannel=0000&&keyword=Python&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1'
+ str(self.current_page) + '&pagesize=30&accountid=97932608&key=a8c33db43f42530fbda2f2dac7a6f48d5c1c853a&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0'
time_delay = random.randint(3,5)
time.sleep(time_delay)
yield scrapy.Request(url=neext_page_url, headers=self.headers, dont_filter=True, callback=self.parse)
为了方便进行调试,我们在项目的jobSpider目录下创建一个main.py文件,用于启动爬虫,每次启动爬虫时,运行该文件即可。内容如下:
import sys
import os
from scrapy.cmdline import execute
if __name__ == '__main__':
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy" , "crawl" , "qcwySpider"])
二级页面信息采集功能在parse_job方法中实现,因为所有我们需要抓取的信息都在xml中,我们直接用scrapy自带的selector提取出来就可以了,不过在提取之前,我们需要先定义好Item用来存放我们采集好的数据。打开items.py文件,编写一个Item类,输入以下代码:
class qcwyJobsItem(scrapy.Item):
jobid = scrapy.Field()
jobname = scrapy.Field()
coid = scrapy.Field()
#……item太多,省略部分
isapply = scrapy.Field()
url = scrapy.Field()
def get_insert_sql(self):
"""
执行具体的插入
:param cursor:
:param item:
:return:
"""
insert_sql = """
insert into qcwy_job(
jobid ,jobname ,coid ,coname ,issuedate ,jobarea ,jobnum ,degree ,jobareacode ,cityname ,
funtypecode ,funtypename ,workyearcode ,address ,joblon ,joblat ,welfare ,jobtag ,providesalary ,
language1 ,language2 ,cotype ,cosize ,indtype1 ,indtype2 ,caddr ,jobterm ,jobinfo ,isapply ,url)
VALUES ( %s, %s, %s,%s , %s, %s, %s, %s, %s, %s, %s, %s , %s, %s, %s,%s , %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
param = (
self['jobid'], self['jobname'], self['coid'], self['coname'], self['issuedate'],
self['jobarea'], self['jobnum'], self['degree'], self['jobareacode'], self['cityname'],
self['funtypecode'], self['funtypename'], self['workyearcode'], self['address'], self['joblon'],
self['joblat'], self['welfare'], self['jobtag'], self['providesalary'], self['language1'],
self['language2'],self['cotype'], self['cosize'], self['indtype1'], self['indtype2'], self['caddr'], self['jobterm'],
self['jobinfo'], self['isapply'], self['url']
)
return insert_sql , param
上面每一个item都与一个xml标签对应,用于存放一条信息。在qcwyJobsItem类的最后,定义了一个do_insert方法,该方法用于生产将item中所有信息存储数据库的insert语句,之所以在items木块中生成这个insert语句,是因为日后如果有了多个爬虫,有多个item类之后,在pipelines模块中,可以针对不同的item插入数据库,使本项目具有更强的可扩展性。你也可以将所有与插入数据库有关的代码都写在pipelines。
然后编写parse_job方法:
def parse_job(self, response):
time.sleep(random.randint(3,5))
selector = Selector(response=response)
item = qcwyJobsItem()
item['jobid'] = selector.xpath('/responsemessage/resultbody/jobid/text()').extract_first()
item['jobname'] = selector.xpath('/responsemessage/resultbody/jobname/text()').extract_first()
item['coid'] = selector.xpath('/responsemessage/resultbody/coid/text()').extract_first()
……
item['jobinfo'] = selector.xpath('/responsemessage/resultbody/jobinfo/text()').extract_first()
item['isapply'] = selector.xpath('/responsemessage/resultbody/isapply/text()').extract_first()
item['url'] = selector.xpath('/responsemessage/resultbody/share_url/text()').extract_first()
yield item
完成上述代码后,信息采集部分就完成了。接下来继续写信息存储功能,这一功能在pipelines.py中完成。
class MysqlTwistedPipline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) #处理异常
def handle_error(self, failure, item, spider):
# 处理异步插入的异常
print ('发生异常:{}'.format(failure))
def do_insert(self, cursor, item):
# 执行具体的插入
# 根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql, params = item.get_insert_sql()
cursor.execute(insert_sql, params)
编写完pipelines.py后,打开settings.py文件,将刚写好的MysqlTwistedPipline类配置到项目设置文件中:
ITEM_PIPELINES = {
# 'jobSpider.pipelines.JobspiderPipeline': 300,
'jobSpider.pipelines.MysqlTwistedPipline':1 ,
}
顺便也把数据库配置好:
#MySQL数据库配置 MYSQL_HOST = '******' MYSQL_USER = 'root' MYSQL_PASSWORD = '******' MYSQL_DBNAME = 'job_spider'
数据库配置你也可以之间嵌入到MysqlTwistedPipline类中,不过我习惯于把这些专属的数据库信息写在配置文件中。
最后,只差一步,建数据库、建数据表。部分表结构如下图所示:

完成上述所有内容之后,就可以运行爬虫开始采集数据了。采集的数据如下图所示:
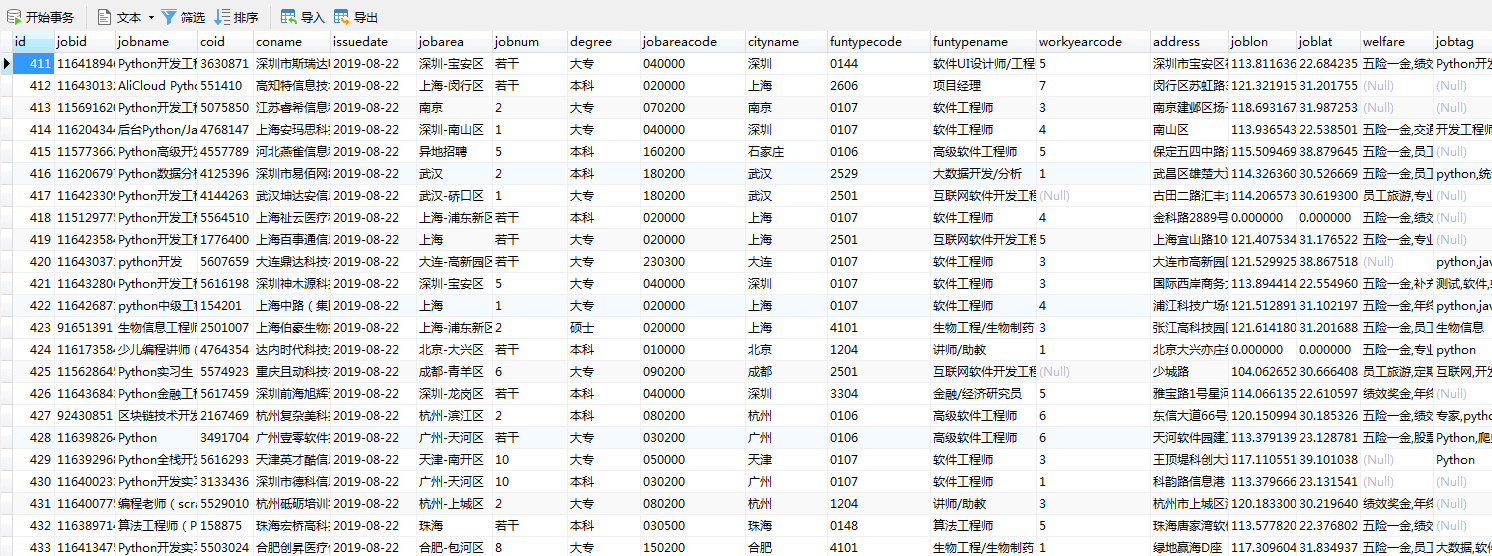
4 总结
整个过程下来,感觉前程无忧网APP爬取要比网页爬取容易一些(似乎很多网站都这样)。回顾整个流程,其实代码中还有诸多细节尚可改进完善,例如还可以在构造链接时加上求职地点等。本博文重在对整个爬虫过程的逻辑分析和介绍APP的基本爬取方法,博文中省略了部分代码,若需要完整代码,请在我的网盘中获取,后续将继续更新其他招聘网站的爬虫。
百度网盘:链接:https://pan.baidu.com/s/19nt9XjrEAg40xDHoCerz3A 提取码:n1jv