本文参考资料:
1、《大话数据结构》
2、http://www.cnblogs.com/dassmeta/p/5338955.html
3、http://www.cnblogs.com/dsj2016/p/5551059.html
4、http://blog.csdn.net/hackbuteer1/article/details/6591486/
5、http://blog.csdn.net/feixiaoxing/article/details/6848077
6、http://www.cppblog.com/cxiaojia/archive/2012/07/31/185760.html
7、http://www.cnblogs.com/dolphin0520/p/3681042.html
刚刚添加好《JDK学习---深入理解java中的String》一篇的第四节数据结构部分,相信大家对线性表的顺序存储结构有一定的了解了吧。因为HashMap的底层就涉及到了链表,那么接下来我就再介绍一下链表、尤其是单链表的知识。
一、链表
线性表的顺序存储结构,在上一篇博客《JDK学习---深入理解java中的String》的第四节买火车的例子中已经说明了,它的最大缺点就是插入或删除的时候,需要大量的移动元素,这显然是耗时间的,在数据结构中能够有更加优化的方案呢?
要解决这个问题,我们就得思考一下导致这个问题的原因。
为什么插入和删除时,需要大量移动元素,仔细分析后发现原因在于相邻的元素在存储位置也具有邻居关系,它们的编号分别为1,2,3......,n。它们在内存中也是紧挨着的,中间没有间隙,当然就无法快速的介入,而删除后,当中就会留下空隙,自然需要时间去弥补,这就是问题所在。
接下来会引入链表,链表就是链式存储的线性表。根据指针域的不同,链表分为单向链表、双向链表、循环链表等等。
本文只介绍链表中最简单的一种:单向链表。每个元素包含两个域,值域和指针域,我们把这样的元素称之为节点。每个节点的指针域内有一个指针,指向下一个节点,而最后一个节点则指向一个空值。具体请看下图:
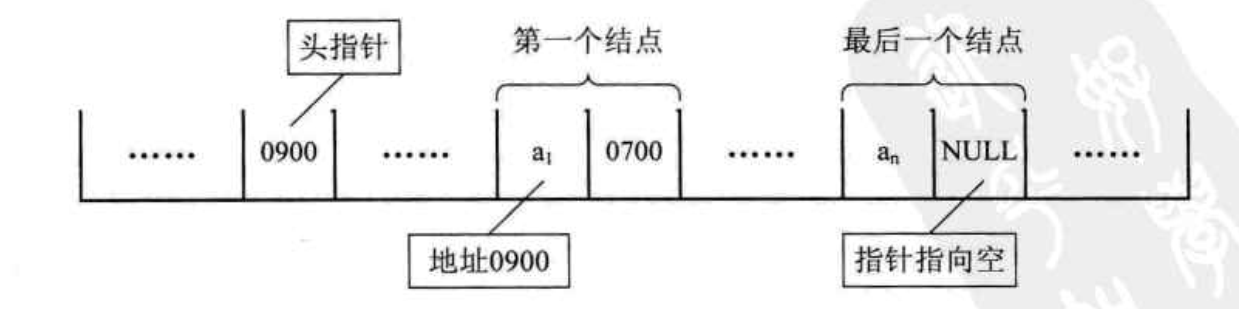
从上图我们可以看出来,每一个节点,都会存在一个指针域,而这个指针域持有的是下一个节点的地址,这样的话就可以避免每个节点元素在内存中存在邻居关系,也就是说各个节点可以分散存储,每个节点只需要持有下一个节点的内存地址即可。这样也就避免了像线性表的顺序存储结构的缺点。
单链表的插入:
假设存储元素e的节点为s,那实现节点p、p->next和s之间的逻辑关系的变化,只需要将节点s插入到节点p和节点p->next之间即可。如下图所示,单链表的插入根本不需要惊动其他节点,只需要让s->next和p->next 指针做一点改变即可。
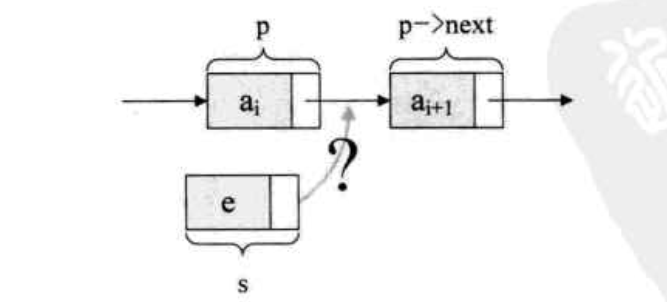
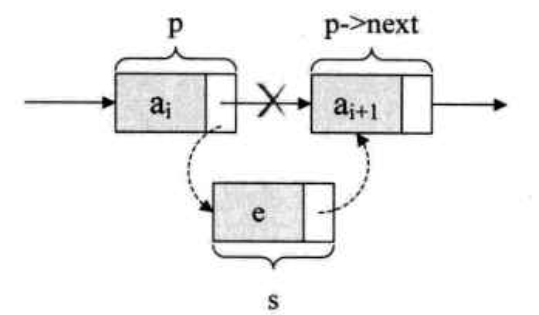
s->next = p-> next; p->next = s;
解读这两句话,就是让p的后继节点改成s的后继节点,再把节点s变成p的后继节点,如下图:
单链表第i个数据插入节点的算法思路:
1、声明一个节点p指向链表的第一个节点,初始化j从1开始;
2、当 j<i 时,就遍历链表,让p的指针向后移动,不断指向下一个节点,j累加1;
3、若到链表末尾p为空,则说明第i个元素不存在;
4、否则查找成功,在系统中生成一个空节点s;
5、将数据元素e 赋值给 s->next;
6、单链表插入的标准语句:s->next = p-> next; p->next = s;
7、返回成功。
思考:上面两句节点操作语句是否可以交换顺序?
如果先 p->next = s; 再 s->next = - ->next;会怎么样?因为第一句会使得将p->next给覆盖成s的地址了。那么s->next = p->next,其实就等于s->next = s;这样真正的拥有的a<i+1> 数据元素的结点就没有了上级。这样的插入操作就是失败的。需要注意
单链表的删除:
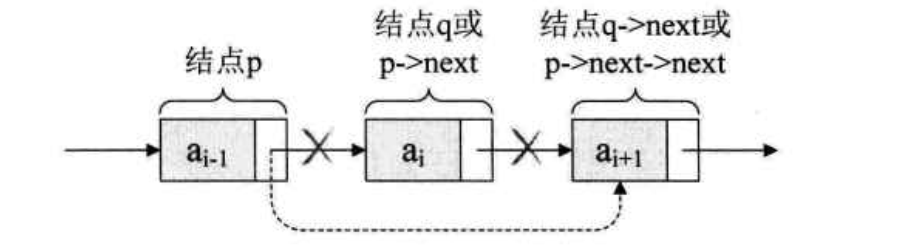
删除的过程中,我们要做的,其实就是一步,p->next = p->next->next, 用q来取代 p->next, 即:
q=p->next; p->next = q->next;
解读这段代码,也就是说让p的后继的后继结点改成p的后继结点。
举个例子,爸爸的左手牵着妈妈的手,右手牵着宝宝的手在散步。突然迎面来了一个美女,爸爸一下子看呆了,此情此景被妈妈逮了个正着,于是她甩开牵着爸爸的手,绕过他,扯开父子俩,拉起宝宝的手就超前走去。妈妈是P节点,妈妈的后继节点是爸爸p->next,也可以叫做q节点。妈妈的后继的后继节点是儿子:p->next ->next,即q->next;当妈妈去牵儿子的手时,这个爸爸就已经与母子两没有任何关系了。如下图:
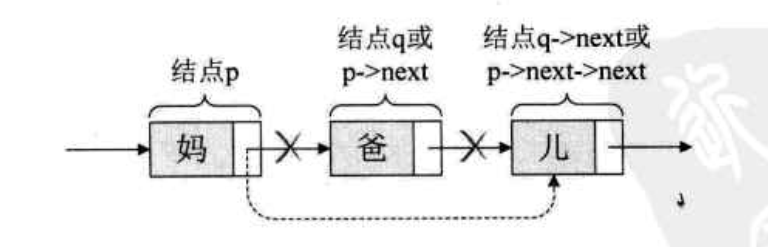
单链表第i个数据删除的算法思路:
1、声明一个节点p指向链表的第一个节点,初始化j从1开始;
2、当 j<i 时,就遍历链表,让p的指针向后移动,不断指向下一个节点,j累加1;
3、若到链表末尾p为空,则说明第i个元素不存在;
4、否则查找成功,将欲删除的节点 p->next 赋值给q;
5、单链表的删除标准语句为 p->next = q->next;
6、将q节点中的数据赋值给e,作为返回;
7、释放q节点,返回成功;
单链表的读取:
线性表顺序存储结构中,我们要查询任意的存储位置都很容易。但在单链表中,由于第i个元素到底在哪?没有办法一开始就知道,必须从头开始找。说白了就是从头开始找,直到找到第i个元素为止。由于这个算法的时间复杂度取决于i的位置,当 i = 1时,则不需要遍历,第一个就取出数据了;而当 i =n 时则遍历n-1次才可以。这是时间复杂度。
由于单链表的结构没有定义表长,所以事先不能直到要循环多少次,因此也就不方便for来循环控制,其核心思想就是 “工作指针后移”,很麻烦。如果仅仅只是读取,链表还不如线性表的顺序存储结构效率高呢!
二、HashSet底层解读:
JDK的API上说,此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
为什么呢?下面看看源码去一探究竟吧。
HashSet的成员变量:
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
add方法添加元素:直接将元素存储到map中。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
remove方法:直接将map中对应的元素移除。
public boolean remove(Object o) { return map.remove(o)==PRESENT; }
isEmpty方法:
public boolean isEmpty() {
return map.isEmpty();
}
remove方法:
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
iterator方法:
public Iterator<E> iterator() {
return map.keySet().iterator();
}
现在回忆一下常见的面试题:
1、HashSet集合是否有重复元素? (不可以,因为HashMap的key不可以重复)
2、HashSet集合是否可以有null?(可以,因为HashMap的key可以有一个null)
3、HashSet元素是否有序? (无序,因为HashMap的key无序)
以上这些就是我们常用的HashSet方法了吧,有没有觉得好简单,读到这些代码,有没有觉得信心爆棚,此刻是不是膨胀了? jdk源码原来so easy,哈哈!
三、HashMap底层实现
之前是逗你玩呢,还真以为JDK有这么简单啊,要是都这样的级别,那java岂不是人人都可以成为大神了?收拾收拾心情,回来继续学习,现在进入JDK的入门代码继续研究吧!
认识一下HashMap结构图吧:
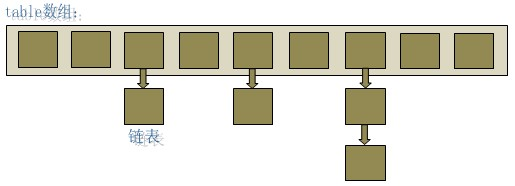
再看HashMap的内部类Entry<K,V>,这个类是全文的中心点:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
这个类是干什么的呢?简单点说,HashMap里面保存的数据最底层是一个Entry型的数组,这个Entry则保留了一个键值对,还有一个指向下一个Entry的指针。所以HashMap是一种结合了数组和链表的结构。
大家调测代码的时候,是不是根据一个功能逐步的去跟踪代码呢?现在我们也按照这个思路去逐步分解HashMap方法吧?
先看看put方法:
public V put(K key, V value) {
//当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key.hashCode());
//计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length);
//从i出开始迭代 e,找到 key 保存的位置
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//1、判断该条链上是否有相同的hash值并且key相同,那么此处直接找到table数组修改对应的e原始value值
//2、如果此处hash值不同,则直接添加数组tablle
//3、如果此处hash值相同,但是key不同。那么找到数组下标就有可能重复,那么此时table数组的同一个下标处就会存储多个元素,它们是以链表形式存储
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
}
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
}
代码分解:int hash = hash(key);这个方法是根据key生成一个hash值。两个对象的存储地址不同也有可能得到相同的hashcode值,虽然这种概率极小,但还是有这样的几率存在的;因此,hash值也有可能重复的
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
代码分解:int i = indexFor(hash, table.length);这个就是在table数组中返回一个下标索引,table是一个Entry<K,V>[]数组
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
进入主程序:
1、我们在使用put添加元素的时候,HashMap一开始是没有key的,因此也不存在key,table数组也不可能存在数据。put的方法会进入到addEntry(hash, key, value, i)方法中
2、addEntry一开始,也只是进入createEntry方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
这个方法中有两点需要注意:
一是链的产生。这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。
二、扩容问题。
随着HashMap中元素的数量越来越多,发生碰撞的概率就越来越大,所产生的链表长度就会越来越长,这样势必会影响HashMap的速度,为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理。该临界点在当HashMap中元素的数量等于table数组长度*加载因子。但是扩容是一个非常耗时的过程,因为它需要重新计算这些数据在新table数组中的位置并进行复制处理。所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
3、进入createEntry方法:
void createEntry(int hash, K key, V value, int bucketIndex) {
// 获取指定 bucketIndex 索引处的 Entry
Entry<K,V> e = table[bucketIndex];
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<>(hash, key, value, e);
//记录HashMap的长度
size++;
}
其实,我们根据这一条线可以发现,内部类Entry的构造方法,最后一个参数e,居然对应的是next,这不就是链表的后继节点吗?
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
那么,第一次put的过程,我是不是可以这样理解:
a>、首先判断key是否为null,若为null,则直接调用putForNullKey方法
b>、然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则通过比较是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链头(最先保存的元素放在链尾)。若table在该处没有元素,则直接保存。
那么,如果同一个key、value进行第二次put怎么办呢?
仔细看看put方法,我们看到了下面这段代码,包含在put方法中的if语句块:
//从i出开始迭代 e,找到 key 保存的位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value,这里并没有处理key,这就解释了HashMap中没有两个相同的key
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
get方法解读:
先认识一下get(key)方法的源码:
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
//在本文的一开始,我就贴出了Entry<K,V>源码,getValue()方法就是返回map中的value,可以自己去本文开始的地方看
return null == entry ? null : entry.getValue();
}
里面涉及到了getEntry(key)方法:这个方法,其实就是根据key生成的下标,到table数组中获取Entry<K,V> e值并返回
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
size()方法:
这个size在createEntry方法方法中已经说明过了
public int size() {
return size;
}
entryKey()、keySet()、values()方法解读:
篇幅有限,其他方法留给自己去解读吧!
这边我就重点说一下entryKey这个方法,keySet和values方法的原理与它都是一样的。
HashMap里面保存的数据最底层是一个Entry型的数组,这个Entry则保留了一个键值对,还有一个指向下一个Entry的指针。所以HashMap是一种结合了数组和链表的结构。通过JDK的api文档我们也知道,entryKey()方法返回的是Set<Map.Entry<K,V>>的类型,因此我们可以通过迭代器遍历出key/value键值对了,那么底层究竟值怎么做的呢?
源码解读:
//一级方法,未做任何逻辑判断,直接对entrySet0方法进行调用
public Set<Map.Entry<K,V>> entrySet() {
return entrySet0();
}
//此方法知识返回一个Set<Map.Entry<K,V>>类型的es,。从方法中我们知道,entrySet有可能是一个默认值,也有可能是通过(entrySet = new EntrySet())方法生成的
private Set<Map.Entry<K,V>> entrySet0() {
//直接点击entry方法进去查看,发现是抽象类HashIterator<E>中的private transient Set<Map.Entry<K,V>> entrySet = null;其中并未中任何的初始化
Set<Map.Entry<K,V>> es = entrySet;
//因此,我判断第一次调用entrySet()方法的时候,是通过new方法生成的,下面去查看EntrySet类的源码
return es != null ? es : (entrySet = new EntrySet());
}
//EntrySet类型只有一个默认的构造方法,并且继承了AbstractSet<Map.Entry<K,V>>抽象类,跟进去以后发现:
//AbstractSet<E> extends AbstractCollection<E> implements Set<E>是一个继承了Set接口,那么最终EntrySet自然也就是一个Set类型的实现类了,并且它重新了Set接口的几个方法,
//源码如下,这样的话我们调用entrySet()方法的时候,其实就是返回了实现Set接口的EntrySet的一个实例,并且这个实例重新了Set接口的方法,尤其是iterator()方法
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return newEntryIterator();
}
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> e = (Map.Entry<K,V>) o;
Entry<K,V> candidate = getEntry(e.getKey());
return candidate != null && candidate.equals(e);
}
public boolean remove(Object o) {
return removeMapping(o) != null;
}
public int size() {
return size;
}
public void clear() {
HashMap.this.clear();
}
}
我们平时用entrySet()遍历map,一般都是这样做的:
HashMap map = new HashMap();
map.put("j1", "k1");
map.put("j1", "k2");
map.put("j3", "k3");
Set<Map.Entry<String,String>> set = map.entrySet();
for(Iterator iter = set.iterator(); iter.hasNext();)
{
Map.Entry<String,String> entry = (Entry<String, String>) iter.next();
System.out.println("key :" + entry.getKey() + " , value : " + entry.getValue());
}
而此处使用set的迭代器方法iterator,此时的set是EntrySet的一个实例,因此此处的iterator()方法具体实现为:
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return newEntryIterator();
}
...........
跟进去newEntryIterator()方法:
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
再次跟进EntryIterator类的实例:发现原来是重写了next()方法
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
那么我们继续跟进nextEntry()方法:
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
至此,我们发现,原来我们在自己的代码中调用iterator()方法,最终在底层返回的是Entry<K,V> e类的实例。返回的接口并没有实例化需要返回的参数,而是在调用返回的set实例的iterator()方法才初始化需要返回的Entry<K,V>类型,而我在本文一开始的地方,就将Entry<K,V>类源码就贴出来了,细心的朋友可以能已经发现,此类已经提供了直接返回key、value的方法了,因此我们可以直接调用。
一个不得不说的方法,remove(Key)方法:
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
这个方法没干什么事情,只是简单的调用了removeEntryForKey(Key)方法了,下面看看这个方法干了什么事情:
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
这个方法我最想提起的是上面标红的部分: Entry<K,V> prev = table[i];Entry<K,V> e = prev; 那下面再判断 if (prev == e){ table[i] = next; }有意思吗?请大家思考,这个地方判断有意思吗?有意义吗?
这个地方,一开始我也不是很明白,感觉这不就是一个指针么,实例e指向了prev了,那么prev == e这个逻辑应该是恒成立的才对呀?
其实,因为HashMap的底层实现是链表,而链表的插入和删除的实现思路,在上面的说链表的时候已经提起了,这里需要指出的是Entry<K,V> prev = table[i];这其实是table数组的一个元素而已,但是这个元素本身底层却是一个Entry<Key,Value>类型的链表,也就是说可能有很多元素。那么我们在定义一个节点Entry<K,V> e = prev 指向perv,其实只是指向prev链表的第一个节点;如果prev == e,那就说明此处的链表仅有一个节点,而且这个节点没有后继节点。否则,prev肯定不等于e。