1数据源 :上次关于手机流量简单统计业务的product
2.要求 :根据总流量得值进行倒序排序,然后得到输出
3.大概逻辑
(1)FlowSort 类:进行序列化和反序列化,排序逻辑接口实现
(2)FlowSortMapper 类:对数据进行封装
(3)FlowSortReducer类:将key和value进行对调然后封装写入(对调位置是因为只有key(形参)是可以排序的,value就不行)
(4)FlowSortDriver类; 进行driver操作(在代码下面有具体注释) 这里会把输出类型的时候把k和value对调回来
4.代码
(1)FlowSort
package flowsort;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowSort implements WritableComparable<FlowSort> {
//上flow流量
private long upFlow;
//下flow流量
private long downFlow;
//sum流量
private long sumFlow;
//空参构造
public FlowSort() {
}
@Override
public String toString() {
return upFlow +" "
+downFlow +" "+
sumFlow
;
}
//序列化方法
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//反序列化方法
public void readFields(DataInput in) throws IOException {
this.upFlow=in.readLong();
this.downFlow=in.readLong();
this.sumFlow=in.readLong();
}
//排序逻辑
public int compareTo(FlowSort o) {
int result=0;
if (sumFlow>o.getSumFlow()) {
result = -1;
}else if (sumFlow<o.getSumFlow()){
result=1;
}else{
result=0; }
return result;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
}
(2)FlowSortMapper
package flowsort;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowSortMapper extends Mapper<LongWritable, Text,FlowSort,Text> {
Text k = new Text();
FlowSort v = new FlowSort();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//切割字符串
String[] filds = line.split(" ");
//封装对象
//封装key
String phonenumber = filds[0];
//获取上行流量
long upflow=Long.parseLong(filds[1]);
//获取下行流量
long downflow=Long.parseLong(filds[2]);
//获取总流量
long sumflow=Long.parseLong(filds[3]);
k.set(phonenumber);
v.setUpFlow(upflow);
v.setDownFlow(downflow);
v.setSumFlow(sumflow);
//写出
context.write(v,k);
}
}
(3)FlowSortReducer
package flowsort;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowSortReducer extends Reducer<FlowSort, Text,Text,FlowSort> {
@Override
protected void reduce(FlowSort key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text phoneNumber : values) {
context.write(phoneNumber,key);
}
}
}
(4)FlowSortdriver
package flowsort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowSortDrivers {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//0 封装输入输出路径
args =new String[]{"C:/Users/input","C:/Users/output"};
System.setProperty("hadoop.home.dir","E:/hadoop-2.7.2/");
//获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置jar加载路径
job.setJarByClass(FlowSortDrivers.class);
//关联mapper和reducer
job.setMapperClass(FlowSortMapper.class);
job.setReducerClass(FlowSortReducer.class);
//设置map最终输出类型
job.setMapOutputKeyClass(FlowSort.class);
job.setMapOutputValueClass(Text.class);
//设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowSort.class);
//设置输入路劲
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
5.结果
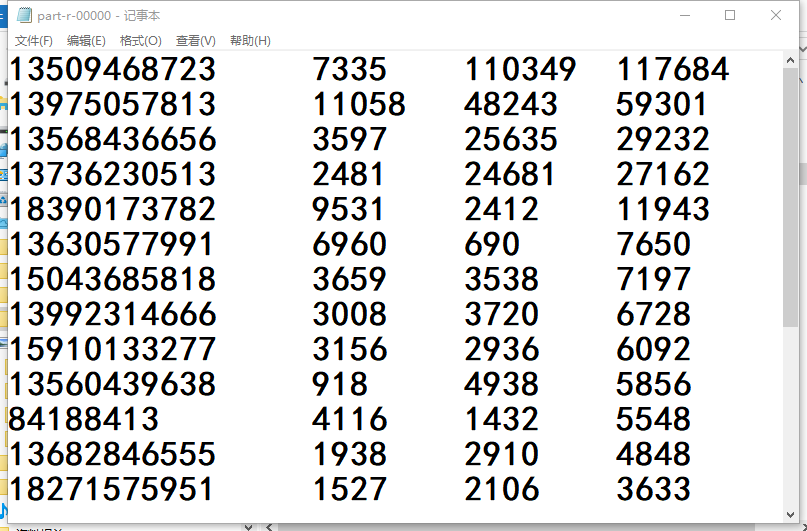
6. 我的error:路径没问题,但是job对象没执行完,ouput没有内容
(1)导错包,这真的是致命
(2)函数名打错。。。。。
哦,希望以后不要犯这些低级错误(小声嘀咕:以后肯定还会再犯的*3)
2020-05-26
21:30:13
FlowSort