链接:https://www.zhihu.com/question/19729973/answer/433057897
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在数据结构中经常有人说堆栈,堆栈之间有什么区别了?这些数据结构在算法思想中有哪些良好的运用了?
首先我们平常端盘子,都是知道盘子一般都是一个个堆叠起来的,而我们把盘子比作数据,而堆起来的盘子就很像栈这种数据结构。
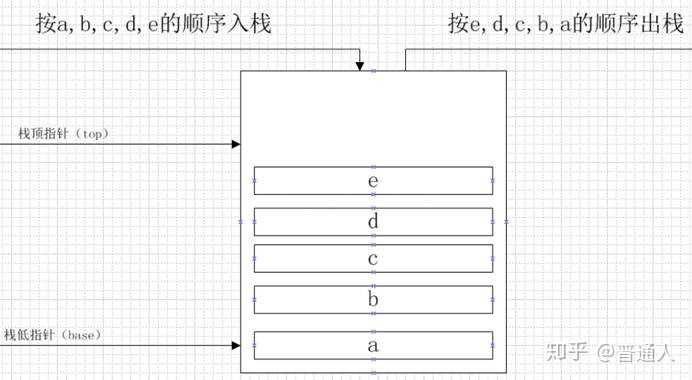

先进后出的这种结构,就是栈的数据结构,我们存数据时先存a,b,c,d,e 之后取e,d,c,b,a。
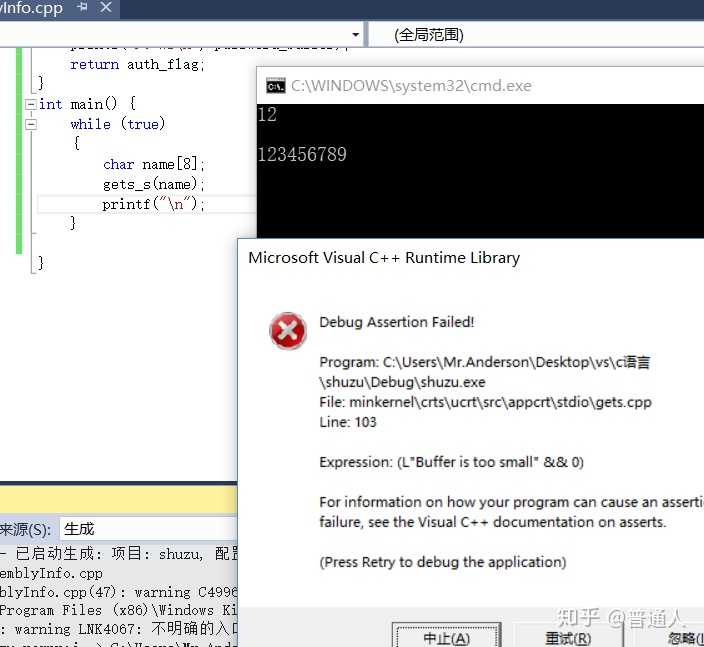
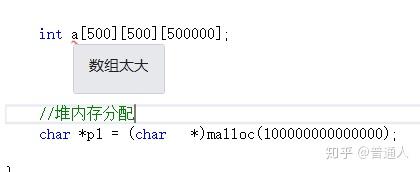
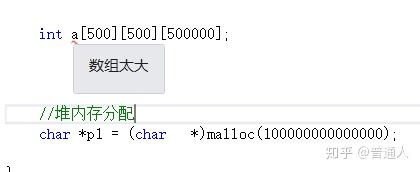
同样的堆也是一类特殊的数据结构,和栈有所不同的是,堆的内存是由所在语言系统环境管理的(比如python虚拟机)而栈申请内存时是由系统自动分配的,而且系统分配也是大小限制的,超过这个大小后就会内存溢出报错,类似如下定义的字符溢出。
而堆内存是一般是由语言运行环境分配管理,如Python虚拟机控制内存和运行环境:

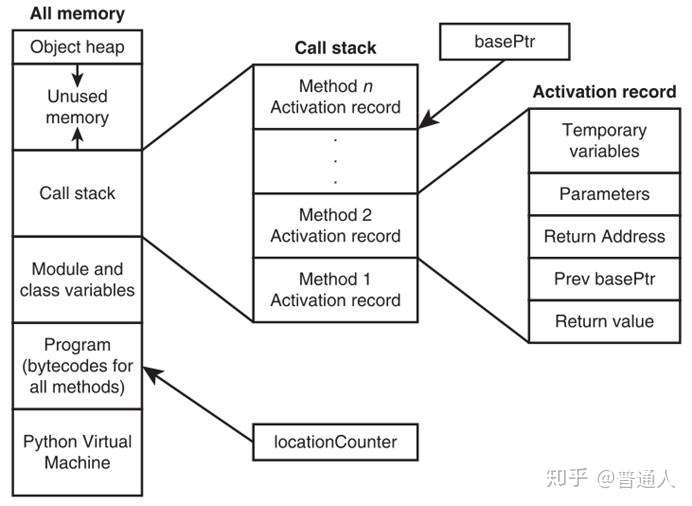
所以内存上可以组合关联起来,这样就不容易受系统限制
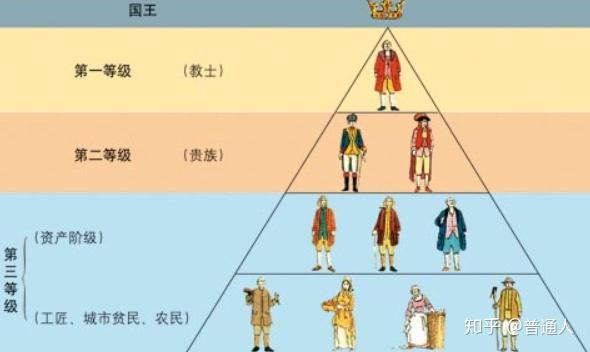
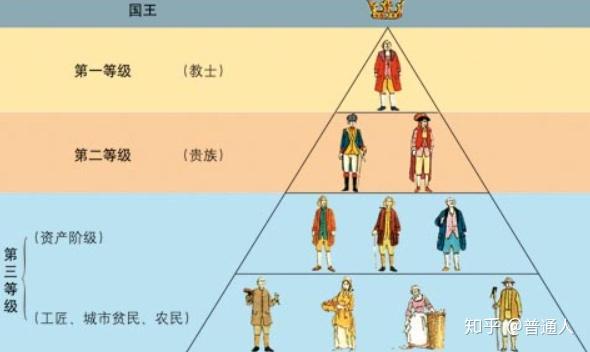
堆在数据存取上和栈有所不同,栈是先进后出,而堆是一种优先的队列(并不是队列,堆通常是一个可以被看做一棵树的数组对象。),所谓优先队列是按照元素的优先级取出元素。举个例子,一般在饭桌上,无论你是先来后到,应该先是爷爷奶奶辈先动筷子,后面是父母,之后是你,像这种:
有这样的优先级享受的,其严格的逻辑数据结构定义如下:


有了这定义我们来尝试一下用堆这种数据结构做一种排序叫堆排序,我们先得到需要排序的一组元素:
16,7,3,20,17,8
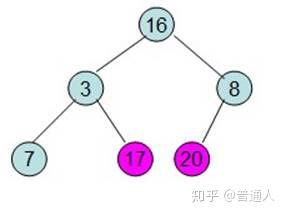
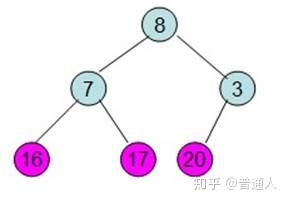
先构建一颗树:
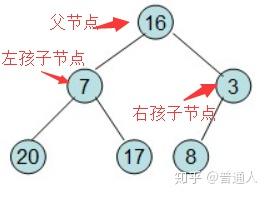
按照堆数据结构的定义,即任何一非叶节点的数据不大于或者不小于其左右孩子节点的数据
,调整如下:
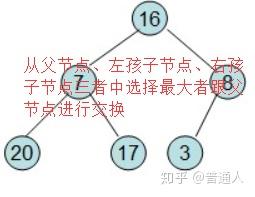
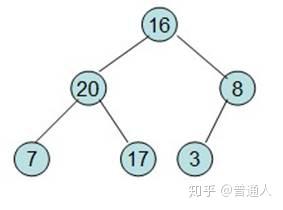
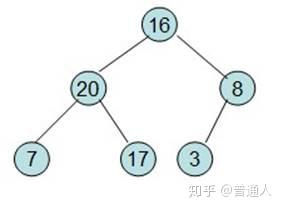

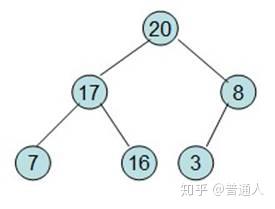
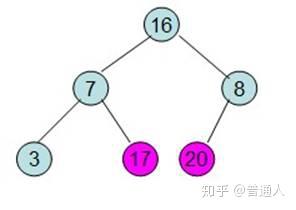
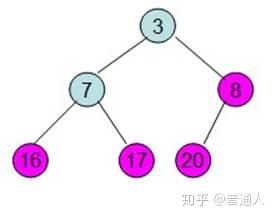
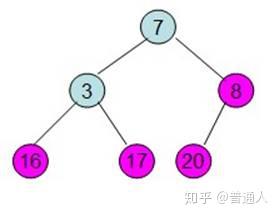
直到调整如上,就表示最大的在最上面,下面每个子节点都比父节点小,堆就完成了初始化。现在要对堆进行排序(注意),我们希望从左到右,按照从小到大的顺序排列,依照堆的性质,我们可以这样排:
首先我们将最大的和最后一个位置进行交换
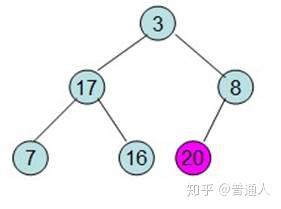
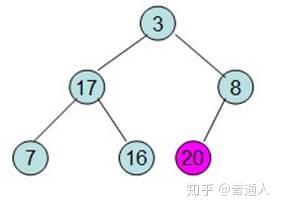
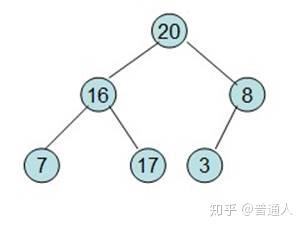
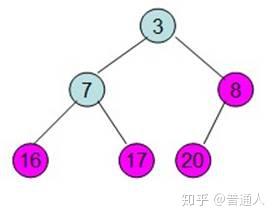
除了红色标记的元素,其他数据按照堆的性质从新排列好。
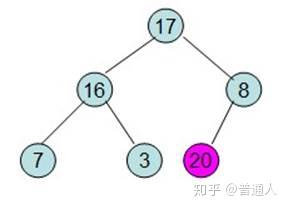
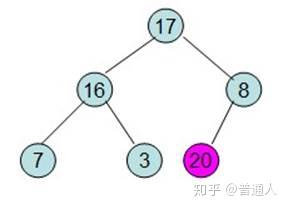
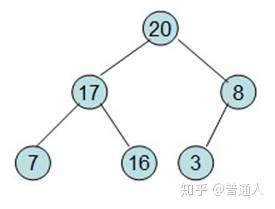
继续将除红色标记外的最大元素移到最后面
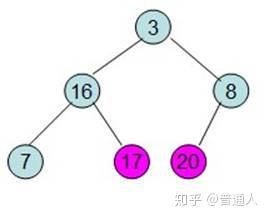
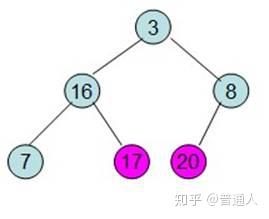
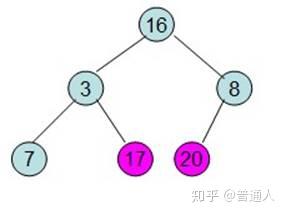

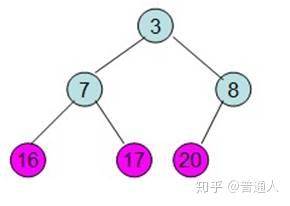
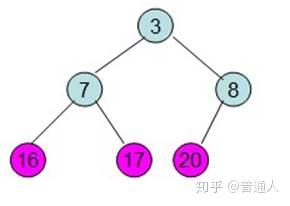

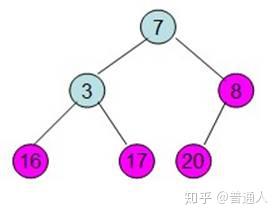

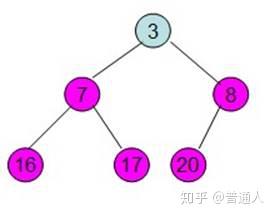
一直到只剩根节点时,这个时候排序就已经排好了,以上就是利用数据结构堆做的排序算法。我们用Python代码实现如下:
def heap_sort(lst):
def sift_down(start, end):
"""最大堆调整"""
root = start
while True:
child = 2 * root + 1
if child > end:
break
if child + 1 <= end and lst[child] < lst[child + 1]:
child += 1
if lst[root] < lst[child]:
lst[root], lst[child] = lst[child], lst[root]
root = child
else:
break
# 创建最大堆
for start in range((len(lst) - 2) // 2, -1, -1):
sift_down(start, len(lst) - 1)
# 堆排序
for end in range(len(lst) - 1, 0, -1):
lst[0], lst[end] = lst[end], lst[0]
sift_down(0, end - 1)
return lst
if __name__ == "__main__":
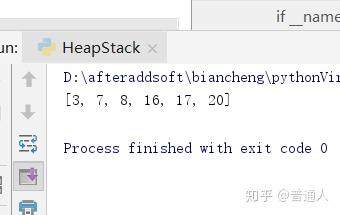
list = [16,7,3,20,17,8]
heap_sort(list)
print(list)
运行结果:
计算复杂度后我们发现堆排序也是比较优秀的一种排序,那栈了,其实这里突然想起一件事,就是学维特比算法时有个马尔科夫链,其中就包含了回溯算法,网上搜索发现栈这种数据结构正好对应这种算法思想,我们写个实际的例子来看看,首先我们看看,什么是回溯了,我举个例子。
如下图,现在有一只小蚂蚁P要在迷宫中找食物T,找的方式如下,我们把每个岔路口当成一个节点,记录下来,假设蚂蚁从节点1出发,沿着2、3、4都是死路,于是返回节点1,这个返回的过程就是回溯,当到达节点5时,往上碰壁返回来(回溯),左右碰壁回来(回溯),只有往下才找到食物,这个过程就是回溯算法体现。
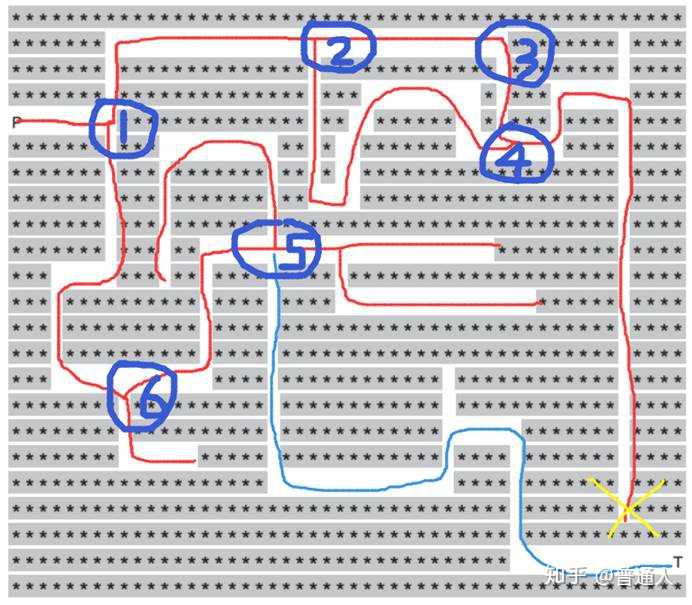
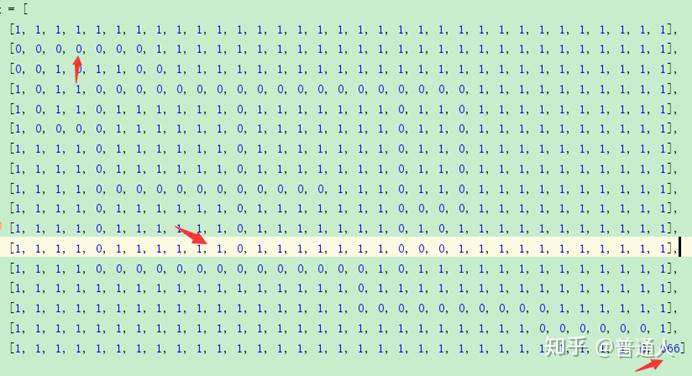
为了方便代码实现,我们用1表示墙,0表示可以走的地方,666表示食物,矩阵表示整个迷宫:

想法和思路是这样:
1、将小蚂蚁走过的分岔路口记录下来
2、将小蚂蚁走过的路径记录记录下来(用栈这种数据结构)
3、当小蚂蚁发现这条路不通时,或者遇到相同的岔路口时,延原路返回(路径数据取出栈的数据)当回到岔路口时,将岔路口那个方向路不通的数据标记,延没有标记的方向继续前进(如果都标记了,继续延原路返回),直到找到食物。
具体的实现代码我就不贴出来了,这就是栈这种数据结构在回溯算法上的应用。
哈哈哈,折腾了一天希望有大佬能指出错误,共同进步。
参考书籍:
算法导论原书第三版
Python数据结构