gcc编译链接分解:
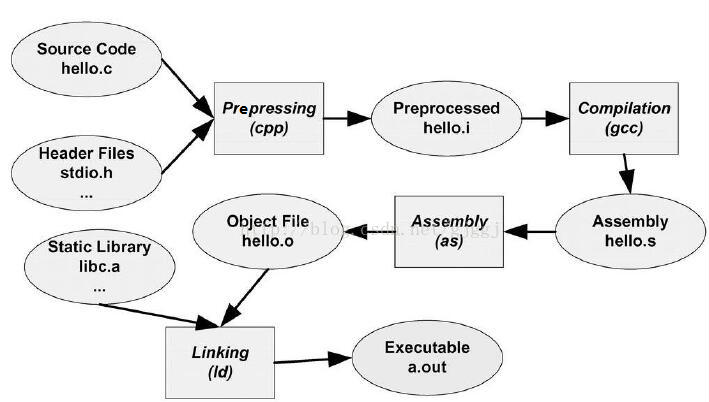
主要过程为:
预处理(preprocess) -----> 编译(compilation) --------> 汇编(assembly) ------> 链接(linking)
gcc指令:
-E:表示只执行预处理(preprocess)
-S:执行预处理和编译
-o:表示输出文件
-c:表示预处理,编译和汇编操作
-g:输出文件可让gdb调试
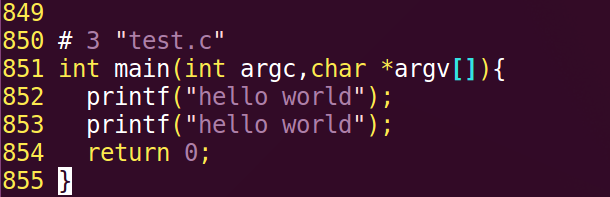
例子(test.c):
#include <stdio.h> #define print(a) printf(#a) int main(int argc,char argv*[]){ print(hello world); printf("hello world"); //printf function return 0; }
预处理:

然后生成的test.i内容:
一大堆的的变量定义和函数声明以及放在最后的我们编写的代码(在vim中使用shift+g跳转到最后)
实际上前面的一大段代码就是stdio.h头文件内容,预处理会将我们包含的头文件以递归操作将其展开,并且预处理会删除我们所有注释
预处理主要范围:
- 展开所有的宏定义并删除 #define (见例子)
- 处理所有的条件编译指令,例如 #if #else #endif #ifndef …,这就帮助我们观察宏定义是否正确
- 把所有的 #include 替换为头文件实际内容,递归进行(见例子)
- 把所有的注释 // 和 / / 替换为空格(见例子)
- 添加行号和文件名标识以供编译器使用
- 保留所有的 #pragma 指令,因为编译器要使用
gcc其实并不要求函数一定要在被调用之前定义或者声明(MSVC不允许),因为gcc在处理到某个未知类型的函数时,会为其创建一个隐式声明,并假设该函数返回值类型为int。但gcc此时无法检查传递给该函数的实参类型和个数是否正确,不利于编译器为我们排除错误(而且如果该函数的返回值不是int的话也会出错)。
编译:
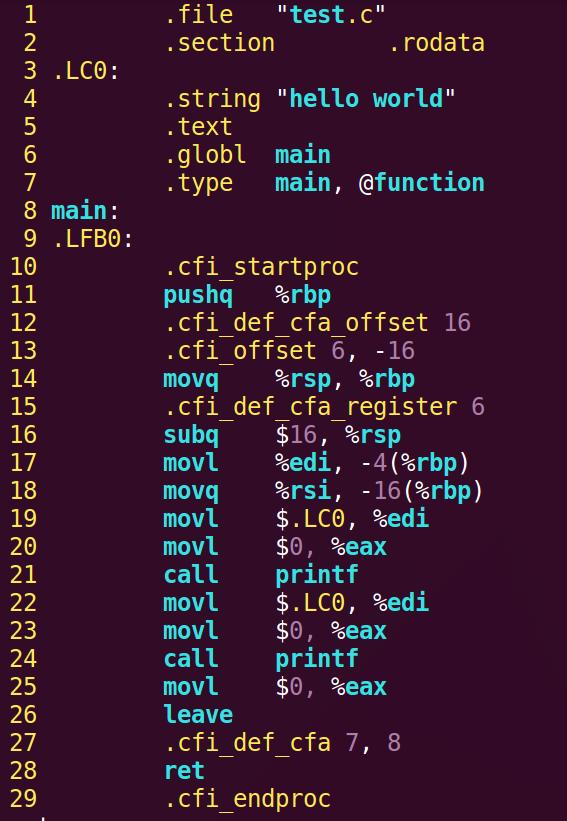
编译就是把预处理之后的文件进行一系列词法分析、语法分析、语义分析以及优化后生成的相应汇编代码文件
 (在命令行加上参数 -masm=intel ,这样gcc就会生成Intel风格的汇编代码了)
(在命令行加上参数 -masm=intel ,这样gcc就会生成Intel风格的汇编代码了)
生成AT&T语法的test.s汇编文件
汇编:
把编译生成的汇编代码生成机器码

test.o(很恐怖)
不同的操作系统之间的可执行文件的格式通常是不一样的,所以造成了编译好的HelloWorld没有办法直接复制执行,而需要在相关平台上重新编译,当然了,不能运行的原因自然不是这一点点,不同的操作系统接口(windows API和Linux的System Call)以及相关的类库不同也是原因之一。
链接:
链接(linking)是将各种代码和数据部分收集起来并组合成为一个单一文件的过程,这个文件可被加载(或被拷贝)到存储器并执行。
链接可以执行于编译时(compile time),也就是在源代码被翻译成机器代码时;也可以执行于加载时,也就是在程序被加载器(loader)加载到存储器并执行时;甚至执行于运行时(run time),由应用程序来执行
任何一个程序,它的背后都有一套庞大的代码在支撑着它,以使得该程序能够正常运行。这套代码至少包括入口函数、以及其所依赖的函数构成的函数集合。当然,它还包含了各种标准库函数的实现。这个“支撑模块”就叫做运行时库(Runtime Library)。而C语言的运行库,即被称为C运行时库(CRT)。
CRT大致包括:启动与退出相关的代码(包括入口函数及入口函数所依赖的其他函数)、标准库函数(ANSI C标准规定的函数实现)、I/O相关、堆的封装实现、语言特殊功能的实现以及调试相关。其中标准库函数的实现占据了主要地位。例如printf,scanf函数就是标准库函数的成员。C语言标准库在不同的平台上实现了不同的版本,我们只要依赖其接口定义,就能保证程序在不同平台上的一致行为。
C语言提供了标准库函数供我们使用,那么以什么形式提供呢?
我们几乎每一次写程序都难免去使用库函数,每一次去编译标准库源代码太麻烦了。于是就事先把标准库函数提前编译好,需要的时候直接链接。
标准库以什么形式存在呢?一个目标文件?
我们知道,链接的最小单位就是一个个目标文件,如果我们只用到一个printf函数,就需要和整个库链接的话岂不是太浪费资源了么?但是,如果把库函数分别定义在彼此独立的代码文件里,这样编译出来的可是一大堆目标文件,有点混乱。
1.静态链接库
编辑器系统提供了一种机制,将所有的编译出来(按照库函数编译)的目标文件打包成一个单独的文件,叫做静态库(static library)。当链接器和静态库链接的时候,链接器会从这个打包的文件中“解压缩”出需要的部分目标文件进行链接,这就减少了资源浪费
Linux/Unix系统下ANSI C的库名叫做libc.a,另外数学函数单独在libm.a库里。静态库采用一种称为存档(archive)的特殊文件格式来保存。其实就是一个目标文件的集合,文件头描述了每个成员目标文件的位置和大小。
自制静态库:
// swap.c void swap(int *num1, int *num2) { int tmp = *num1; *num1 = *num2; *num2 = tmp; } // add.c int add(int a, int b) { return a + b; } // calc.h #ifndef CALC_H_ #define CALC_H_ #ifdef _cplusplus extern "C" { #endif void swap(int *, int *); int add(int, int); #ifdef _cplusplus } #endif #endif // CALC_H_
C++语言在编译的时候为了解决函数的多态问题,会将函数名和参数联合起来生成一个中间的函数名称,而C语言则不会,因此会造成链接时找不到对应函数的情况,此时C函数就需要用extern “C”进行链接指定,这告诉编译器,请保持我的名称,不要给我生成用于链接的中间函数名。extern "C"指令仅指定编译和连接规约,但不影响语义。例如在函数声明中,指定了extern "C",仍然要遵守C++的类型检测、参数转换规则。
我们分别编译它们得到了swap.o和add.o这两个目标文件,最后使用ar命令将其打包为一个静态库。
使用swap和add函数:
//calc.c
#include <stdio.h> #include <stdlib.h> #include "calc.h" int main(int argc, char *argv[]) { int a = 1, b = 2; swap(&a, &b); printf("%d %d ", a, b); return EXIT_SUCCESS; }
步骤为:
 ps.这里将swap.o和add.o目标文件打包成libcalc.a静态库
ps.这里将swap.o和add.o目标文件打包成libcalc.a静态库
最终运行为:

我们使用C语言标准库的时候,编译并不需要加什么库名,那是因为标准库已经是标准了,所以会被默认链接。
缺点:
每一个使用了相同的C标准函数的程序都需要和相关目标文件进行链接,浪费磁盘空间;当一个程序有多个副本执行时,相同的库代码部分被载入内存,浪费内存;当库代码更新之后,使用这些库的函数必须全部重新编译生成目标文件……
2.为此引入动态链接库:
动态链接库/共享库是一个目标模块,在运行时可以加载到任意的存储器地址,并和一个正在运行的程序链接起来。这个过程就是动态链接(dynamic linking),是由一个叫做动态链接器(dynamic linker)的程序完成的。Unix/Linux中共享库的后缀名通常是.so,window为dll文件。
建立一个动态链接库:
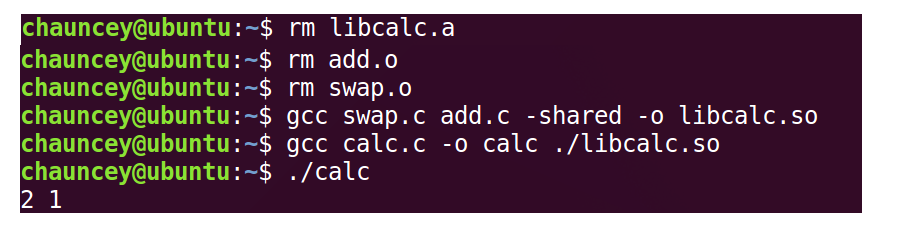
把上面ar命令改成gcc swap.c add.c -shared -o libcalc.so 即可
之后执行gcc test.c -o test ./libcalc.so
用ldd(ldd是我们在上篇中推荐的GNU binutils工具包的组成之一)分析动态链接文件的依赖:

在gcc编译的命令行加上 -static 可以要求静态链接
好处:
①库更新之后,只需要替换掉动态库文件(swap.c,add.c)即可,无需编译所有依赖库的可执行文件。
②程序有多个副本执行时,内存中只需要一份库代码(通过动态链接器链接即可),节省空间。
链接的步骤大致包括了地址和空间分配(Address and Storage Allocation)、符号决议(Symbol Resolution)和重定位(Relocation)等主要步骤。
什么是符号(symbol)?简单说我们在代码中定义的函数和变量可以统称为符号。符号名(symbol name)就是函数名和变量名。
例如:我们调用了printf函数,编译时留下了要填入的函数地址,那么printf函数的实际地址在那呢?这个空位什么时候修正呢?当然是链接的时候,重定位那一步就是做这个的(重定位是将符号引用与符号定义进行连接的过程)。
符号决议:正如前文所说,编译期间留下了很多需要重新定位的符号,所以目标文件中会有一块区域专门保存符号表。那链接器如何知道具体位置呢?其实链接器不知道,所以链接器会搜索全部的待链接的目标文件,寻找这个符号的位置,然后修正每一个符号的地址。
符号查找问题:
1.找不到符号:
当我们声明了一个swap函数却没有定义它的时候,我们调用这个函数的代码可以通过编译,但是在链接期间却会遇到错误。形如“test.c:(.text+0x29): undefined reference to ‘swap’”这样,特别的,MSVC编译器报错是找不到符号_swap。
为什么多了MSVC编译器会多个_?
当C语言刚面世的时候,已经存在不少用汇编语言写好的库了,因为链接器的符号唯一规则,假如该库中存在main函数,我们就不能在C代码中出现main函数了,因为会遭遇符号重定义错误,倘若放弃这些库又是一大损失。所以当时的编译器会对代码中的符号进行修饰(name decoration),C语言的代码会在符号前加下划线,这样各个目标文件就不会同名了,就解决了符号冲突的问题,随着时间的流逝,操作系统和编译器都被重写了好多遍了,当前的这个问题已经可以无视了,而MSVC依旧保留了这个传统,所以我们可以看到_swap这样的修饰。
存在同名符号时链接器如何处理?不是刚刚说了会报告重名错误吗?这不仅仅这么简单,在编译时,编译器会向汇编器输出每个全局符号,分为强(strong)符号和弱(weak)符号,汇编器把这个信息隐含的编码在可重定位目标文件的符号表里。其中函数和已初始化过的全局变量是强符号,未初始化的全局变量是弱符号。根据强弱符号的定义,GNU链接器采用的规则如下:
- 不允许多个强符号
- 如果有一个强符号和一个或多个弱符号,则选择强符号
- 如果有多个弱符号,则随机选择一个
具体例子:
// link1.c #include <stdio.h> int n; int main(int argc, char *argv[]) { printf("It is %d ", n); return 0; } // link2.c int n = 5;
输出为5

同理:
main.c int main(int argc, char*argv[]) { hello(); } hello.c #include <stdio.h> //甚至不 include hello.h void hello() //定义了为强符号,链接时符号选择该处 { puts("hello world"); } hello.h void hello();//只申明弱符号
编译链接,结果hello world
这也就是为什么上面编写静态链接库的时候,void swap(*,*)和定义的swap会结合成一起,定义过的swap为强符号,申明的是弱符号,根据“如果有一个强符号和一个或多个弱符号,则选择强符号”,所以swap就是已经定义的那个
对于宏定义:
#是将单个宏参数转换成一个字符串
##则是将两个宏参数连接在一起
在C宏中称为Variadic Macro,也就是变参宏。比如:
#define myprintf(templt,...) fprintf(stderr,templt,__VA_ARGS__)
// 或者
#define myprintf(templt,args...) fprintf(stderr,templt,args)
第一个宏中由于没有对变参起名,我们用默认的宏__VA_ARGS__来替代它。第二个宏中,我们显式地命名变参为args,那么我们在宏定义中就可以用args来代指变参了,变参必须作为参数表的最后一项出现。
使用时C标准要求我们必须写成:
myprintf(templt,);
的形式
例如:
myprintf("Error!/n",);
替换为:
fprintf(stderr,"Error!/n",);/因为最后逗号出错
C++支持:
myprintf("Error!/n");//没最后逗号
替换为:
fprintf(stderr,"Error!/n",);因为最后逗号出错
当使用##
#define myprintf(templt, ...) fprintf(stderr,templt, ##__VAR_ARGS__)
这时,##这个连接符号充当的作用就是当__VAR_ARGS__为空的时候,消除前面的那个逗号。那么此时的翻译过程如下:
myprintf(templt);
被转化为:
fprintf(stderr,templt);
#if MY_PRINTF_VERSION == 1
void printf1() {
...
}
#elif MY_PRINTF_VERSION == 2
int printf2()
{
...
}
#elsif
int printf3()
{
...
}
#endif
预编译时,当if符合时,编译printf1,逻辑与if ,else if ,else一样。
#include <iostream>
//make function factory and use it
#define FUNCTION(name, a) int fun_##name() { return a;}
FUNCTION(abcd, 12)
FUNCTION(fff, 2)
FUNCTION(qqq, 23)
#undef FUNCTION
#define FUNCTION 34
#define OUTPUT(a) std::cout << #a << '
'
int main()
{
std::cout << "abcd: " << fun_abcd() << '
';
std::cout << "fff: " << fun_fff() << '
';
std::cout << "qqq: " << fun_qqq() << '
';
std::cout << FUNCTION << '
';
OUTPUT(million); // 注意这里没有引号
}
输出:
abcd: 12 fff: 2 qqq: 23 34 million
Done!!!
引用:
http://0xffffff.org/2013/04/17/17-complier-and-linker-2/