前面讲了LeNet、AlexNet和Vgg,这周来讲讲GoogLeNet。GoogLeNet是由google的Christian Szegedy等人在2014年的论文《Going Deeper with Convolutions》提出,其最大的亮点是提出一种叫Inception的结构,以此为基础构建GoogLeNet,并在当年的ImageNet分类和检测任务中获得第一,ps:GoogLeNet的取名是为了向YannLeCun的LeNet系列致敬。
(本系列所有代码均在github:https://github.com/huxiaoman7/PaddlePaddle_code)
关于深度网络的一些思考
在本系列最开始的几篇文章我们讲到了卷积神经网络,设计的网络结构也非常简单,属于浅层神经网络,如三层的卷积神经网络等,但是在层数比较少的时候,有时候效果往往并没有那么好,在实验过程中发现,当我们尝试增加网络的层数,或者增加每一层网络的神经元个数的时候,对准确率有一定的提升,简单的说就是增加网络的深度与宽度,但这样做有两个明显的缺点:
- 更深更宽的网络意味着更多的参数,提高了模型的复杂度,从而大大增加过拟合的风险,尤其在训练数据不是那么多或者某个label训练数据不足的情况下更容易发生;
- 增加计算资源的消耗,实际情况下,不管是因为数据稀疏还是扩充的网络结构利用不充分(比如很多权重接近0),都会导致大量计算的浪费。
解决以上两个问题的基本方法是将全连接或卷积连接改为稀疏连接。不管从生物的角度还是机器学习的角度,稀疏性都有良好的表现,回想一下在讲AlexNet这一节提出的Dropout网络以及ReLU激活函数,其本质就是利用稀疏性提高模型泛化性(但需要计算的参数没变少)。
简单解释下稀疏性,当整个特征空间是非线性甚至不连续时:
- 学好局部空间的特征集更能提升性能,类似于Maxout网络中使用多个局部线性函数的组合来拟合非线性函数的思想;
- 假设整个特征空间由N个不连续局部特征空间集合组成,任意一个样本会被映射到这N个空间中并激活/不激活相应特征维度,如果用C1表示某类样本被激活的特征维度集合,用C2表示另一类样本的特征维度集合,当数据量不够大时,要想增加特征区分度并很好的区分两类样本,就要降低C1和C2的重合度(比如可用Jaccard距离衡量),即缩小C1和C2的大小,意味着相应的特征维度集会变稀疏。
不过尴尬的是,现在的计算机体系结构更善于稠密数据的计算,而在非均匀分布的稀疏数据上的计算效率极差,比如稀疏性会导致的缓存miss率极高,于是需要一种方法既能发挥稀疏网络的优势又能保证计算效率。好在前人做了大量实验(如《On Two-Dimensional Sparse Matrix Partitioning: Models, Methods, and a Recipe》),发现对稀疏矩阵做聚类得到相对稠密的子矩阵可以大幅提高稀疏矩阵乘法性能,借鉴这个思想,作者提出Inception的结构。
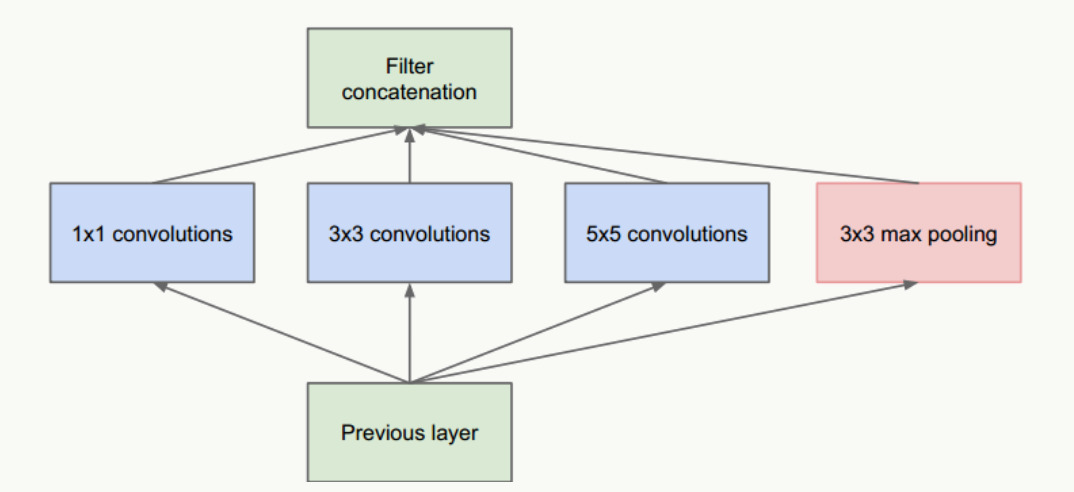
图1 Inception结构
- 把不同大小卷积核抽象得到的特征空间看做子特征空间,每个子特征空间都是稀疏的,把这些不同尺度特征做融合,相当于得到一个相对稠密的空间;
- 采用1×1、3×3、5×5卷积核(不是必须的,也可以是其他大小),stride取1,利用padding可以方便的做输出特征维度对齐;
- 大量事实表明pooling层能有效提高卷积网络的效果,所以加了一条max pooling路径;
- 这个结构符合直观理解,视觉信息通过不同尺度的变换被聚合起来作为下一阶段的特征,比如:人的高矮、胖瘦、青老信息被聚合后做下一步判断。
这个网络的最大问题是5×5卷积带来了巨大计算负担,例如,假设上层输入为:28×28×192:
- 直接经过96个5×5卷积层(stride=1,padding=2)后,输出为:28×28×96,卷积层参数量为:192×5×5×96=460800;
- 借鉴NIN网络(Network in Network,后续会讲),在5×5卷积前使用32个1×1卷积核做维度缩减,变成28×28×32,之后经过96个5×5卷积层(stride=1,padding=2)后,输出为:28×28×96,但所有卷积层的参数量为:192×1×1×32+32×5×5×96=82944,可见整个参数量是原来的1/5.5,且效果上没有多少损失。
新网络结构为

图2 新Inception结构
GoogLeNet网络结构
利用上述Inception模块构建GoogLeNet,实验表明Inception模块出现在高层特征抽象时会更加有效(我理解由于其结构特点,更适合提取高阶特征,让它提取低阶特征会导致特征信息丢失),所以在低层依然使用传统卷积层。整个网路结构如下:
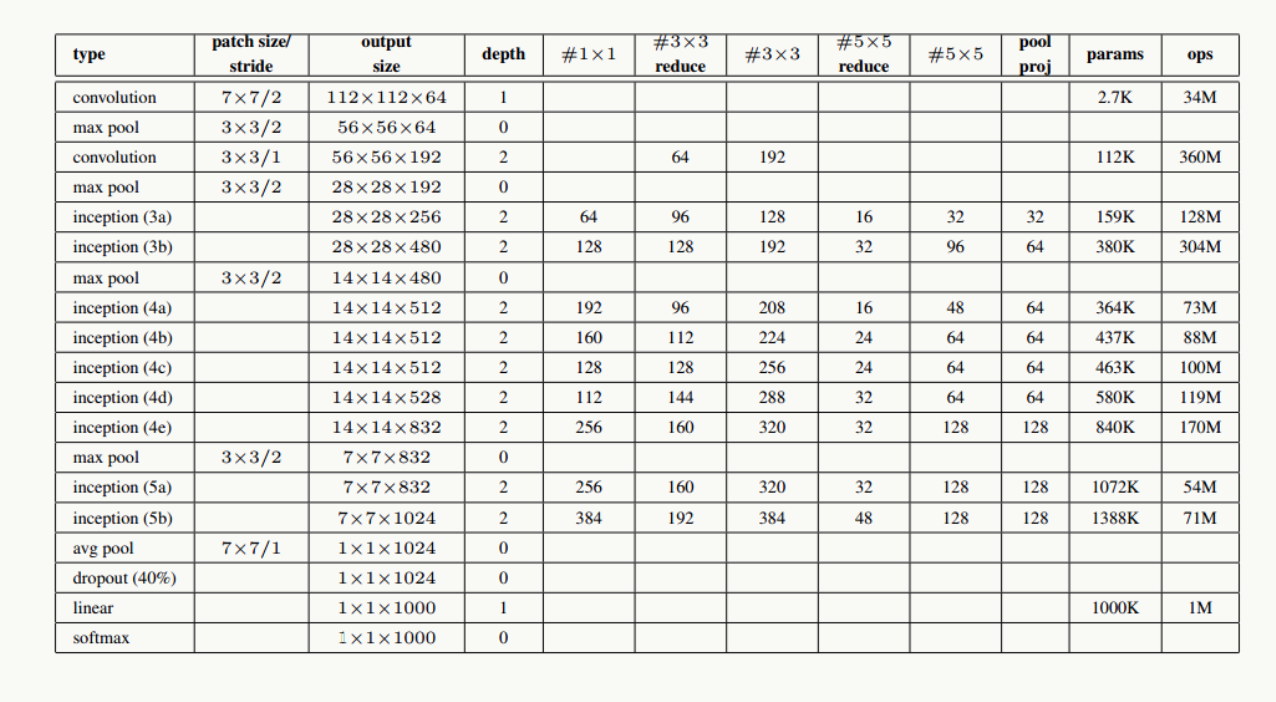
图3 GoogLeNet网络结构

图4 GoogLeNet详细网络结构示意图
网络说明:
- 所有卷积层均使用ReLU激活函数,包括做了1×1卷积降维后的激活;
- 移除全连接层,像NIN一样使用Global Average Pooling,使得Top 1准确率提高0.6%,但由于GAP与类别数目有关系,为了方便大家做模型fine-tuning,最后加了一个全连接层;
- 与前面的ResNet类似,实验观察到,相对浅层的神经网络层对模型效果有较大的贡献,训练阶段通过对Inception(4a、4d)增加两个额外的分类器来增强反向传播时的梯度信号,但最重要的还是正则化作用,这一点在GoogLeNet v3中得到实验证实,并间接证实了GoogLeNet V2中BN的正则化作用,这两个分类器的loss会以0.3的权重加在整体loss上,在模型inference阶段,这两个分类器会被去掉;
- 用于降维的1×1卷积核个数为128个;
- 全连接层使用1024个神经元;
- 使用丢弃概率为0.7的Dropout层;
网络结构详细说明:
输入数据为224×224×3的RGB图像,图中"S"代表做same-padding,"V"代表不做。
- C1卷积层:64个7×7卷积核(stride=2,padding=3),输出为:112×112×64;
- P1抽样层:64个3×3卷积核(stride=2),输出为56×56×64,其中:56=(112-3+1)/2+1
- C2卷积层:192个3×3卷积核(stride=1,padding=1),输出为:56×56×192;
- P2抽样层:192个3×3卷积核(stride=2),输出为28×28×192,其中:28=(56-3+1)/2+1,接着数据被分出4个分支,进入Inception (3a)
- Inception (3a):由4部分组成
- 64个1×1的卷积核,输出为28×28×64;
- 96个1×1的卷积核做降维,输出为28×28×96,之后128个3×3卷积核(stride=1,padding=1),输出为:28×28×128
- 16个1×1的卷积核做降维,输出为28×28×16,之后32个5×5卷积核(stride=1,padding=2),输出为:28×28×32
- 192个3×3卷积核(stride=1,padding=1),输出为28×28×192,进行32个1×1卷积核,输出为:28×28×32
最后对4个分支的输出做“深度”方向组合,得到输出28×28×256,接着数据被分出4个分支,进入Inception (3b);- Inception (3b):由4部分组成
- 128个1×1的卷积核,输出为28×28×128;
- 128个1×1的卷积核做降维,输出为28×28×128,进行192个3×3卷积核(stride=1,padding=1),输出为:28×28×192
- 32个1×1的卷积核做降维,输出为28×28×32,进行96个5×5卷积核(stride=1,padding=2),输出为:28×28×96
- 256个3×3卷积核(stride=1,padding=1),输出为28×28×256,进行64个1×1卷积核,输出为:28×28×64
最后对4个分支的输出做“深度”方向组合,得到输出28×28×480;
后面结构以此类推。
用PaddlePaddle实现GoogLeNet
1.网络结构 googlenet.py
在PaddlePaddle的models下面,有关于GoogLeNet的实现代码,大家可以直接学习拿来跑一下:
1 import paddle.v2 as paddle 2 3 __all__ = ['googlenet'] 4 5 6 def inception(name, input, channels, filter1, filter3R, filter3, filter5R, 7 filter5, proj): 8 cov1 = paddle.layer.img_conv( 9 name=name + '_1', 10 input=input, 11 filter_size=1, 12 num_channels=channels, 13 num_filters=filter1, 14 stride=1, 15 padding=0) 16 17 cov3r = paddle.layer.img_conv( 18 name=name + '_3r', 19 input=input, 20 filter_size=1, 21 num_channels=channels, 22 num_filters=filter3R, 23 stride=1, 24 padding=0) 25 cov3 = paddle.layer.img_conv( 26 name=name + '_3', 27 input=cov3r, 28 filter_size=3, 29 num_filters=filter3, 30 stride=1, 31 padding=1) 32 33 cov5r = paddle.layer.img_conv( 34 name=name + '_5r', 35 input=input, 36 filter_size=1, 37 num_channels=channels, 38 num_filters=filter5R, 39 stride=1, 40 padding=0) 41 cov5 = paddle.layer.img_conv( 42 name=name + '_5', 43 input=cov5r, 44 filter_size=5, 45 num_filters=filter5, 46 stride=1, 47 padding=2) 48 49 pool1 = paddle.layer.img_pool( 50 name=name + '_max', 51 input=input, 52 pool_size=3, 53 num_channels=channels, 54 stride=1, 55 padding=1) 56 covprj = paddle.layer.img_conv( 57 name=name + '_proj', 58 input=pool1, 59 filter_size=1, 60 num_filters=proj, 61 stride=1, 62 padding=0) 63 64 cat = paddle.layer.concat(name=name, input=[cov1, cov3, cov5, covprj]) 65 return cat 66 67 68 def googlenet(input, class_dim): 69 # stage 1 70 conv1 = paddle.layer.img_conv( 71 name="conv1", 72 input=input, 73 filter_size=7, 74 num_channels=3, 75 num_filters=64, 76 stride=2, 77 padding=3) 78 pool1 = paddle.layer.img_pool( 79 name="pool1", input=conv1, pool_size=3, num_channels=64, stride=2) 80 81 # stage 2 82 conv2_1 = paddle.layer.img_conv( 83 name="conv2_1", 84 input=pool1, 85 filter_size=1, 86 num_filters=64, 87 stride=1, 88 padding=0) 89 conv2_2 = paddle.layer.img_conv( 90 name="conv2_2", 91 input=conv2_1, 92 filter_size=3, 93 num_filters=192, 94 stride=1, 95 padding=1) 96 pool2 = paddle.layer.img_pool( 97 name="pool2", input=conv2_2, pool_size=3, num_channels=192, stride=2) 98 99 # stage 3 100 ince3a = inception("ince3a", pool2, 192, 64, 96, 128, 16, 32, 32) 101 ince3b = inception("ince3b", ince3a, 256, 128, 128, 192, 32, 96, 64) 102 pool3 = paddle.layer.img_pool( 103 name="pool3", input=ince3b, num_channels=480, pool_size=3, stride=2) 104 105 # stage 4 106 ince4a = inception("ince4a", pool3, 480, 192, 96, 208, 16, 48, 64) 107 ince4b = inception("ince4b", ince4a, 512, 160, 112, 224, 24, 64, 64) 108 ince4c = inception("ince4c", ince4b, 512, 128, 128, 256, 24, 64, 64) 109 ince4d = inception("ince4d", ince4c, 512, 112, 144, 288, 32, 64, 64) 110 ince4e = inception("ince4e", ince4d, 528, 256, 160, 320, 32, 128, 128) 111 pool4 = paddle.layer.img_pool( 112 name="pool4", input=ince4e, num_channels=832, pool_size=3, stride=2) 113 114 # stage 5 115 ince5a = inception("ince5a", pool4, 832, 256, 160, 320, 32, 128, 128) 116 ince5b = inception("ince5b", ince5a, 832, 384, 192, 384, 48, 128, 128) 117 pool5 = paddle.layer.img_pool( 118 name="pool5", 119 input=ince5b, 120 num_channels=1024, 121 pool_size=7, 122 stride=7, 123 pool_type=paddle.pooling.Avg()) 124 dropout = paddle.layer.addto( 125 input=pool5, 126 layer_attr=paddle.attr.Extra(drop_rate=0.4), 127 act=paddle.activation.Linear()) 128 129 out = paddle.layer.fc( 130 input=dropout, size=class_dim, act=paddle.activation.Softmax()) 131 132 # fc for output 1 133 pool_o1 = paddle.layer.img_pool( 134 name="pool_o1", 135 input=ince4a, 136 num_channels=512, 137 pool_size=5, 138 stride=3, 139 pool_type=paddle.pooling.Avg()) 140 conv_o1 = paddle.layer.img_conv( 141 name="conv_o1", 142 input=pool_o1, 143 filter_size=1, 144 num_filters=128, 145 stride=1, 146 padding=0) 147 fc_o1 = paddle.layer.fc( 148 name="fc_o1", 149 input=conv_o1, 150 size=1024, 151 layer_attr=paddle.attr.Extra(drop_rate=0.7), 152 act=paddle.activation.Relu()) 153 out1 = paddle.layer.fc( 154 input=fc_o1, size=class_dim, act=paddle.activation.Softmax()) 155 156 # fc for output 2 157 pool_o2 = paddle.layer.img_pool( 158 name="pool_o2", 159 input=ince4d, 160 num_channels=528, 161 pool_size=5, 162 stride=3, 163 pool_type=paddle.pooling.Avg()) 164 conv_o2 = paddle.layer.img_conv( 165 name="conv_o2", 166 input=pool_o2, 167 filter_size=1, 168 num_filters=128, 169 stride=1, 170 padding=0) 171 fc_o2 = paddle.layer.fc( 172 name="fc_o2", 173 input=conv_o2, 174 size=1024, 175 layer_attr=paddle.attr.Extra(drop_rate=0.7), 176 act=paddle.activation.Relu()) 177 out2 = paddle.layer.fc( 178 input=fc_o2, size=class_dim, act=paddle.activation.Softmax()) 179 180 return out, out1, out2
2.训练模型
1 import gzip 2 import paddle.v2.dataset.flowers as flowers 3 import paddle.v2 as paddle 4 import reader 5 import vgg 6 import resnet 7 import alexnet 8 import googlenet 9 import argparse 10 11 DATA_DIM = 3 * 224 * 224 12 CLASS_DIM = 102 13 BATCH_SIZE = 128 14 15 16 def main(): 17 # parse the argument 18 parser = argparse.ArgumentParser() 19 parser.add_argument( 20 'model', 21 help='The model for image classification', 22 choices=['alexnet', 'vgg13', 'vgg16', 'vgg19', 'resnet', 'googlenet']) 23 args = parser.parse_args() 24 25 # PaddlePaddle init 26 paddle.init(use_gpu=True, trainer_count=7) 27 28 image = paddle.layer.data( 29 name="image", type=paddle.data_type.dense_vector(DATA_DIM)) 30 lbl = paddle.layer.data( 31 name="label", type=paddle.data_type.integer_value(CLASS_DIM)) 32 33 extra_layers = None 34 learning_rate = 0.01 35 if args.model == 'alexnet': 36 out = alexnet.alexnet(image, class_dim=CLASS_DIM) 37 elif args.model == 'vgg13': 38 out = vgg.vgg13(image, class_dim=CLASS_DIM) 39 elif args.model == 'vgg16': 40 out = vgg.vgg16(image, class_dim=CLASS_DIM) 41 elif args.model == 'vgg19': 42 out = vgg.vgg19(image, class_dim=CLASS_DIM) 43 elif args.model == 'resnet': 44 out = resnet.resnet_imagenet(image, class_dim=CLASS_DIM) 45 learning_rate = 0.1 46 elif args.model == 'googlenet': 47 out, out1, out2 = googlenet.googlenet(image, class_dim=CLASS_DIM) 48 loss1 = paddle.layer.cross_entropy_cost( 49 input=out1, label=lbl, coeff=0.3) 50 paddle.evaluator.classification_error(input=out1, label=lbl) 51 loss2 = paddle.layer.cross_entropy_cost( 52 input=out2, label=lbl, coeff=0.3) 53 paddle.evaluator.classification_error(input=out2, label=lbl) 54 extra_layers = [loss1, loss2] 55 56 cost = paddle.layer.classification_cost(input=out, label=lbl) 57 58 # Create parameters 59 parameters = paddle.parameters.create(cost) 60 61 # Create optimizer 62 optimizer = paddle.optimizer.Momentum( 63 momentum=0.9, 64 regularization=paddle.optimizer.L2Regularization(rate=0.0005 * 65 BATCH_SIZE), 66 learning_rate=learning_rate / BATCH_SIZE, 67 learning_rate_decay_a=0.1, 68 learning_rate_decay_b=128000 * 35, 69 learning_rate_schedule="discexp", ) 70 71 train_reader = paddle.batch( 72 paddle.reader.shuffle( 73 flowers.train(), 74 # To use other data, replace the above line with: 75 # reader.train_reader('train.list'), 76 buf_size=1000), 77 batch_size=BATCH_SIZE) 78 test_reader = paddle.batch( 79 flowers.valid(), 80 # To use other data, replace the above line with: 81 # reader.test_reader('val.list'), 82 batch_size=BATCH_SIZE) 83 84 # Create trainer 85 trainer = paddle.trainer.SGD( 86 cost=cost, 87 parameters=parameters, 88 update_equation=optimizer, 89 extra_layers=extra_layers) 90 91 # End batch and end pass event handler 92 def event_handler(event): 93 if isinstance(event, paddle.event.EndIteration): 94 if event.batch_id % 1 == 0: 95 print " Pass %d, Batch %d, Cost %f, %s" % ( 96 event.pass_id, event.batch_id, event.cost, event.metrics) 97 if isinstance(event, paddle.event.EndPass): 98 with gzip.open('params_pass_%d.tar.gz' % event.pass_id, 'w') as f: 99 trainer.save_parameter_to_tar(f) 100 101 result = trainer.test(reader=test_reader) 102 print " Test with Pass %d, %s" % (event.pass_id, result.metrics) 103 104 trainer.train( 105 reader=train_reader, num_passes=200, event_handler=event_handler) 106 107 108 if __name__ == '__main__': 109 main()
3.运行方式
1 python train.py googlenet
其中最后的googlenet是可选的网络模型,输入其他的网络模型,如alexnet、vgg3、vgg6等就可以用不同的网络结构来训练了。
用Tensorflow实现GoogLeNet
tensorflow的实现在models里有非常详细的代码,这里就不全部贴出来了,大家可以在models/research/slim/nets/ 里详细看看,关于InceptionV1~InceptionV4的实现都有。
ps:这里的slim不是tensorflow的contrib下的slim,是models下的slim,别弄混了,slim可以理解为Tensorflow的一个高阶api,在构建这些复杂的网络结构时,可以直接调用slim封装好的网络结构就可以了,而不需要从头开始写整个网络结构。关于slim的详细大家可以在网上搜索,非常方便。
总结
其实GoogLeNet的最关键的一点就是提出了Inception结构,这有个什么好处呢,原来你想要提高准确率,需要堆叠更深的层,增加神经元个数等,堆叠到一定层可能结果的准确率就提不上去了,因为参数更多了啊,模型更复杂,更容易过拟合了,但是在实验中转向了更稀疏但是更精密的结构同样可以达到很好的效果,说明我们可以照着这个思路走,继续做,所以后面会有InceptionV2 ,V3,V4等,它表现的结果也非常好。给我们传统的通过堆叠层提高准确率的想法提供了一个新的思路。