本文仅介绍wal的基本处理,如create、open、close、read等操作,从wal目录中加载snapshot,wal文件的创建,以及读取wal目录中的所有数据(主要是entryType、stateType、metadataType这几类)和接收到node.Ready()之后的写操作。
WAL的处理还是比较复杂的可以借鉴的地方也很多。WAL在编码以及flush时使用缓存来提升效率。flush的单位为分页,每页又分为8个section,section的作用是用来检测写入的数据是否被破坏,检测逻辑为:如果某个section中的所有字节都为0,则说明数据遭到破坏,反之则认为数据正常。在isTornEntry中,主要通过section机制来检测WAL文件中最后一个record是否因为数据破坏而导致json解析或crc校验失败。
wal很多地方用到了crc校验,基本逻辑是在encoder写入时会计算crc,在使用新文件(如create或cut)时会保存crc。创建文件时写入的crc为0,切分文件(新文件由WAL.fp提供)时写入的crc为前一个文件的crc,一个文件仅会在开头保存一个crc。在读取WAL文件时,decoder会在读取到非crcType的recorder时更新其crc,当读到crcType的recorder时会使用它计算出的crc与recorder中的crc进行比较,判断是否存在数据篡改。每个recorder中都会保存crc,crcType只是提供了一个执行crc校验的机会(即只有遇到crcType类型才会进行crc校验)。
在看代码时也给官方提了一些issue:13273、13287、13286
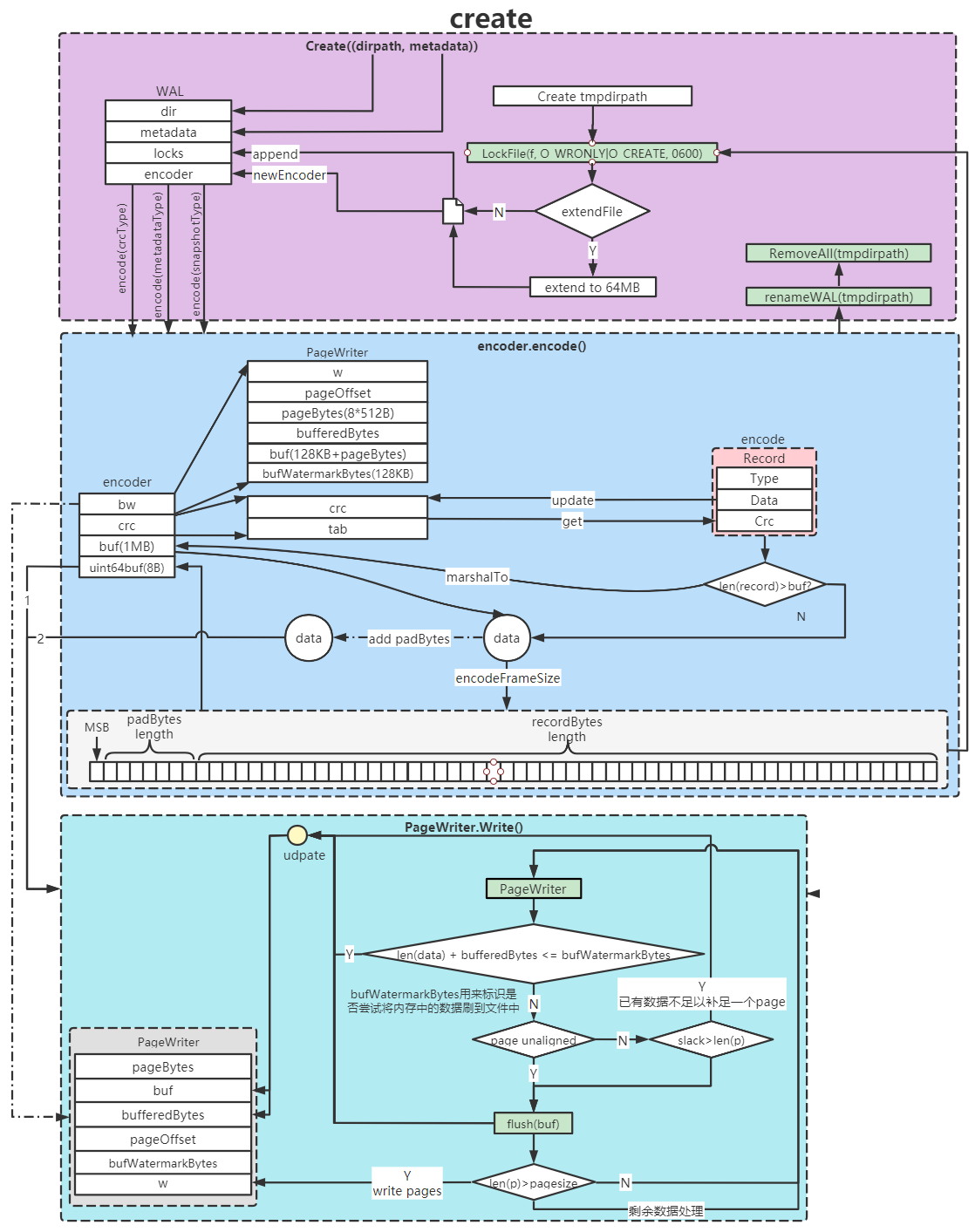
创建
下面是wal的create流程,在创建文件事先预分配文件大小(64MB),用于提升性能。wal通过encode()函数将编码后的数据写入文件,因此需要在对文件执行写操作时加锁,写入的数据以record为单位(record首先被写入缓存,当数据以页为单位对齐时通过flush写入文件)。先计算数据的crc校验码,然后计算record的帧数据。写数据时,先写入帧数据,再写入record。在写入数据(无论是帧数据还是record)时,会以页为单位将数据写入文件,不足一页的数据会暂存在缓存中。帧数据保存了实际的数据大小和pad的数据大小,在读取wal文件时会用到该信息。
wal的文件名由两部分构成:seq和index,前者应该顺序递增的,以保证日志文件的连续性(isValidSeq会根据seq校验日志文件的连续性)。
加载snapshot
下面是在wal目录中加载snapshot的操作,该操作中用到了上面的帧数据。wal使用decode()函数进行解码,首先取出在帧数据中解析出record的大小和padBytes的小,然后根据record的大小解码数据,最后根据record的类型采集并返回所有snapshot。

从上面可以看到,wal的encoder用于写文件,因此encoder会关联到当前正在编辑的文件,记录了文件句柄、当前字节偏移以及缓存等信息,一般会选择WAL.locks中的最后一个元素。而decoder用于读取所有文件,因此关联到多个wal文件,记录了这些文件句柄。
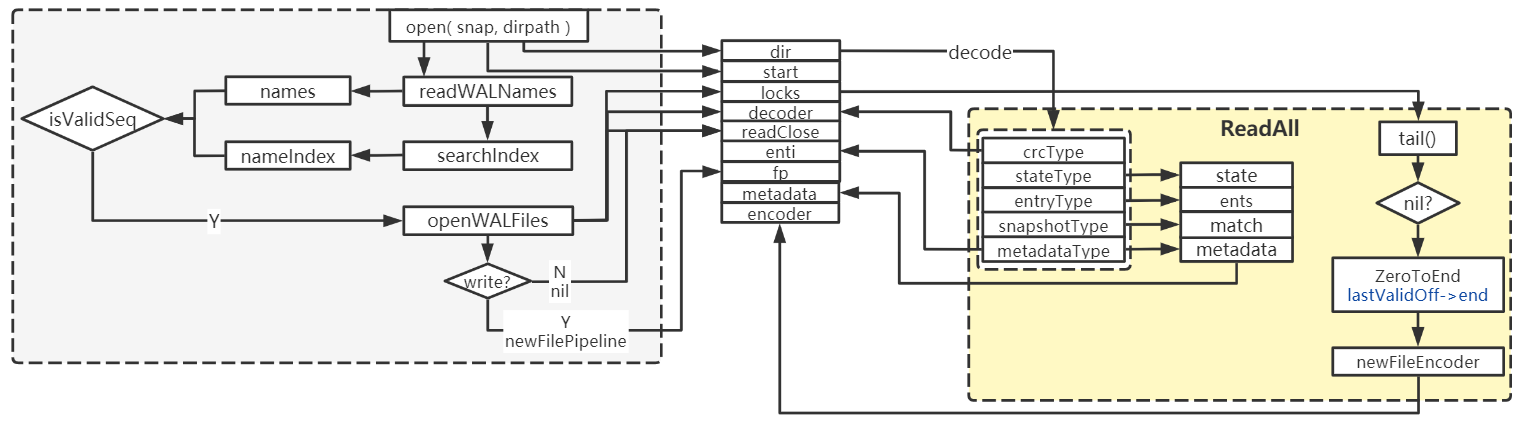
读取所有数据
下图是从wal目录中尝试读取所有信息(如metadata、entries、state)的过程。涉及读取wal目录中的文件信息,以此构建WAL结构,然后通过生成的decoder来将文件解码为不同类型的数据进行处理。最终返回解码后的数据。需要注意decoder的文件是有序的,可以从源码fileutil.ReadDir看出来,其对文件名进行了sort.Strings(names)操作。
此外,在读取文件时,根据文件的读写模式分别进行了处理。读模式下只需读完所有文件,关闭文件并返回结果即可。写模式下文件是加锁的,在decodeRecord中会读取lastValidOff(frameSizeBytes + recBytes + padBytes)长度的数据,并将该长度之后的数据归0,防止文件中出现被破坏的数据,由于对文件的修改会改变文件的crc校验,但好在新的record不会立即刷新到文件中(源码中的描述如下),更新文件的encoder,后续通过encoder将数据最终写入文件即可。
// decodeRecord() will return io.EOF if it detects a zero record,
// but this zero record may be followed by non-zero records from
// a torn write. Overwriting some of these non-zero records, but
// not all, will cause CRC errors on WAL open. Since the records
// were never fully synced to disk in the first place, it's safe
// to zero them out to avoid any CRC errors from new writes.
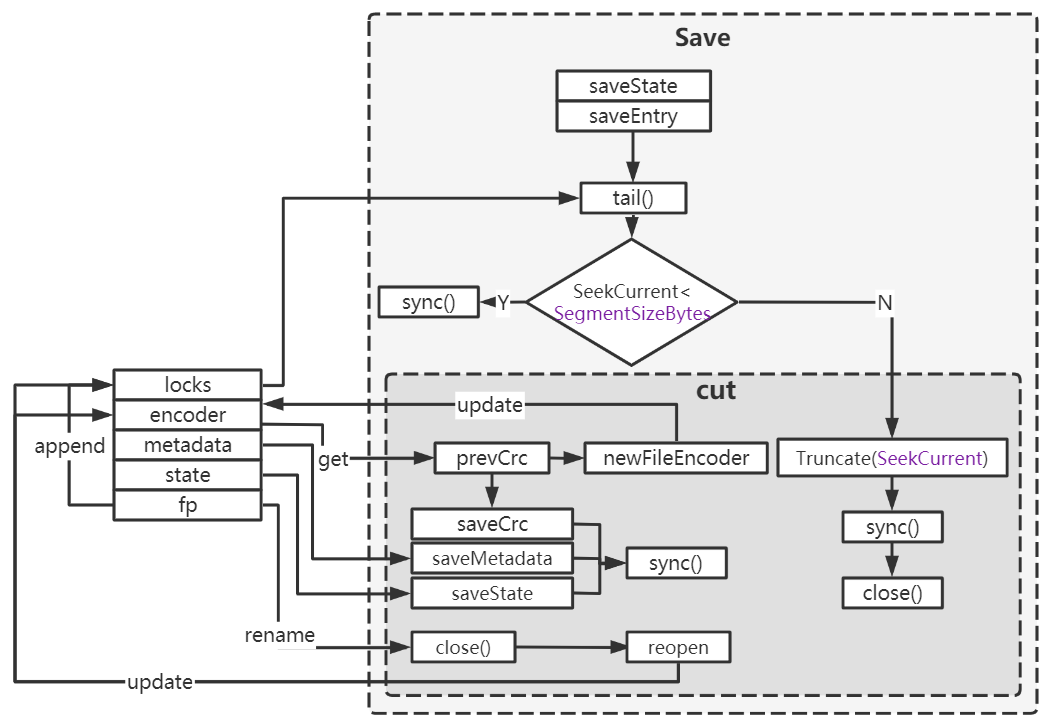
WAL的保存
raftexample的serveChannels中当接收到node.Ready()传来的数据时,会对这些数据进行持久化。如下图,首先会保存状态和entry信息,如果locks中最后一个文件(该文件)的内容大于或等于SegmentSizeBytes时需要切割文件。
在切分文件时,将已有的数据同步到文件中,后面的操作就是新建一个文件。新文件来自于WAL.fp是在创建文件时创建的,fp提供文件的代码逻辑如下,可以看到它通过循环创建文件的方式来为WAL源源不断地提供日志文件。
for {
f, err := fp.alloc()
if err != nil {
fp.errc <- err
return
}
select {
case fp.filec <- f:
case <-fp.donec:
os.Remove(f.Name())
f.Close()
return
}
}
首先在新文件中记录当前的crc,然后写入metadata和state信息,并重新计算crc,在读取时可以校验到此为止的crc。新文件作为WAL.locks中的最后一个文件。