自适应软件缓存管理
译自:Adaptive Software Cache Management
简介
由于负载的多样性,很难开发一个能够适用于各种负载的软件缓存管理策略。在本论文中,我们调研了一种用于软件缓存管理框架的自适应机制,通过调节参数来调节负载的最常(访问) vs 最近(访问)的缓存比例。最终目标是通过自动调节参数来获得最佳性能(而无需人工介入)。我们针对该问题研究了两种方案:爬山解决方案和基于指示器的解决方案。在爬山解决方案中,通过不断配置系统来获得最佳配置。在指示器方案中,我们评估了最常(访问) vs 最近(访问)对系统的影响,并根据单一变量调节参数。
我们将这些自适应机制用于最新的两个软件管理框架中,并对在大量不同特性的负载下的框架和自适应机制进行了评估。通过这些工作来衍生出一个与参数无关的软件缓存策略,并在所有测试的负载中保持竞争力。
本文提供了两种缓存自适应策略:爬山方案和指示器方案。通过比较发现基于W-TinyLFYU的自适应缓存框架可以很好地工作于多种负载之下。
后续有时间研究一下文中给出的自适应实现方式。
1 概述
缓存是一种通过维护相对较小的(临近的)高速内存块中的数据来解决系统突发性能的技术。这里我们主要关心软件缓存,即由中间件、操作系统、文件系统、存储系统和数据库等软件系统维护的缓存(而非由硬件实现的缓存,如CPU的L1、L2和L3缓存)。重复访问存在于缓存中的数据的行为,称为缓存命中,其远快于从实际存储中获取数据。其他访问则称为缓存缺失。缓存管理策略的主要工作是确定哪些元素可以放在缓存中,猜测哪些元素可以获得最高的命中率,即缓存命中率和整体访问数的比率。这类框架通常会尝试在负载中确定某些模式来获得最高命中率。
最近(访问)和最常(访问)是软件缓存管理策略经常使用的两种方式。最近(访问)认为,最近访问的元素很可能在不久的将来被重复访问。相比之下,最常(访问)认为,最常访问的元素很可能在不久的将来被重复访问。由于大多数负载元素的流行度都会随着时间变化,通常会使用如滑动窗口[17]或指数退避[13,19]来测量使用频率。
从经验上看,不同的负载展示了不同程度的最近(访问) vs 最常(访问),这也是为什么很难去设计一个单一的"最佳"缓存管理款框架。因此系统设计者面临的并非一项简单的任务,需要了解负载的特性,然后为这些负载调研出一个可以提供最高命中率的缓存管理策略。而且,一些缓存管理策略具有可调节的参数,这要求系统设计者了解如何去配置这些参数。更糟糕的是,当设计一个新系统时,有可能无法事先知道未来运行的负载,这样设计者就无法判断应该选择哪种缓存管理策略。另外,在一般的缓存库中,为了无需让用户处理设置参数,会将这些参数设置为默认值,以为大多数负载提供最佳结果。但对于其他系统负载,这类设置可能会大大偏离最佳结果。
总之,自适应软件缓存管理策略需要在尽可能多的负载上获得富有竞争力的命中率。我们将聚焦在探索软件存储的自适应性机制。
价值
在本论文中,我们为软件缓存管理框架确定了两种自适应机制,这两种机制都暴露了影响命中率的调参。第一种基于爬山方式[26]来调节缓存管理参数。特别地,我们会定期在某个方向上调整参数,使之在偏最近(访问)的负载 vs 偏最常(访问)的负载下更好地工作。在一段时间后,使用最近获得的命中率与上一次的命中率进比较。如果命中率获得了显著提升,则在相同方向上继续调参,否则在相反方向上调参,以此往复。爬山方案最大的优势是可以在不引入任何元数据的情况下实现。然而,它可能会陷入局部最大值的风险,且永远不会停止振荡。
另一种方式是基于指标的方案。这里,我们会定期计算负载的最常(访问) vs 最近(访问)的评估结果,并调节相应的参数。这种方式需要一些元数据来计算上述评估结果,并快速收敛。
我们将这两种方法引入最近出现的FRD[25]和W-TinyLFU [13]1框架中。这两个框架都将整个缓存区域划分为两个子缓存,一个用于保存"最近进入的元素",另一个用于保存"常用的元素"。两个框架都将两个子缓存的比例作为一个可调节的参数,但在选择哪个元素进入哪个子缓存上有所差异。在W-TinyLFU中,取决于一个通过节省空间的sketch [11]实现的准入过滤器,其频率老化机制作为自适应的另一个潜在区域。
这里,我们使用上面提到的爬山和指示器方法来为在线负载探索动态调节FRD和W-TinyLFU的参数的方式。特别是调节FRD和W-TinyLFU的两个子缓存的相对大小。对于W-TinyLFU,我们还处理了其sketch准入过滤器的过期参数。
最后,我们将提出的方案与来自不同途径的实验结果(一些来自于前面的工作,一些来自于Caffeine的用户[23])进行了评估。 在我们的评估中,与最佳替代方案相比,我们的自适应方案始终富有竞争力。
2 相关工作
Belady的最优缓存管理策略[5]可以面向未来,并从缓存中淘汰最早访问的元素。但由于无法预测未来,因此在大多数领域中,该策略是不现实的。它可以作为缓存策略性能的上限。在实践中,缓存管理策略涉及典型访问模式的启发和优化。
LRU基于这种假设:最近最少访问的元素,则未来不可能再次访问。这样,一旦缓存满后,它会淘汰LRU元素,为新到的元素让出空间。而LFU认为访问频率是一种好的对未来行为[2, 3, 13, 17, 18]的评估器。LFU需要监控大量不存在于缓存中的元素,因此可能会造成大量开销。[13]使用一个近似sketch来最小化这类开销。此外,LFU策略经常会引入过期,通过对应的特定滑动窗口[17]或指数衰减样本来计算频率[2,3]。其他方式包括通过重用距离[1,16,20]来计算后续到同一条目的访问时差。 但后者需要记住大量的幽灵条目。
空间是优化的另一个维度。在一些场景下,元素的大小差异很大,因此需要将大小算进去[6, 9, 32]。通过自适应大小来调节缓存准入的可能性,进而最大化目标命中率[6]。相反,很多缓存策略会维护一个固定数目的元素,而不关心元素大小,只有当缓存的元素大小相同或类似时才不会对效率造成影响,如块缓存和分页缓存。另外,很多知名的视频点播和流系统会将文件分割为相同大小的块,每一块都可以独立缓存。这里,我们关注固定大小的元素。
Hyperbolic缓存是最近提出的一个各方面比较好的缓存管理策略。Hyperbolic缓存可以使用相同的数据结构来模拟多种淘汰策略,因此能够根据负载采取相应的动作。另一个自适应策略是Adaptive Replacement Cache (ARC) [24]。这两种策略的共同缺陷是在最常(访问)方式下没有竞争力,而且ARC需要维护大量幽灵表项。
LRFU[19]结合了最近和最常两种方式来评估缓存中的每个元素,通过参数λ来控制平衡。当使用"正确的"λ来为一个给定的负载初始化LRFU时可能会获得高命中率,而选择"错误的"值则可能导致性能问题。根据负载自动化调节λ仍然是一个问题。另一个妨碍LRFU被广泛采纳的原因是其本身高昂的实现和运行时代价。
最近出现的Mini-Sim [31]方法建议同时模拟多种缓存配置,每种模拟会通过在所有访问中进行随机采样来降低计算开销。这种方法的问题是由于采用了在r次访问中采样一次的方式,因此在一个短周期内可能会丢失多次访问(这里1/r作为采样率),无法捕获基于最近(访问)的负载的特征。Mini-Sim会随机采样1/r次,然后将代表所有访问的采样元素提供给模拟配置。为了节省空间,将模拟缓存大小设置为c/r,c为原始缓存大小。回顾一下,我们的目标是找出一个最佳配置参数,而不是决定哪个元素应该出现在实际缓存中。
Mini-Sim有如下缺陷。模拟配置必须持有它们所保存的元素的幽灵表项,这样会导致空间浪费,且执行时间与同时配置的模拟数量和采样率成比例。我们针对Mini-Sim和W-TinyLFU进行了实验,发现在缓存了上千个元素且使用基于最常访问的负载上,Mini-Sim需要更大的采样率才能获得相同精确的结果。在实践中,在基于最常访问的负载上,基于元素ID的采样的精度要稍低,因为如果没有采用到常用的元素,则MiniSim的结果会与实际负载的行为有所出入。此外,由于使用的是采样,MiniSim需要相对更长的时间来适应负载的变化。相比之下,我们的方法更具冒险精神 - 在没有事先模拟新配置的性能的情况下直接更改配置。
最近的LeCaR研究[30]使用机器学习技术来结合LRU和LRF替换策略,其展示的结果要优于ARC,且在负载变化时表项良好。
还有一些工作考虑到了SSD缓存的特点,更重要的是[8]中的工作描述了为何Belady的最优观点不适用于SSDs,并提出了一个新的离线优化算法(该算法不仅最大化命中率,还考虑到容器放置问题以减少写入放大和设备磨损)。Pannier[21]专注于SSD的容器缓存实现细节,他使用一个自适应信用系统来限制SSD写入预定义配额的数据量。这和我们的[15]工作类似,它维护了一个使用幽灵表项的对象的频率统计信息,且仅允许最常用的对象进入SSD缓存,使用ARC作为缓存替换算法。本质上,这种方法和TintLFU类似,区别是使用了幽灵表项,而不是sketches。
硬件CPU缓存领域中,最接近我们工作的是[28],它提出了一种在不同替换策略(LRU、LFU、FIFO、Random)间切换的自适应机制,但不能调节任何配置参数。
3 概述 W-TINYLFU 和FRD
正如上文提示的,W-TinyLFU包含三个组件:Main缓存,一个近似LFU的准入过滤器,称为TinyLFU,以及一个Windows缓存,如图1。新到的元素会被插入到Window缓存。原则上,它可以使用任何已有的策略进行维护,但在Caffeine实现中,Window缓存使用了LRU淘汰[23]。类似地,Main缓存可能会引入任何缓存管理框架,但Caffeine使用了SLRU淘汰策略。从Window缓存淘汰的元素以及从Main缓存淘汰的元素会进入TinyLFYU过滤器,后续会对二者的频率进行评估,并选择频率最高的插入/保持到Main缓存中。

图1.W-TinyLFU框架:元素总是首先进入Windows缓存,从Windows缓存淘汰之后会进入Main缓存,此时会使用TinyLFU作为其准入过滤器。在这里,我们保留了[13]中的术语
可以将W-TinyLFU中Window缓存的大小设置为总缓存大小的0%-100%。W-TinyLFU的作者[13]经过大量负载实验后得出,将该值设置为1%可以获得最佳的命中率,这也是为什么Caffeine缓存库[23]将其作为默认配置的原因。然而,在一些严重偏向最近(访问)的负载中,需要将Window缓存的大小提升到20%-40%来媲美最佳备选方案(通常是LRU或ARC)。
通常使用sketch来实现用于评估访问频率的TinyLFU准入过滤器,如minimal increment counting Bloom filter [10]或count min sketch [11]。用于统计频率信息的采样大小S是缓存大小C的倍数。为了实现表项的过期功能,每达到S次访问后,计数器就会除以一个过期因子,该操作称为Reset[13]。默认情况下,过期因子为2,即,所有计数器都会在每个Reset操作时减半。由于访问频率为S/C的元素已经足够频繁,可以留在缓存中,因此计数器的最大值为S/C。
FRD [25]也将整个缓存区域划分为两部分,称为Temporal缓存和Actual缓存,每一部分都使用LRU进行管理。FRD会维护比较长的历史访问,类似其他框架中的幽灵表项。当出现缓存丢失时,如果访问的元素出现在历史记录中,则会将其插入到Actual缓存。否则,会将该新元素插入到Temporal缓存中。与W-TinyLFU类似,Temporal缓存和Actual缓存的比例是一个可调节的参数。经过测量,作者[25]建议将Temporal缓存的默认值设置为10%,并在后续工作中动态调节该值。与W-TinyLFU不同,FRD需要维护一个扩展的访问历史。
4 自适应缓存策略
本章中,我们会使用一些方法来派生出自适应缓存管理策略。我们讨论了熟知的爬山算法[26],以及新的、基于指示器的自适应框架的适应性。为了呈现具体的演示结果,在4.1章节中,首先调节W-TinyLFU 和 FRD的参数来对这些框架进行调节(当然,为了更好地处理基于最近(访问) vs 最常(访问)的负载,可以采用任何暴露了调参的框架)。然后在4.2章节中讨论自适应框架。
4.1 可调节参数
对于W-TinyLFU和FRD,我们暴露了动态调节Windows(或Temporal)缓存相对大小的接口(占总缓存的0-100%)。在W-TinyLFU中,我们还测验了动态校准TinyLFU准入过滤器使用的sketch参数(影响最常访问的元素的过期速度)。下面详细说明这些内容。
4.1.1 Window Cache 大小
当window(Temporal)缓存的淘汰策略是LRU时(例如Caffeine和FRD),如果window(Temporal)缓存较大,其整体行为将接近LRU。特别地,当window(Temporal)缓存占100%时,将完全成为LRU。相反,由于W-TinyLFU准入过滤器基于元素的过期频率,小的Window缓存将倾向于强调访问频率。类似地,在FRD中,Actual缓存用于保存常用元素,即,如果将main(Actual)缓存扩展到总缓存的100%,将在W-TinyLFU和FRD中获得以频率为导向的策略,参见图2。

图2:调节W-TinyLFU和FRD:window缓存和main缓存的比例暗示了在最近(访问)和最常(访问)上的取舍
4.1.2 W-TinyLFU Sketch 参数
W-TinyLFU准入过滤器有3个配置参数:(i)过期采样长度S,(ii)过期因子,每个Reset操作中的默认值为2,但可以扩大或缩小,(iii)每次访问元素时的增量,默认为1,也可以调节。
我们将一开始的采样长度设置为S。通过缩短S可以限制元素的最大频率个数,进而降低了不同元素之间的最大访问频率的差异,并加速了元素的过期进度(由于降低了最大值)。上述两种方式降低了访问频率的影响,使得过滤器更偏向最近(访问)。
增加过期因子可以划分Reset操作中的计数器,并加速过期,反之亦然。即增加因子会使过滤器倾向最近(访问),降低则会倾向最常(访问)。
最后,我们发现增加每次元素访问时的计数器增量会使得过滤器更倾向最近(访问)。这是因为更大的增量会更快地使计数器达到最大值,意味着计数器的值更多地反映了每个最近被访问的元素(而非元素的访问次数)。而且,我们会在总的增量达到采样大小时执行Reset操作,因此只需更少的元素就能触发Reset操作,更快触发过期。因此,大大降低了对历史频率的计数,而更关注最近产生的活动。
例如,增量为8,代表该元素的计数器会在元素进入时增加8,即估计的访问频率为8。第一次Reset操作之后,估计的频率会减半到4,第二次之后,会减半到2,以此类推。在极端情况下,当增量设置为S/C时,W-TinyLFU的行为最非常接近最近(访问),参见图3。
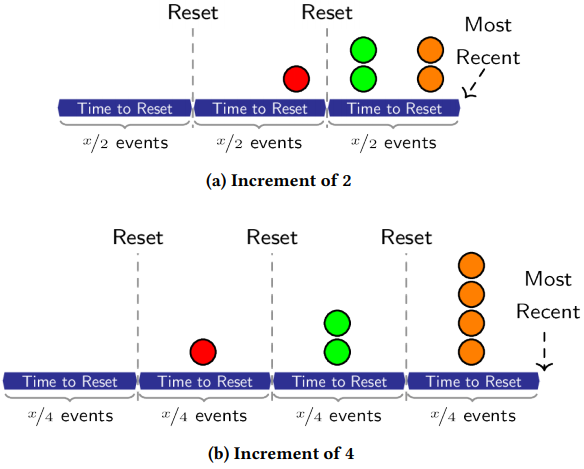
图3.该场景下,3个元素在不同时间仅出现了一次。增量为1的默认W-TinyLFU会将3个元素评为1(在上一次Reset之后)或0(在上一次Reset之前), 因此无法确定这三个元素的先后。图3a中的增量为2,在一个Reset操作之后变为1,Reset操作的频率也是前者的2倍,此时可以确定,最近访问了橘色和绿色的元素(而非红色的元素)。图3b的增量为4,再次加倍了Reset的次数,这种情况下,橘色和绿色之间多了一次Reset操作,因此我们探测到最近访问了橘色元素。
修改增量而非采样长度或Reset数值的动机主要出于工程的角度。即,除以2的操作可以高效地通过移位操作实现,而除以其他因子可能需要浮点运算。而且,修改sketch的大小可能会改变sketch的精度或需要动态内存分配。相反,修改增量值的影响较小,且实践中也容易实现。
4.2 潜在的自适应框架
4.2.1 爬山方案
爬山方案是一种简单的优化技术,用于查找一个函数的本地最优值。在我们的上下文中,首先在一个特定的方向上修改配置,即增大Window缓存大小。然后对比新老配置下的命中率。如果命中率有所提升,则在相同的方向上继续进行下一步验证,即持续增大window大小。反之,则向相反的方向进行验证。图4展示了爬山算法。
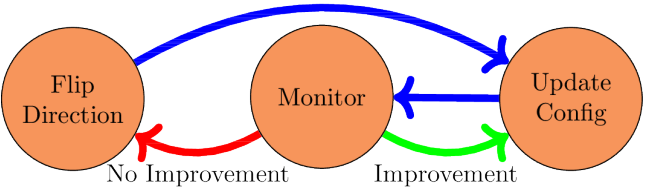
图4. 爬山算法。在监控阶段,比较当前的命中率和先前获得的命中率,如果当前命中率提升,则在相同的方向上更新配置。否则,在相反的方向上更新对应的配置
该方法的主要优点是我们不需要额外的元数据来重新配置缓存,而前面的自适应算法则需要元数据和幽灵表项[4,24]。爬山是很多缓存策略常用的算法。
在该算法中,我们首先修改一个特定方向上的缓存配置,然后评估其对性能的影响。即,我们事先并不知道该配置是否能够提升命中率。理解改方案的难点主要在于如何决定每次调节的步长,以及调节的频率,因此需要权衡这两个动作。
乍一看,使用小而频繁的步似乎吸引人。这是因为此时小步造成的惩罚更小,且对变更的响应更快。但使用这种方式的问题在于测量短时间内的命中率时会产生噪声。因此,使用频率过高的步时,很难区分命中率的变更是由于新配置导致的还是由于噪声导致的。
上述原因使我们对策略做出不那么频繁且相对较大的变更。频率较低的变更为我们提供了足够的时间来评估配置对性能的影响范围,并增大了命中率之间的差异,使之更容易被观察到。这意味着在调节window大小时我们会轮流使用21种可能的配置(0%, 1%, 5%, 10%等),以及在调节sketch参数时会使用15种可能的配置(注意我们的W-TinyLFU sketch的计数器最大值为15)。此外我们将判定间隔设置为10倍缓存大小的访问量,这给我们提供了足够的时间来评估新配置的影响。
4.2.2 最常-最近指示器
我们的目标是实时获取一个反映最常-最近平衡点的指示器,这种指示器会直接选择合适的配置,而无需采用逐渐增加步的方式。
指示器使用与W-TinyLFU过滤器[13]相同的sketch来评估元素的频率(增量值固定为1)。因此,当我们调节W-TinyLFU的Window缓存的大小(而非sketch增量)时,指示器会共享相同的(带W-TinyLFU过滤器的)sketch。
对于每个新到的元素,我们会累计sketch的估量,并使用这些估量的平均值作为hint,指导当前的工作模式偏向哪一方(最近/最常)。以往的经验告诉我们,较低的值会偏向最常访问的负载,而较高的值会偏向最近访问的负载,而更高的值又会偏向极度频繁访问的负载。直觉上讲,如果负载偏向最常访问则访问的元素是分散的,计数器的数值相对较低;如果负载偏向最近访问,则访问的元素是相对集中的,被访问元素的计数器数值相对较高。最后,当负载具有(偏向最常访问的)较大的频率偏差时,一小部分元素的访问会非常频繁,因此这种情况下hint数值会非常高。图5展示了这种场景。
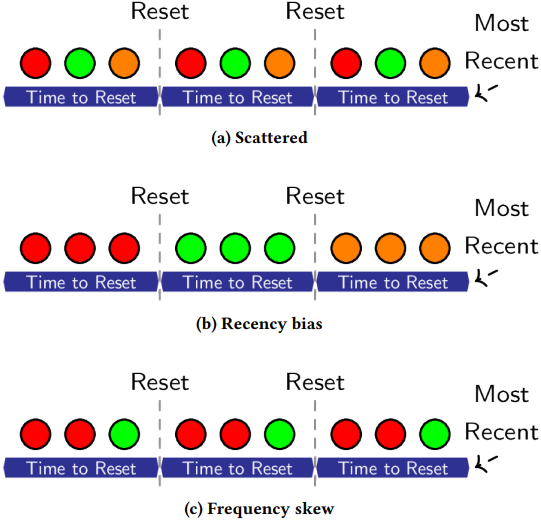
图5. 每个周期包含三个访问的场景。图5a中,每种元素在每个周期仅出现一次。由于Reset操作,频率估计总是0,因此hint等于0。图5b中,使用最近访问方式来记录访问,现在每个数值的访问估值为0,1,2.因此,指示数值等于1。图5c中,我们修改了每个数值出现的次数来描述频率偏差,第一个周期的估值变为0,1,0,其他周期的估值为1,2,0,hint值为0.77。
为了区分(大)频率偏差和(高度)最近访问的影响,我们使用其他机制来评估分布偏差。众所周知,当在轴是元素等级和频率的log-log图中绘制Zipf分布的元素时,结果是一条直线,该直线的斜率是频率偏差(skew)参数。在每个配置周期内,我们会汇集最常访问的元素,并通过在这些项目的log-log值上执行线性回归来计算偏差估值。这种计算不会太频繁(即,每一百乘以缓存大小次数),也更实际。
我们结合hint数值和频率偏差估计(skew)来构造我们期望的指示器,如下:
maxFreq是从频率sketch(设定为15)中获取的最大估值。我们的目标是在偏最近访问的结果保持高hint数值的情况下,不断接近1。因此如果极度偏最常访问时,skew的数值也会变大,此时会导致hint数值变低。由于skew范围为[0,1],通过以指数为3来提升skew,这样可以极大区分低数值与接近1的数值。正常的maxFreq数值为[0,1],0表示偏最常访问,1表示偏最近访问。
5 评估
本章中,会对我们的自适应机制(爬山和指示器)和适应参数(window缓存大小和sketch管理)进行大量评估。我们还评估了两个底层缓存策略W-TinyLFU和FRD(见第三章节)。表1展示了我们工作中涉及到的6种可能性:基于爬山算法(C)和指示器方式(I)来适应W-TinyLFU的Window(W)缓存,分别称为WC-W-TinyLFU和WI-W-TinyLFU。基于爬山算法(C)和指示器方式(I)适应FRD的Window(W)缓存,分别称为WC-FRD和WI-FRD。最后,基于爬山算法(C)和指示器方式(I)来适应W-TinyLFU的sketch(S),分别称为SC-W-TinyLFU 和 SI-WTinyLFU。我们还给出了使用Minu-Sim方法[31]来适应W-TinyLFU的Window大小的实验报告,称为MS-W-TinyLFU。

我们的实验是在Caffeine的仿真器[23]中执行的。竞争策略的实现就源自该库。在每次实验中,我们会给每个策略提供一个实例,并在没有预热的前提下给这些实例提供整个负载。
5.1 自适应配置
下面我们描述爬山和指示器技术中需要考虑到的不同配置。
爬山。爬山算法会在访问量达到10倍的缓存大小时进行一次自适应步骤。从1% 的Window(或Temporal)缓存开始,Window缓存涉及的所有配置为[0%, 1%, 5%, 10%, . . . , 80%],Temporal缓存涉及的所有配置为[0%, 1%, 5%, 10%, . . . , 100%]。为了调节W-TinyLFU sketch,我们考虑增量值范围为[1 - 15],即最多15种配置。回归一下,我们将1%作为初始配置[13],但作者[25]建议将Temporal缓存大小设置为10%。下面看下我们的自适应框架是如何在不同的配置下运作的。
指示器。指示器会在每当访问量达到50,000次时采取一次自适应决策。为了配置sketch,我们让[指示器*30],这样相当于指示直接使用了最大值15。由于sketch有15种可能的增量值,通过将指示器乘以30,一个值为0.5的指示器的就已经将增量设置为15。这样做的原因是,相比于Window大小的变化,sketch参数的变更造成的影响十分有限。因此在调节sketch参数时,我们将指示器的值翻倍。在配置Window和Temporal缓存大小时,我们分别使用[80*指示器]和[100*指示器]。特别地,一次性最多可以给Window缓存分配80%的总缓存,给Temporal缓存分配100%的总缓存。
5.2 追踪
我们的评估侧重在不同领域中的14种真实负载,包括数据库,分析系统,事务处理,查询引擎,Windows服务器等等。这些负载的底层特性不尽相同。有些基于最常访问,而有些则是最常和最近访问的结合体,而有些则完全基于最近访问。显然,没有任何一种配置能够完全负载所有负载。下面我们列出对这些负载进行追踪的内容:
- OLTP:追踪OLTP服务器[24]的文件系统。在一个典型的OLTP服务器中,大多数操作对象已经位于内存中,不会直接反映到磁盘访问。因此主要的磁盘访问主要体现为写事务日志。即追踪大部分为顺序块访问的升序列表(由于偶尔重写或内存缓存丢失造成的少量随机访问)。
- F1和F2:来自两个大型金融机构的事务处理跟踪。追踪来源于UMass的追踪库[22]。出于上述相同的原因,它们与OLTP的追踪结构非常类似。
- Wikipedia: Wikipedia的追踪,包含从2007年9月[29]开始的两个月内的10%的流量。
- DS1: 数据库追踪[24]。
- S3: 搜索引擎追踪[24]。
- WS1, WS2, and WS3: 来自UMass库的三个额外的搜索引擎追踪[22]。
- P8 和 P12: Windows 服务器 disc 访问[24]。
- SPC1-like:由ARC[24]的作者创建的用于测试存储系统性能的综合性追踪。
- Scarab:来自SCARAB Research的一小时追踪:从全球不同大小的几个电子商务站点的产品推荐查询。
- Gradle:保存编译结果(这样后续在不同机器上的构建就可以直接使用该结果,而无需重新构建)的分布式构建缓存追踪。由于机器借助了本地构建缓存,因此会基于最近访问来请求最新的分布式缓存。由Gradle项目提供追踪。
5.3 动机
我们首先展示了FRD和W-TinyLFU策略,且没有对调参做任何静态配置。图6展示了在变更FRD和W-TinyLFU的总缓存大小和Window(Temporal)的相对缓存大小的情况下获得的命中率。可以看到,对于搜索引擎,其命中率曲线单调递减。即,对于这些追踪,Window(Temporal)缓存越小越好。相反,Gradle,其曲线更偏向于较大的Window(Temporal)缓存,且越大越好。介于中间的是OLTP追踪。在该追踪中,最大值介于总缓存大小的[15%-30%]左右。因此,不同的静态配置对于不同的跟踪来说有利有弊。

可以看到Windows缓存比例越大越有利于倾向最近访问的负载;反之则有利于倾向最差访问的负载。但对于结合了最常和最近访问的负载,则需要通过验证来获得最佳配置。
5.4 指示器配置
如上所述,对skew参数的评估需要对最常使用的元素(单位个数为千)进行线性回归。直观上,越大的k值可以越精确地评估skew,但需要的计算量也会直线上升。我们从经验上选择默认的k值,这样就可以合理地对所有追踪进行评估。图7展示了不同k值下,对Wikipedia进行追踪的结果。我们选择k = 70,这是因为当k超过70时,很难再获得更好的评估结果。
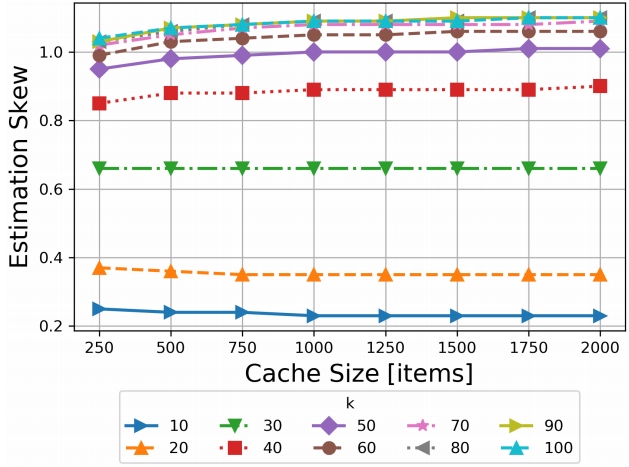
图7. 评估Wikipedia追踪中,不同k(单位:千)下的偏差。经验上,当k>70时,评估结果相对集中,且带来的优势微乎其微。
5.5 对6个算法进行评估
现在对我们提出的6个算法进行评估,来选择最佳算法。我们根据采用的配置参数对算法进行了划分,即动态调节Window(Temporal)缓存大小(WC-W-TinyLFU,
WI-W-TinyLFU, WC-FRD, and WI-FRD)的算法,和动态调节sketch增量(SC-W-TinyLFU, SI-W-TinyLFU)的算法。对于这些参数,我们将"offline"最优值最为参考基准,即通过单独为每个数据点选择最佳静态配置(即,每个工作负载和每个缓存大小是相互独立的)来获得基准值。
5.5.1 动态配置Window缓存大小
图8展示了动态配置Window缓存大小的结果。用"offline"标注的线表示给定追踪的最佳静态配置。W-TinyLFU(1%)为Caffeine [13]的默认配置,FRD建议的默认配置为10%[25]。

如图所示,Windows服务器(图8a)和搜索引擎追踪(图8b)中,所有基于W-TinyLFU的框架都接近线性最佳值,而自适应的FRD接近最佳值,但其曲线都低于基于W-TinyLFU的曲线。在Wikipedia追踪中(图8c),所有的框架都几乎是理想的。
数据库追踪(图8d)展示了类似的结论,即基于WTinyLFU的命中率要高于基于FRD的命中率。WTinyLFU框架中,在大规模缓存下,WC-W-TinyLFU的稍差,而WI-W-TinyLFU则在小规模缓存下稍差。自适应FRD框架则可以符合其推荐的配置性能。
在事务处理追踪(图8e)中,W-TinyLFU的默认配置要差于其他配置。然而,WIW-TinyLFU的性能要略优于其他配置(更接近"offline"的结果)。在Gradle追踪(图8f)也可以看到类似的提升,但此时动态FRD框架略优。
5.5.2 动态配置sketch参数
图9评估了修改W-TinyLFU sketch参数的算法,即SI-W-TinyLFU和SC-W-TinyLFU。我们将这些框架与最佳离线配置"Offline W-TinyLFU"进行了比较。
对于Window服务器(图9a)和搜索引擎追踪(图9b),所有结果都接近理想值。在数据库追踪(图9c)中,SC-W-TinyLFU的性能稍差。在OLTP(图9d)、Wikipedia (Figure 9e), 和 Gradle (Figure 9f)中,所有框架的结果都非常相似。
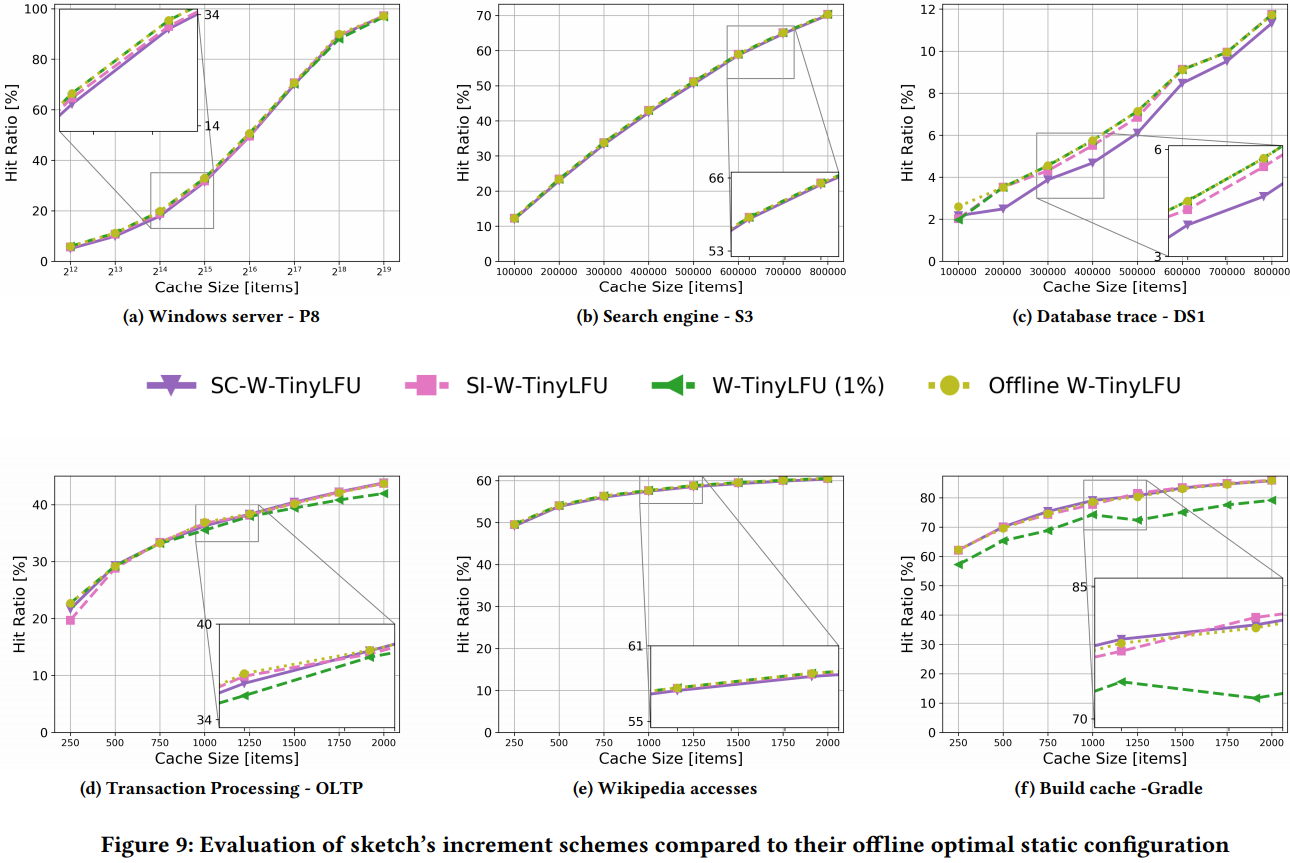
总之,无法确定哪种自适应策略(爬山或指示器)是最佳的。但至少可以看出,对于W-TinyLFU,自适应Window缓存大小似乎至少不比自适应sketch参数差。因此我们将继续使用两种算法:WC-W-TinyLFU和 WI-W-TinyLFU。取决于追踪的内容以及由于(W-Tinylfu的)sketch维护的元数据更少,基于W-TinyLFU的自适应方案可以与基于FRD的框架相媲美甚至明显更好。自适应的FRD框架即使在非推荐值下(1%)也能达到推荐配置的性能,这突出了动态自适应的好处:为了探测最佳配置,无需手动引入所有追踪。
5.6 与其他自适应机制进行比较
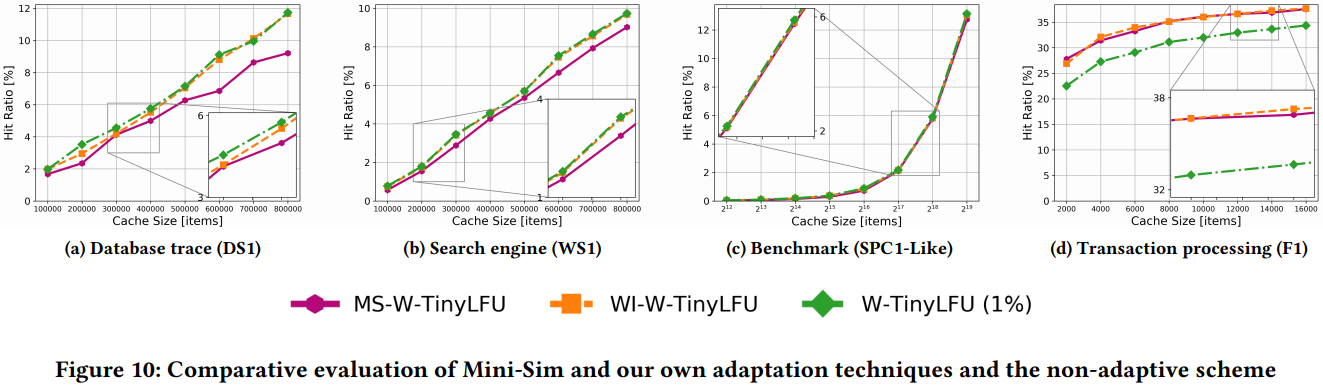
下面。将我们的自适应机制与Mini-Sim[31]进行比较。最后,我们会给W-TinyLFU配置101个Mini-Sim实例,每个实例都模拟不同比例的Window和Main缓存(称为MS-W-TinyLFU)。
根据[31]的建议,我们将Sm (模拟的缓存大小) >=100,采样率>=0.001。即Sm=max(100, 0.001C),C为测试的缓存大小,采样率为:
我们将决策间隔配置为1,000,000次访问(经验上最佳)。
图10展示了评估结果。在基于最常频率的数据库追踪中(图10a),WIW-TinyLFU要优于Mini-Sim,特别是在使用大型缓存时。在基于频率的搜索引擎追踪(图10b)中,Mini-SIM也相对滞后。这些结果显示出,在基于频率的追踪中,MiniSim的采用方法要相对低效。而在其他追踪中,如SPC1基准(图10c)和FI追踪(图10d)中,Mini-Sim和WI-W-TinyLFU一样好。总之,虽然Mini-Sim是一种可行的自适应解决方案,但不适用于基于频率的追踪和小缓存场景。相比之下,我们的爬山和指示器针对缓存提供了更强大的适应性。因此,我们将仅使用 WI-W-TinyLFU 和 WC-W-TinyLFU继续进行评估。
5.7 相对评估
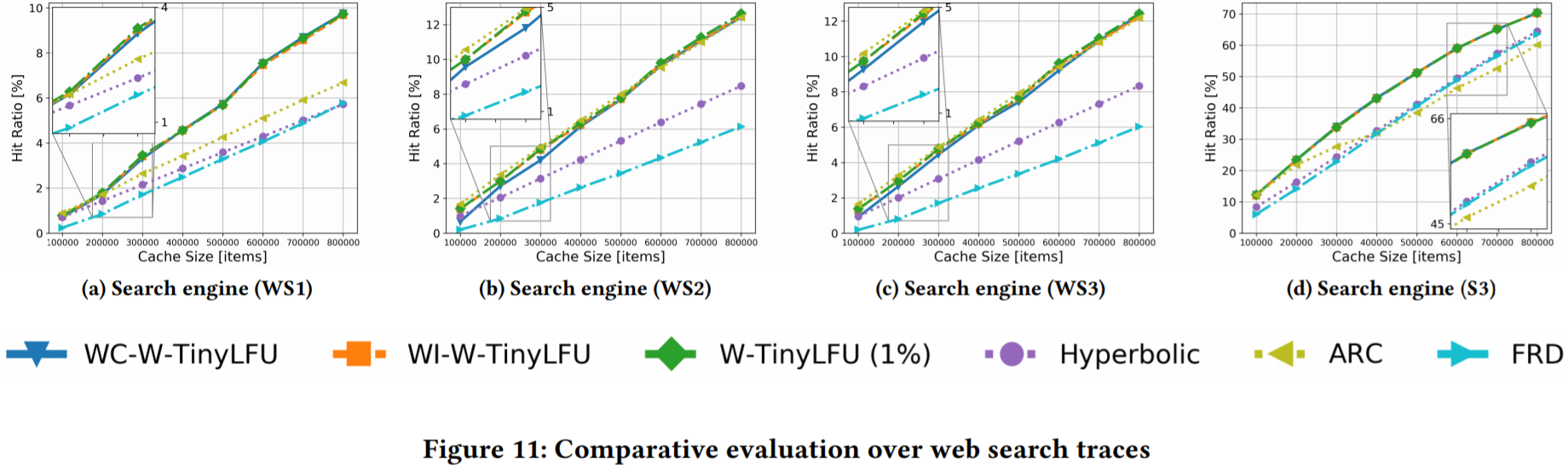
本章中,我们将W-TinyLFU, WI-W-TinyLFU, WC-WTinyLFU和FRD与其他主要成果进行比较:ARC[24]和Hyperbolic缓存。
网页查找追踪。网页查找追踪通常基于频率,服务器会聚合来自很多用户的查询。图11展示了基于网页查找追踪的相对评估。可以看到基于W-TinyLFU框架的曲线总是位于最上方。相反,在这些负载下,FRD和hyperbolic则是最差的。ARC在WS2追踪(图11b)和WS3追踪(图11c)中具有竞争力,但在WS1追踪(图11a)和S3追踪(图11d)中相对滞后。在这些追踪中,W-TinyLFU是最好的(与我们的自适应策略展示出的性能非常接近)。
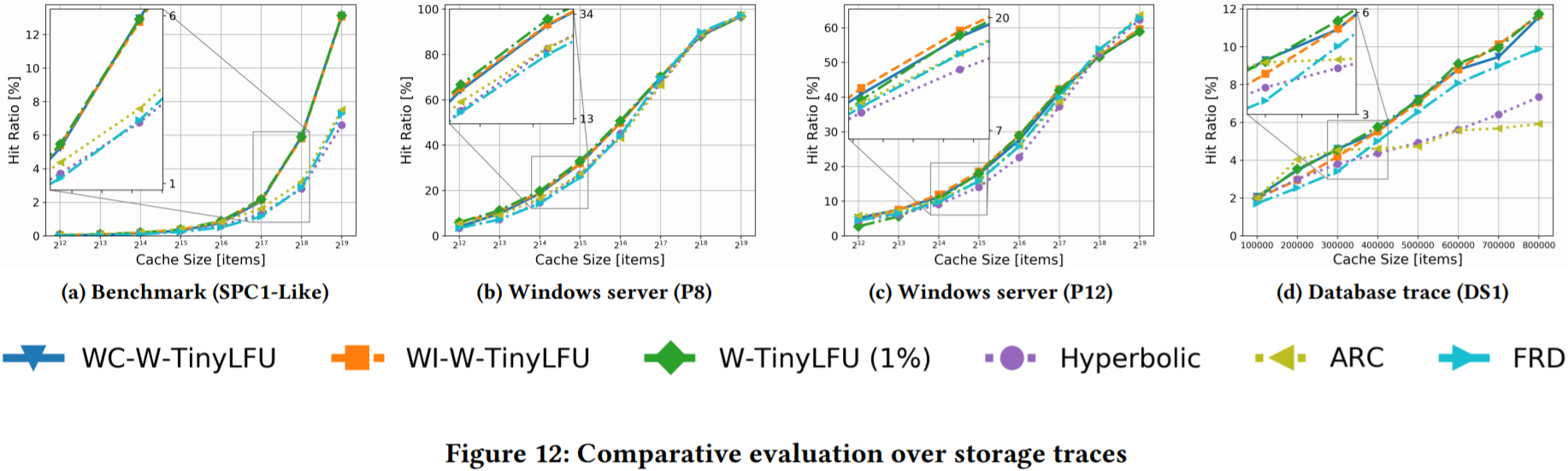
存储追踪。图12展示了大量存储追踪的结果,包括对Windows服务器、数据库以及一个基准。在SPC1-Like的基准追踪中(图12a),WI-W-TinyLFU、WC-W-TinyLFU 和 W-TinyLFU作为了领先策略,而FRD、Hyperbolic和ARC则相对滞后。
在Windows服务器追踪P8(图12b)和P12(图12c)中,在缓存较少时,基于W-TinyLFU框架较优。对于较大的缓存,在P8中,所有的策略都展示了相同的命中率,在P12中,其他策略比ARC、FRD和hyperbolic缓存有2%的优势。总之,在这些追踪中没有明显的胜出者。
在数据库追踪DS1(图12d)中,W-TinyLFU 和 WC-WTinyLFU 展示了高命中率且几乎无法区分(WI-W-TinyLFU稍差一些,再往下是FRD)。然而,可以认为所有的W-TinyLFU都要优于Hyperbolic缓存和ARC。
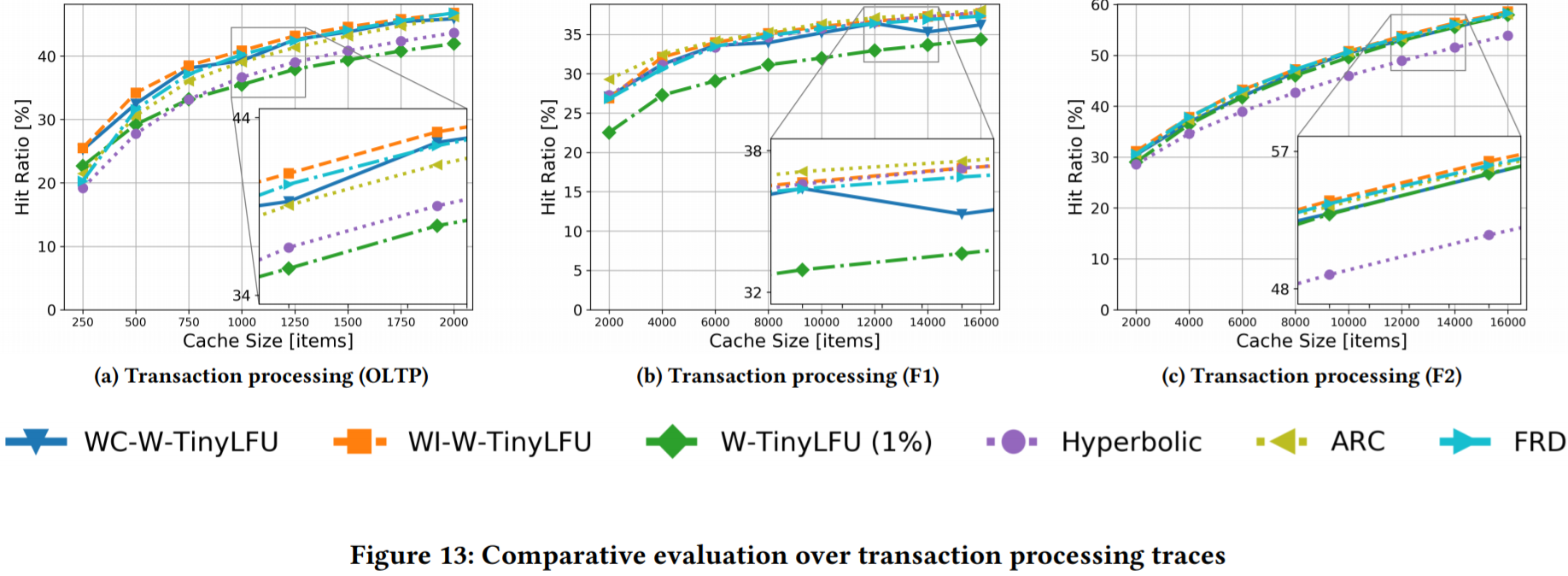
事务处理。图13展示了基于事务处理追踪的评估。这类追踪经常会表现为最近和最常访问的结合。ARC在所有这些追踪中具有竞争力,非自适应的W-TinyLFU在OLTP追踪(图13a)和F1追踪(图13b)中相对滞后。相比之下,我们的自适应算法(WI-W-TinyLFU 和 WC-W-TinyLFU)和FRD非常接近ARC。在所有这些追踪中,我们的算法要么略优于ARC(OLTP和F2)要么略差于ARC(F1),但幅度不超过1%。相比之下,Hyperbolic缓存只在F1追踪和中具有优势,W-TinyLFU只在F2追踪中具有优势。
其他追踪。图14展示了对其他类型的追踪的评估,包括Wikipedia, Gradle, 和 Scarab。在Wikipedia追踪中(图14a),所有框架的执行结果相似,Hyperbolic缓存稍差。
对于Gradle追踪(图14b),默认的W-TinyLFU是最差的。这类追踪非常偏向最近访问,所有访问都会请求最近的构建。因此,一个被访问很多次的构建,并不意味着未来也会再次被访问。WI-W-TinyLFU 和 WC-W-TinyLFU的性能重叠,与ARC、Hyperbolic 和FRD的性能差距不超过1%。
在Scarab追踪中(图14c),Hyperbolic是最差的,但所有其他策略的命中率非常相似,且最多比FRD差1%。

5.8 性能评估
最后我们评估我们自适应策略的计算开销。我们测量实际追踪的完成时间,同时模拟各种主存选项下由于缓存未命中造成的延迟。我们将未命中延迟对应到SSD访问、数据中心访问、磁盘访问和WAN(到荷兰的CA)访问(见[27]的基准项目报告)。我们还实验了0未命中惩罚选项,称为"none",它捕获到的缓存管理框架的性能开销最小。直观上,由于与未命中惩罚相比,计算开销可以忽略不计,因此完成时间由命中率占主导地位。但如果策略过于复杂,即时命中率很高,也有可能产生较长的完成时间。我们在Intel i5-6500 CPU @ 3.20GHz 单核系统上进行测量。
图15展示了在OLTP追踪(图15a)和S3追踪(图15b)中的评估结果。通过查看"none"未命中惩罚表,可以看到Hyperbolic缓存是最具计算密集型的策略,而ARC则是最不具计算密集型的策略。WC-W-TinyLFU几乎与W-TinyLFU完全相同,WI-W-TinyLFU几乎则计算密集一些。所有自适应框架都展示了每秒100百万次的缓存访问。
下面,我们检验了OLTP追踪(图15a),此时WC-WTinyLFU 和 WI-W-TinyLFU展现了最高的命中率,正如我们看到的,这两个策略同时也给出了最小的完成时间。当检验S3追踪(图15b)时,我们发现,W-TinyLFU的命中率最高,同时其完成时间也最小。可以看到,我们的自适应策略对完成时间的影响非常小,因此在这种情况下保证了W-TinyLFU的良好特性。总之,评估表明我们的自适应策略的计算开销即时在使用DRAM缓存(主存为SSD)时也不会太高。

命中率越高,未命中造成的惩罚越小
6 讨论
正如前面展示的,不存在事先对缓存管理策略进行静态配置,就可以在任何负载上获得最佳缓存3命中率的情况。
因此,为了给特定系统确定最佳策略,需要仔细研究其负载的工作方式,以及各种策略在这些负载上的性能指标。然而,期望开发人员在每个系统上进行如此详细的研究可能不太现实,而且实际中,有可能事先无法了解负载。本文中,我们探究了最近访问 vs 最常访问负载下的动态适应缓存管理策略。在实验方案上,我们采用了爬山方法和指示器框架,并将这些方案应用在W-TinyLFU和FRD策略中[13,25]。
通过检查调节各种策略参数带来的好处,我们得出修改W-TinyLFU的window大小比调节sketch参数对结果的影响更大。特别是对应的自适应框架WC-W-TinyLFU和WI-W-TinyLFU(分别对应window爬山和window指示器),在所有实验中保持了竞争力(且成为最佳策略),同时在所有W-TinyLFU成为胜出者的场景下,它们的性能也不会下降。在FRD场景中,即使在从最优配置开始时,自适应框架也能够与[25]中的推荐的静态配置相媲美。这些迹象高度表明在事先不了解负载(以及不需要在不同的负载中尝试不同配置)的情况下,也可以通过自适应获得最好的结果。在CPU开销方面,经过评估发现,完成时间主要受命中率的影响,且我们的框架的计算开销可以忽略不计(无论未命中惩罚来自SSD、数据中心、磁盘或WAN的访问)。
在比较爬山和指示器方式时发现,后者得到的结果略好,且适应性更快(单步中)。但爬山更容易实验,且需要的空间更少。因此,在资源有限的环境中,爬山可能更合适。
本论文使用的全部代码以及测试配置已经开源[12]。
引用
[1] Akhtar, S., Beck, A., and Rimac, I. Caching online video: Analysis and proposed algorithm. ACM Trans. Multimedia Comput. Commun. Appl. 13, 4 (Aug. 2017),48:1–48:21.
[2] Arlitt, M., Cherkasova, L., Dilley, J., Friedrich, R., and Jin, T. Evaluating content management techniques for web proxy caches. In In Proc. of the 2nd Workshop on Internet Server Performance (1999).
[3] Arlitt, M., Friedrich, R., and Jin, T. Performance evaluation of web proxy cache replacement policies. Perform. Eval. 39, 1-4 (Feb. 2000), 149–164.
[4] Bansal, S., and Modha, D. S. Car: Clock with adaptive replacement. In *Proc. of the 3rd USENIX Conf. on File and Storage Technologies (FAST) (2004), pp. 187–200.
[5] Belady, L. A. A study of replacement algorithms for a virtual-storage computer.IBM Systems Journal 5, 2 (1966), 78–101.
[6] Berger, D. S., Sitaraman, R. K., and Harchol-Balter, M. Adaptsize: Orchestrating the hot object memory cache in a content delivery network. In
14th USENIX Symposium on Networked Systems Design and Implementation NSDI(2017), pp. 483–498.
[7] Blankstein, A., Sen, S., and Freedman, M. J. Hyperbolic caching: Flexible caching for web applications. In 2017 USENIX Annual Technical Conference (USENIX ATC) (2017), pp. 499–511.
[8] Cheng, Y., Douglis, F., Shilane, P., Wallace, G., Desnoyers, P., and Li, K.Erasing belady’s limitations: In search of flash cache offline optimality. In Proc. of USENIX Annual Technical Conference (ATC) (2016), pp. 379–392.
[9] Cherkasova, L. Improving www proxies performance with greedy-dual-sizefrequency caching policy. Tech. rep., In HP Tech. Report, 1998.
[10] Cohen, S., and Matias, Y. Spectral bloom filters. In Proc. of the ACM SIGMOD Int. Conf. on Management of data (2003), pp. 241–252.
[11] Cormode, G., and Muthukrishnan, S. An improved data stream summary: The count-min sketch and its applications. J. Algorithms 55, 1 (Apr. 2005), 58–75.
[12] Einziger, G., Eytan, O., Friedman, R., and Manes, B. Codebase and traces used in this work. https://www.cs.technion.ac.il/~ohadey/adaptive-caching/AdaptiveSoftwareCacheManagementMiddleware2018.html, 2018.
[13] Einziger, G., Friedman, R., and Manes, B. Tinylfu: A highly efficient cache admission policy. ACM Transactions on Storage (TOS) (2017).
[14] Hennessy, J. L., and Patterson, D. A. Computer Architecture - A Quantitative Approach (5. ed.). Morgan Kaufmann, 2012.
[15] Huang, S., Wei, Q., Feng, D., Chen, J., and Chen, C. Improving flash-based disk cache with lazy adaptive replacement. ACM Trans. on Storage (ToS) 12, 2 (Feb.2016).
[16] Jiang, S., and Zhang, X. LIRS: an efficient low inter-reference recency set replacement policy to improve buffer cache performance. In Proc. of the International Conference on Measurements and Modeling of Computer Systems SIGMETRICS
(June 2002), pp. 31–42.
[17] Karakostas, G., and Serpanos, D. N. Exploitation of different types of locality for web caches. In Proc. of the 7th Int. Symposium on Computers and Communications (ISCC) (2002).
[18] Ketan Shah, A., and Matani, M. D. An o(1) algorithm for implementing the lfu cache eviction scheme. Tech. rep., 2010. "http://dhruvbird.com/lfu.pdf".
[19] Lee, D., Choi, J., Kim, J., Noh, S. H., Min, S. L., Cho, Y., and Kim, C. LRFU: A spectrum of policies that subsumes the least recently used and least frequently used policies. IEEE Trans. Computers 50, 12 (2001), 1352–1361.
[20] Li, C. DLIRS: Improving low inter-reference recency set cache replacement policy with dynamics. In Proc. of the 11th ACM International Systems and Storage Conference (SYSTOR) (June 2018).
[21] Li, C., Shilane, P., Douglis, F., and Wallace, G. Pannier: Design and analysis of a container-based flash cache for compound objects. ACM Trans. on Storage (ToN) 13, 3 (Sept. 2017).
[22] Liberatore, M., and Shenoy, P. Umass trace repository.http://traces.cs.umass.edu/index.php/Main/About, 2016.
[23] Manes, B. Caffeine: A high performance caching library for java 8. https://github.com/ben-manes/caffeine (2016).
[24] Megiddo, N., and Modha, D. S. Arc: A self-tuning, low overhead replacement cache. In Proc. of the 2nd USENIX Conf. on File and Storage Technologies (FAST) (2003), pp. 115–130.
[25] Park, S., and Park, C. FRD: A filtering based buffer cache algorithm that considers both frequency and reuse distance. In Proc. of the 33rd IEEE International Conference on Massive Storage Systems and Technology (MSST) (2017).
[26] Russell, S. J., and Norvig, P. *Artificial Intelligence: A Modern Approach (2nd ed.).Prentice Hall, 2010.
[27] Scott, C. Latency numbers every programmer should know. https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html.
[28] Subramanian, R., Smaragdakis, Y., and Loh, G. H. Adaptive caches: Effective shaping of cache behavior to workloads. In Proc. of the 39th Annual IEEE/ACM International Symposium on Microarchitecture (2006), MICRO, pp. 385–396.
[29] Urdaneta, G., Pierre, G., and van Steen, M. Wikipedia workload analysis for decentralized hosting. Elsevier Computer Networks 53, 11 (July 2009), 1830–1845.
[30] Vietri, G., Rodriguez, L. V., Martinez, W. A., Lyons, S., Liu, J., Rangaswami, R.,Zhao, M., and Narasimhan, G. Driving cache replacement with ml-based lecar.In 10th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage) (2018).
[31] Waldspurger, C., Saemundsson, T., Ahmad, I., and Park, N. Cache modeling and optimization using miniature simulations. In 2017 USENIX Annual Technical Conference (USENIX ATC 17) (Santa Clara, CA, 2017), USENIX Association, pp. 487–498.
[32] Young, N. On-line caching as cache size varies. In Proc. of the second annual ACM-SIAM symposium on Discrete algorithms (SODA) (1991), pp. 241–250.