一、为何要做CMDB系统?
1、搭建运维自动化平台的基础,需要将资产管控起来
2、资产管理:实现资产自动汇报,得到资产最新信息和变更记录
3、CMDB工具中至少包含这几种关键的功能:整合、调和、同步、映射和可视化;
-
整合是指能够充分利用来自其他数据源的信息,对CMDB中包含的记录源属性进行存取,将多个数据源合并至一个视图中,生成连同来自CMDB和其他数据源信息在内的报告;
-
调和能力是指通过对来自每个数据源的匹配字段进行对比,保证CMDB中的记录在多个数据源中没有重复现象,维持CMDB中每个配置项目数据源的完整性;自动调整流程使得初始实施、数据库管理员的手动运作和现场维护支持工作降至最低;
-
同步指确保CMDB中的信息能够反映联合数据源的更新情况,在联合数据源更新频率的基础上确定CMDB更新日程,按照经过批准的变更来更新 CMDB,找出未被批准的变更;
-
应用映射与可视化,说明应用间的关系并反应应用和其他组件之间的依存关系,了解变更造成的影响并帮助诊断问题。
二、资产采集的四种方式
前三种方法中的软件都是用Python写的,都要掌握流程,第四种了解即可;
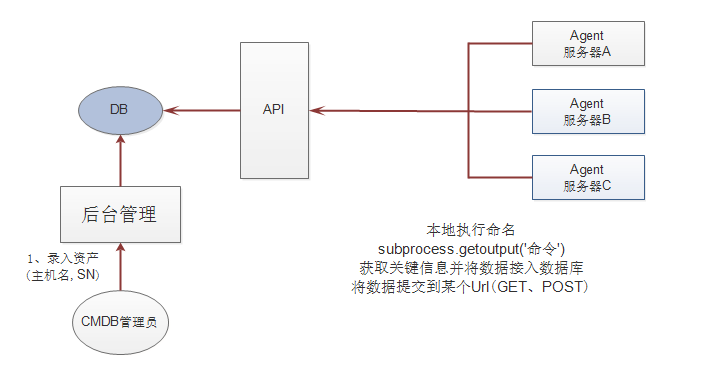
1、Agent方式:CMDB后台管理-》API-》服务器(agent软件,定时任务)
-
- API:一个Django程序,客户端软件将数据提交给URL,URL把数据写入数据库,避免直接接触数据库
-
- 快
-
- 依赖agent软件
-
- 如果数据库修改了密码,每个agent都要修改,agent被破解了,密码外泄
import subprocess import requests # ************ 采集数据 ************ ret = subprocess.getoutput('ipconfig') # ************ 整理数据 ************ # ret正则筛选,获取想要的数据,整理成字典格式 data_dict = { 'nic':{}, 'disk':{}, 'mem':{}, } # ************ 发送数据 ************ requests.post('http://www.127.0.0.1:8000/assets.html',data=data_dict)
2、Ssh类方式:CMDB后台管理-》API-》采集资产(中控机服务器,ssh链接:依赖paramiko)-》服务器(一天取一次数据)
-
- 慢
-
- 不依赖任何软件
-
- 公司服务器少时用

# 基于paramiko import paramiko import requests # ************ 获取今天未采集数据的主机名 ************ ret = requests.get('http://www.127.0.0.1:8000/assets.html') # ret = ['c1.com','c2.com',] # ************ 通过paramiko远程连接服务器,执行命令 ************ # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname='c1.salt.com', port=22, username='charlie', password='123') # 执行命令 stdin, stdout, stderr = ssh.exec_command('df') # 获取命令结果 result = stdout.read() # 关闭连接 ssh.close() # result格式化处理后发送 # ************ 发送数据 ************ requests.post('http://www.127.0.0.1:8000/assets.html',data=result)
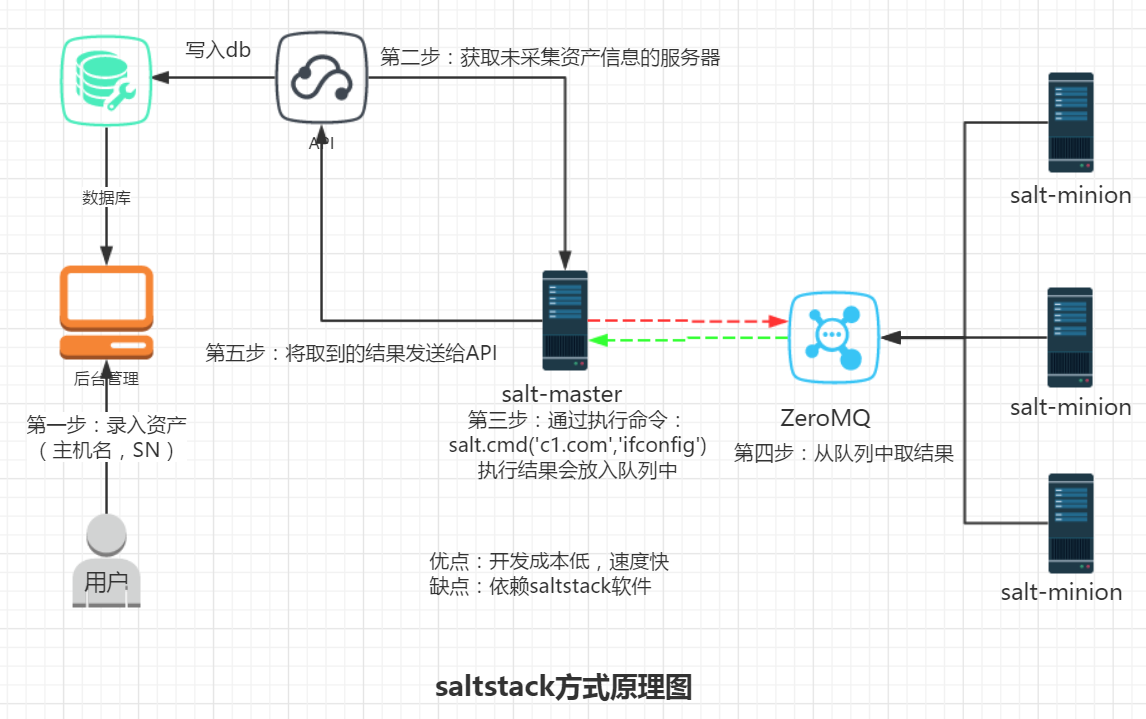
3、SaltStack方式:CMDB后台管理-》API-》第三方软件(saltstack-master:队列方式)-》服务器(saltstack-slave)
-
- 快,开发成本低
-
- 依赖saltstack
-
- 运维公司首选
# 安装:rpm --import https://repo.saltstack.com/yum/redhat/6/x86_64/latest/SALTSTACK-GPG-KEY.pub # Master:yum install salt-master # Slave:yum install salt-minion import requests import subprocess # ************ 获取未采集数据的主机名 ************ ret = requests.get('http://www.127.0.0.1:8000/assets.html') # ret = ['c1.com','c2.com',] # ************ 远程连接服务器,执行命令,采集数据 ************ # 方法一 result = subprocess.getoutput("salt 'c1.com' cdm.run 'ifconfig'") # 方法二:基于SaltStack的master上的pillar以及远程执行命令实现 import salt.client local = salt.client.LocalClient() data_dict = local.cmd('*', 'cmd.run', ['whoami']) # ************ 发送数据 ************ requests.post('http://www.127.0.0.1:8000/assets.html',data=data_dict)
4、Puppet方式:CMDB后台管理-》API-》第三方软件(puppet)-》服务器
-
- 缺点:puppet软件上的所有程序都要用ruby语言开发
-
- 优点:简单,自动汇报
三、SaltStack准备流程:
1、安装saltstack:
- yum install https://repo.saltstack.com/yum/redhat/salt-repo-latest.el7.noarch.rpm
- yum install salt-master(服务器)
- yum install salt-minion(客户端)
2、服务端准备:
a.配置文件,监听本机IP:vim /etc/salt/master ==》interface:改成本机的IP
b.运行服务端:/etc/init.d/salt-master start
3、准备客户端
a.配置文件,链接服务端IP:vim /etc/salt/master ==》interface:改成服务器的IP
b.运行客户端:/etc/init.d/salt-minion start
4、服务端命令
- salt-key -L 查看当前来连接的客户端
- salt-key -a c1.com 接收c1的链接
- salt 'c1.com' cmd.run 'ifconfig' 在服务端控制客户端远程执行命令
5、选择服务器唯一标识的两种情况
如果公司的物理机和虚拟机都要做资产管理:
主机名为唯一标识,运维部门首先要制定规则,主机名不能重复,重装系统时规定该机器的主机名与原来相同,不能随意修改文件中的主机名;
如果虚拟机不算公司资产:
直接以电脑的sn号为唯一标识,进行资产管理
四、项目实战
1、数据库表设计

项目总结:
1、通过配置文件中的MODE参数判断当前是什么模式,只支持三种Agent,Salt,SSH
2、根据模式创建对应的对象,并调用对象的process方法
3、process方法调用pack方法,pack方法会根据配置文件中的需要采集的资产列表PLUGINS来采集相应的资产信息,
比如硬盘,网卡等,pack方法会返回一个字典;
4、如果是agent方式,就获取当前的主机名,把主机名加入到pack方法返回的字典中
如果是ssh类和saltstack方式,就要先获取当前未采集资产的主机列表,然后循环主机列表,分别采集每台主机的资产信息
5、最后把资产信息字典发送到API,经过加密cookie+时间限制+访问记录的三重验证,最后API负责入库;
6、亮点:
- 支持三种采集资产的方式,只需要修改配置文件就可以同时兼容,方便;
- 加密cookie+时间限制+访问记录的API三重验证,最大限度的保证了数据库的安全
- 后台管理模块,通过前端和后台的配置,可以实现一个公共的组件,告别基本的CURD,直接在页面上操作,更加直观和方便,还可以生成动态的图表,实时的获取资产信息
7、需要注意的是:
- 如果公司的物理机和虚拟机都要做资产管理:
主机名为唯一标识,运维部门首先要制定规则,主机名不能重复,重装系统时规定该机器的主机名与原来相同,不能随意修改文件中的主机名;
- 如果虚拟机不算公司资产:
直接以电脑的sn号为唯一标识,进行资产管理