之前有一篇文章,说了RPC的内容:
http://www.cnblogs.com/charlesblc/p/6214391.html
如果有一种方式能让我们像调用本地服务一样调用远程服务,而让调用者对网络通信这些细节透明,那么将大大提高生产力,比如服务消费方在执行helloWorldService.sayHello("test")时,实质上调用的是远端的服务。这种方式其实就是RPC(Remote Procedure Call Protocol),在各大互联网公司中被广泛使用,如阿里巴巴的hsf、dubbo(开源)、Facebook的thrift(开源)、Google grpc(开源)、Twitter的finagle(开源)等。
要让网络通信细节对使用者透明,我们需要对通信细节进行封装,我们先看下一个RPC调用的流程涉及到哪些通信细节:
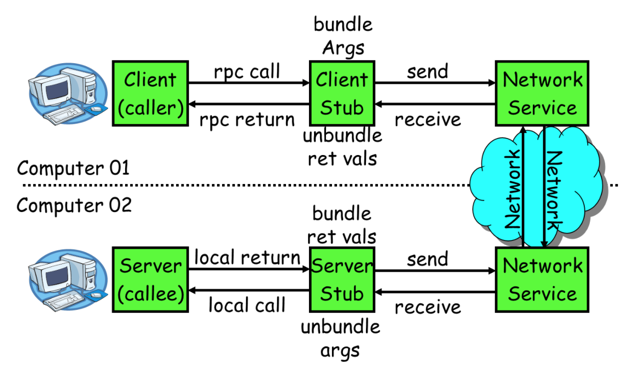
整体过程
1)服务消费方(client)调用以本地调用方式调用服务;
2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
3)client stub找到服务地址,并将消息发送到服务端;
4)server stub收到消息后进行解码;
5)server stub根据解码结果调用本地的服务;
6)本地服务执行并将结果返回给server stub;
7)server stub将返回结果打包成消息并发送至消费方;
8)client stub接收到消息,并进行解码;
9)服务消费方得到最终结果。
RPC的目标就是要2~8这些步骤都封装起来,让用户对这些细节透明。
1.1 怎么做到透明化远程服务调用?
对java来说就是使用代理!java代理有两种方式:1) jdk 动态代理;2)字节码生成。尽管字节码生成方式实现的代理更为强大和高效,但代码维护不易,大部分公司实现RPC框架时还是选择动态代理方式。
public class RPCProxyClient implements java.lang.reflect.InvocationHandler{ private Object obj; public RPCProxyClient(Object obj){ this.obj=obj; } /** * 得到被代理对象; */ public static Object getProxy(Object obj){ return java.lang.reflect.Proxy.newProxyInstance(obj.getClass().getClassLoader(), obj.getClass().getInterfaces(), new RPCProxyClient(obj)); } /** * 调用此方法执行 */ public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { //结果参数; Object result = new Object(); // ...执行通信相关逻辑 // ... return result; } }
newProxyInstance 这个方法的作用就是得到一个动态的代理对象,其接收三个参数,我们来看看这三个参数所代表的含义:

public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h) throws IllegalArgumentException loader: 一个ClassLoader对象,定义了由哪个ClassLoader对象来对生成的代理对象进行加载 interfaces: 一个Interface对象的数组,表示的是我将要给我需要代理的对象提供一组什么接口,如果我提供了一组接口给它,那么这个代理对象就宣称实现了该接口(多态),这样我就能调用这组接口中的方法了 h: 一个InvocationHandler对象,表示的是当我这个动态代理对象在调用方法的时候,会关联到哪一个InvocationHandler对象上
调用:
public class Test { public static void main(String[] args) { HelloWorldService helloWorldService = (HelloWorldService)RPCProxyClient.getProxy(HelloWorldService.class); helloWorldService.sayHello("test"); } }
1.2.1 确定消息数据结构
1)接口名称 在我们的例子里接口名是“HelloWorldService”,如果不传,服务端就不知道调用哪个接口了; 2)方法名 一个接口内可能有很多方法,如果不传方法名服务端也就不知道调用哪个方法; 3)参数类型&参数值 参数类型有很多,比如有bool、int、long、double、string、map、list,甚至如struct(class); 以及相应的参数值; 4)超时时间 5)requestID,标识唯一请求id,在下面一节会详细描述requestID的用处。
同理服务端返回的消息结构一般包括以下内容。
1)返回值 2)状态code 3)requestID
1.2.2 序列化
一旦确定了消息的数据结构后,下一步就是要考虑序列化与反序列化了。
目前互联网公司广泛使用Protobuf、Thrift、Avro等成熟的序列化解决方案来搭建RPC框架,这些都是久经考验的解决方案。
1.3 通信
如何实现RPC的IO通信框架呢?1)使用java nio方式自研,这种方式较为复杂,而且很有可能出现隐藏bug,但也见过一些互联网公司使用这种方式;2)基于mina,mina在早几年比较火热,不过这些年版本更新缓慢;3)基于netty,现在很多RPC框架都直接基于netty这一IO通信框架,省力又省心,比如阿里巴巴的HSF、dubbo,Twitter的finagle等。
1.4 消息里为什么要有requestID?
用来进行消息和处理线程的匹配对应。
2 如何发布自己的服务?
这里问题的关键在于是自动告知还是人肉告知。
有没有一种方法能实现自动告知,即机器的增添、剔除对调用方透明,调用者不再需要写死服务提供方地址?当然可以,现如今zookeeper被广泛用于实现服务自动注册与发现功能!
简单来讲,zookeeper可以充当一个服务注册表(Service Registry),让多个服务提供者形成一个集群,让服务消费者通过服务注册表获取具体的服务访问地址(ip+端口)去访问具体的服务提供者。
具体来说,zookeeper就是个分布式文件系统,每当一个服务提供者部署后都要将自己的服务注册到zookeeper的某一路径上: /{service}/{version}/{ip:port}, 比如我们的HelloWorldService部署到两台机器,那么zookeeper上就会创建两条目录:分别为/HelloWorldService/1.0.0/100.19.20.01:16888 /HelloWorldService/1.0.0/100.19.20.02:16888。
zookeeper提供了“心跳检测”功能,它会定时向各个服务提供者发送一个请求(实际上建立的是一个 Socket 长连接),如果长期没有响应,服务中心就认为该服务提供者已经“挂了”,并将其剔除,比如100.19.20.02这台机器如果宕机了,那么zookeeper上的路径就会只剩/HelloWorldService/1.0.0/100.19.20.01:16888。
服务消费者会去监听相应路径(/HelloWorldService/1.0.0),一旦路径上的数据有任务变化(增加或减少),zookeeper都会通知服务消费方服务提供者地址列表已经发生改变,从而进行更新。
更为重要的是zookeeper与生俱来的容错容灾能力(比如leader选举),可以确保服务注册表的高可用性。
(完)