今天学习这篇文章:
https://zhuanlan.zhihu.com/p/42214716
昨天的文章也没有看完,有机会再看:
https://zhuanlan.zhihu.com/p/41663141
先来这张经典的图:
文本要实现的深度学习模型是阿里巴巴的算法工程师18年刚发表的论文《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》中提出的ESMM模型,关于该模型的详细介绍可以参考我之前的一篇文章:《CVR预估的新思路:完整空间多任务模型》。
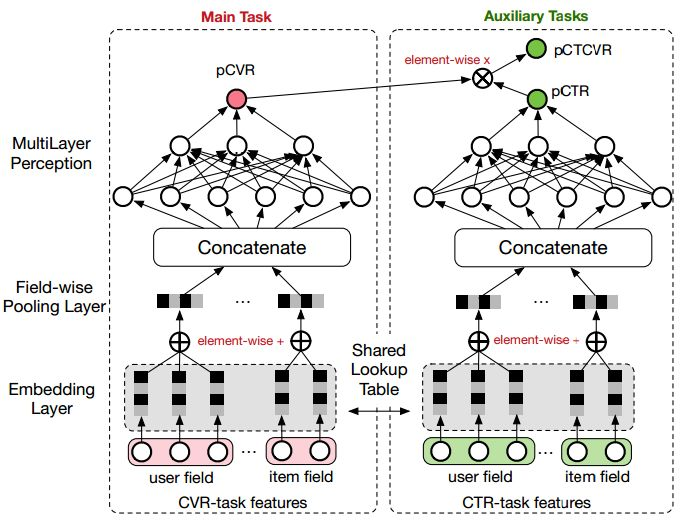
ESMM模型是一个多任务学习(Multi-Task Learning)模型,它同时学习学习点击率和转化率两个目标,即模型直接预测展现转换率(pCTCVR):单位流量获得成交的概率。模型的结构如图1所示。
先看这篇文章:
https://zhuanlan.zhihu.com/p/37562283
ESMM模型创新地利用用户行为序列数据,在完整的样本数据空间同时学习点击率和转化率(post-view clickthrough&conversion rate,CTCVR),解决了传统CVR预估模型难以克服的样本选择偏差(sample selection bias)和训练数据过于稀疏(data sparsity )的问题。
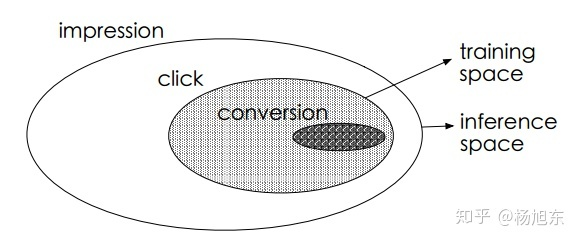
换句话说,用户行为遵循一定的顺序决策模式:impression → click → conversion。CVR模型旨在预估用户在观察到曝光商品进而点击到商品详情页之后购买此商品的概率,即pCVR = p(conversion|click,impression)。
传统的CVR预估任务通常采用类似于CTR预估的技术,比如最近很流行的深度学习模型。然而,有别于CTR预估任务,CVR预估任务面临一些特有的挑战:1) 样本选择偏差;2) 训练数据稀疏;3) 延迟反馈等。
按这种方法构建的训练样本集相当于是从一个与真实分布不完全一致的分布中采样得到的,这一定程度上违背了机器学习算法之所以有效的前提:训练样本与测试样本必须独立地采样自同一个分布,即独立同分布的假设。总结一下,训练样本从整体样本空间的一个较小子集中提取,而训练得到的模型却需要对整个样本空间中的样本做推断预测的现象称之为样本选择偏差。样本选择偏差会伤害学到的模型的泛化性能。
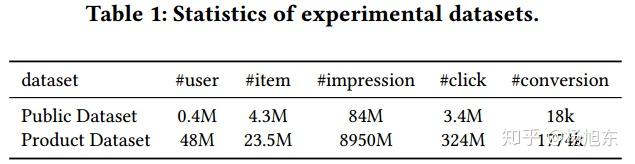
推荐系统展现给用户的商品数量要远远大于被用户点击的商品数量,同时有点击行为的用户也仅仅只占所有用户的一小部分,因此有点击行为的样本空间 相对于整个样本空间
来说是很小的,通常来讲,量级要少1~3个数量级。如表1所示,在淘宝公开的训练数据集上,
只占整个样本空间
的4%。这就是所谓的训练数据稀疏的问题,高度稀疏的训练数据使得模型的学习变得相当困难。
阿里妈妈的算法同学提出的ESMM模型借鉴了多任务学习的思路,引入了两个辅助的学习任务,分别用来拟合pCTR和pCTCVR,从而同时消除了上文提到的两个挑战。ESMM模型能够充分利用用户行为的顺序性模式,其模型架构如图2所示。
- 在整个样本空间建模。由下面的等式可以看出,pCVR 可以在先估计出pCTR 和pCTCVR之后推导出来。从原理上来说,相当于分别单独训练两个模型拟合出pCTR 和pCTCVR,再通过pCTCVR 除以pCTR 得到最终的拟合目标pCVR 。
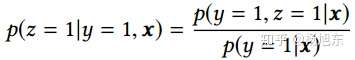
但是,由于pCTR 通常很小,除以一个很小的浮点数容易引起数组不稳定问题(计算内存溢出)。所以ESMM模型采用了乘法的形式,而没有采用除法形式。
pCTR 和pCTCVR 是ESMM模型需要估计的两个主要因子,而且是在整个样本空间上建模得到的,pCVR 只是一个中间变量。由此可见,ESMM模型是在整个样本空间建模,而不像传统CVR预估模型那样只在点击样本空间建模。
- 共享特征表示。ESMM模型借鉴迁移学习的思路,在两个子网络的embedding层共享embedding向量(特征表示)词典。网络的embedding层把大规模稀疏的输入数据映射到低维的表示向量,该层的参数占了整个网络参数的绝大部分,需要大量的训练样本才能充分学习得到。由于CTR任务的训练样本量要大大超过CVR任务的训练样本量,ESMM模型中特征表示共享的机制能够使得CVR子任务也能够从只有展现没有点击的样本中学习,从而能够极大地有利于缓解训练数据稀疏性问题。
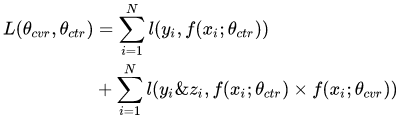
ESMM模型是一个新颖的CVR预估方法,其首创了利用用户行为序列数据在完整样本空间建模,避免了传统CVR模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果。另一方面,ESMM模型的贡献在于其提出的利用学习CTR和CTCVR的辅助任务,迂回地学习CVR的思路。ESMM模型中的BASE子网络可以替换为任意的学习模型,因此ESMM的框架可以非常容易地和其他学习模型集成,从而吸收其他学习模型的优势,进一步提升学习效果,想象空间巨大。
回到这一篇:
https://zhuanlan.zhihu.com/p/42214716
SMM模型有两个主要的特点:
- 在整个样本空间建模。区别与传统的CVR预估方法通常使用“点击->成交”事情的日志来构建训练样本,ESMM模型使用“展现->点击->成交”事情的日志来构建训练样本。
- 共享特征表示。两个子任务(CTR预估和CVR预估)之间共享各类实体(产品、品牌、类目、商家等)ID的embedding向量表示。
ESMM模型的损失函数由两部分组成,对应于pCTR 和pCTCVR 两个子任务,其形式如下:
其中, 和
分别是CTR网络和CVR网络的参数,
是交叉熵损失函数。在CTR任务中,有点击行为的展现事件构成的样本标记为正样本,没有点击行为发生的展现事件标记为负样本;在CTCVR任务中,同时有点击和购买行为的展现事件标记为正样本,否则标记为负样本。
ESMM模型由两个结构完全相同的子网络连接而成,我们把子网络对应的模型称之为Base模型。接下来,我们先介绍下如何用tensorflow实现Base模型。
实现embedding layer需要用到tf.feature_column.embedding_column或者tf.feature_column.shared_embedding_columns,这里因为我们希望user field和item field的同一类型的实体共享相同的embedding映射空间,所有选用tf.feature_column.shared_embedding_columns。由于shared_embedding_columns函数只接受categorical_column列表作为参数,因此需要为原始特征数据先创建categorical_columns。
那么,如何实现field-wise pooling layer呢?其实,在用tf.feature_column.embedding_column或者tf.feature_column.shared_embedding_columnsAPI时不需要另外实现pooling layer,因为这2个函数同时实现了embedding向量映射和field-wise pooling。大家可能已经主要到了shared_embedding_columns函数的combiner='sum'参数,这个参数就指明了当该field有多个embedding向量时融合为唯一一个向量的操作,'sum'操作即element-wise add。
def build_mode(features, mode, params): net = fc.input_layer(features, params['feature_columns']) # Build the hidden layers, sized according to the 'hidden_units' param. for units in params['hidden_units']: net = tf.layers.dense(net, units=units, activation=tf.nn.relu) if 'dropout_rate' in params and params['dropout_rate'] > 0.0: net = tf.layers.dropout(net, params['dropout_rate'], training=(mode == tf.estimator.ModeKeys.TRAIN)) # Compute logits logits = tf.layers.dense(net, 1, activation=None) return logits def my_model(features, labels, mode, params): with tf.variable_scope('ctr_model'): ctr_logits = build_mode(features, mode, params) with tf.variable_scope('cvr_model'): cvr_logits = build_mode(features, mode, params) ctr_predictions = tf.sigmoid(ctr_logits, name="CTR") cvr_predictions = tf.sigmoid(cvr_logits, name="CVR") prop = tf.multiply(ctr_predictions, cvr_predictions, name="CTCVR") if mode == tf.estimator.ModeKeys.PREDICT: predictions = { 'probabilities': prop, 'ctr_probabilities': ctr_predictions, 'cvr_probabilities': cvr_predictions } export_outputs = { 'prediction': tf.estimator.export.PredictOutput(predictions) } return tf.estimator.EstimatorSpec(mode, predictions=predictions, export_outputs=export_outputs) y = labels['cvr'] cvr_loss = tf.reduce_sum(tf.keras.backend.binary_crossentropy(y, prop), name="cvr_loss") ctr_loss = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(labels=labels['ctr'], logits=ctr_logits), name="ctr_loss") loss = tf.add(ctr_loss, cvr_loss, name="ctcvr_loss") ctr_accuracy = tf.metrics.accuracy(labels=labels['ctr'], predictions=tf.to_float(tf.greater_equal(ctr_predictions, 0.5))) cvr_accuracy = tf.metrics.accuracy(labels=y, predictions=tf.to_float(tf.greater_equal(prop, 0.5))) ctr_auc = tf.metrics.auc(labels['ctr'], ctr_predictions) cvr_auc = tf.metrics.auc(y, prop) metrics = {'cvr_accuracy': cvr_accuracy, 'ctr_accuracy': ctr_accuracy, 'ctr_auc': ctr_auc, 'cvr_auc': cvr_auc} tf.summary.scalar('ctr_accuracy', ctr_accuracy[1]) tf.summary.scalar('cvr_accuracy', cvr_accuracy[1]) tf.summary.scalar('ctr_auc', ctr_auc[1]) tf.summary.scalar('cvr_auc', cvr_auc[1]) if mode == tf.estimator.ModeKeys.EVAL: return tf.estimator.EstimatorSpec(mode, loss=loss, eval_metric_ops=metrics) # Create training op. assert mode == tf.estimator.ModeKeys.TRAIN optimizer = tf.train.AdagradOptimizer(learning_rate=params['learning_rate']) train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step()) return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)