参考这篇文章:
https://zhuanlan.zhihu.com/p/128988454
《谷歌最新双塔DNN召回模型——应用于YouTube大规模视频推荐场景》
https://zhuanlan.zhihu.com/p/93257390
《向量化召回在360信息流广告的实践》
先是第一篇:
https://zhuanlan.zhihu.com/p/128988454
上述模型训练过程可以归纳为:
(1)从实时数据流中采样得到一个batch的样本
(2)基于下文即将提到的采样概率估计算法得到采样概率pi
(3)计算上文介绍的修正后的损失函数
(4)利用SGD更新模型参数
(1)近邻搜索:当模型训练完成之后,我们首先可以对候选视频进行inference得到视频侧的embedding向量,并对这些embedding构建索引用于线上查询使用,当线上有用户侧的请求到来是,模型只需要首先对该用户进行预测得到请求侧的embedding,然后从构建好索引的视频侧embedding中检索出top视频即可,这里需要说明的是很难进行最近邻的搜索(线上耗时的考虑),所以会采用一些近似最近邻的检索算法或者方式进行处理
(2)归一化处理:文章提到对两个塔输出的embedding向量进行归一化处理后会有效果上的提升,同时对归一化后的内积值引入了一个超参数用来调整最终的输出
(3)模型分布式训练:论文中对模型分布式训练进行了简要的介绍,具体可以参考论文中的表述
(4)hash冲突:由于在采样频率估计中使用到了hash算法,会在一定程度上存在hash冲突的问题,为了解决该问题,文章提出了一种改进的采样频率估计算法


然后是第二篇:
https://zhuanlan.zhihu.com/p/93257390
整个系统分为线上和线下两个部分,线下部分主要完成深层模型的训练以及广告索引库的建立,线上部分主要完成对用户请求的处理、为用户返回对应的Top-N候选广告集。
1、离线部分
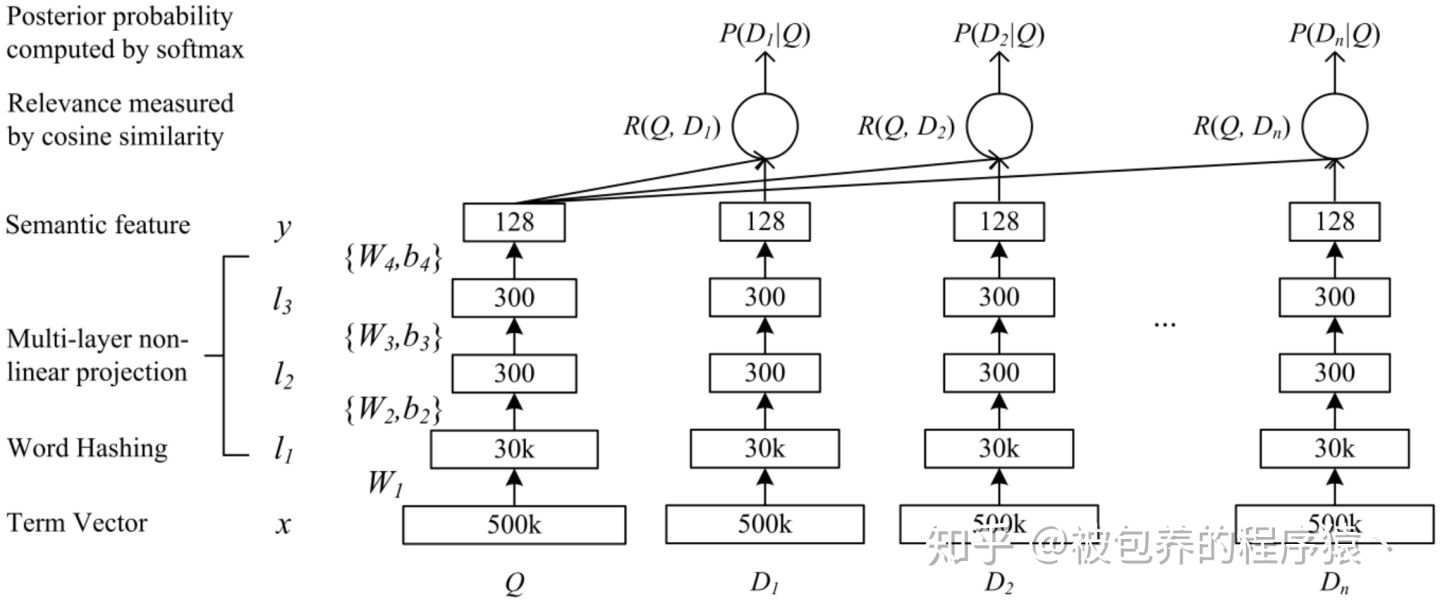
离线模型采用的是类似DSSM模型的结构,具体模型输入包括两个部分:1、广告侧的特征;2、用户请求上下文的相关特征,将两部分特征喂给类似DSSM这样的双塔网络中进行学习,DSSM模型结构如下所示:
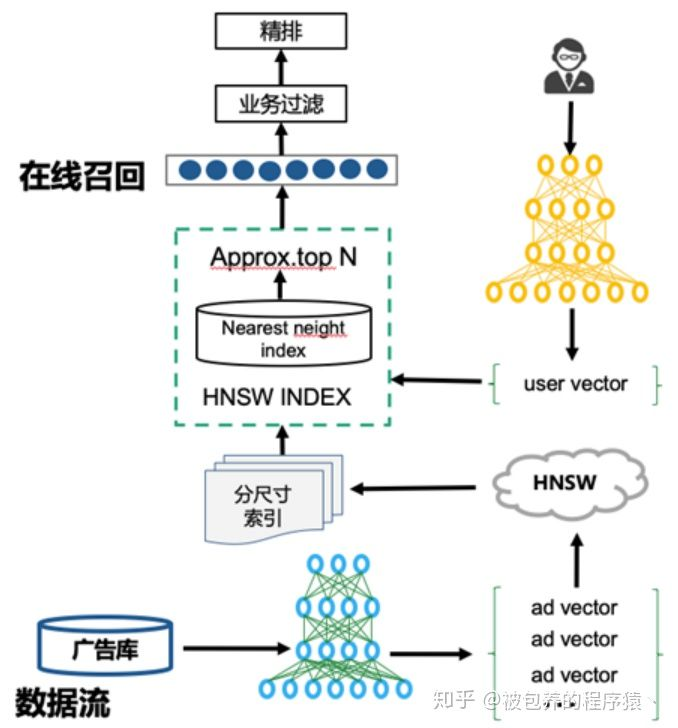
线上系统收到用户请求之后,会利用线上部署的模型计算得到该请求对应的Embedding向量,然后利用HNSW算法从候选广告集中检索出近似Top-N的候选广告,这部分广告经过相关的过滤(包括多路召回结果的合并等操作)之后最终进入排序模型。
三、总结
线上AB实验效果,CTR增长2.5%,相当于召回了更多高质量(高点击概率)的广告,主要得益于模型训练的样本采用的是展示点击样本,相当于是用广告向量和请求向量的匹配分数去拟和点击分布,相当于赋予内积形式以具体的物理含义。总的来看ANN向量化召回是一种训练部署较为简单,召回质量较高的一种召回方法。
四、思考
这一版ANN向量化召回模型是第一版,思考总结了一些后续可以继续优化的方面:
1、目前候选广告集并未采用全量广告集,后续可以考虑采用全量广告构建索引,同时需要考虑全量带来的检索的耗时开销,是否存在更高效的建立索引的方式(如参考TDM)
2、考虑更丰富的特征维度来刻画广告和请求侧的Embedding向量
3、目前采用展示点击广告进行模型训练迭代,相当于是把高点击率作为召回目标,该方法针对CPC广告主是适用的,能否针对oCPC进行转化率方面的优化,或者借鉴ESMM模型的思路对CTCVR进行联合优化