进程和线程
什么是线程(thread)什么是进程
线程:操作系统能够进行运算调度的最小单位。它被包含在进程中,是进程中的实际运作单位。是一串指令的集合
一个线程指的是进程中一个单一顺序的控制流,一个进程是中可以并发多个线程,每个线程并行执行不同的任务
进程:以一个整体的形式暴露给操作系统管理,里面包含对各种资源的调用,内存的管理,网络接口的调用等,对各种资源管理的集合,就可以称为进程
进程要操作cpu,必须先创建一个线程,所有在同一个进程里的线程是共享同一块内存空间的
注意:1.进程本身不能够执行
2.进程和线程不能比较谁快谁慢,两个没有可比性,进程是资源的集合,线程是真正执行任务的,进程要执行任务也要通过线程
3.启动一个线程比启动一个进程快
进程和线程的区别
1.线程共享内存空间,进程的内存是独立的
2.thread have direct access to data segment of its process;process have their own copy of the data segment of the parent process
3.同一个进程之间线程可以互相交流,两个进程想要通信,必须通过一个中间代理来实现
4.创建一个线程很简单,创建一个新进程需要对其父进程做一次克隆
5.一个线程可以控制和操作同一个进程里的其他的线程,但是进程只能操作子进程
6.改变一个主线程可能会影响到其他线程的运行,对父进程的修改不会影响到子进程
Python GIL(全局解释器锁)
在python中无论你启用多少个线程,你有多少个cpu,在python执行的时候都会在同一时刻只准许一个线程运行
原因:python的线程是调用操作系统的原生线程
线程锁:
1 import threading 2 import time 3 def run(n): 4 lock.acquire() 5 global num 6 num += 1 7 #time.sleep(1)在上锁的情况不要使用sleep,不然会等50s才会完成 8 lock.release() 9 lock = threading.Lock() 10 num = 0 11 start_time = time.time() 12 t_objs = [] 13 for i in range(50): 14 t = threading.Thread(target = run,args = ("t-%s" %i,)) 15 t.start() 16 t_objs.append(t) 17 for t in t_objs: 18 t.join() 19 print("-----all threads has finished....",threading.current_thread(),threading.active_count()) 20 21 print("num = ",num)
给线程上锁,使程序变成串行,保证num在+1的时候能够准确无误,不然可能会导致,一个线程正在执行+1还没有结束,另外一个线程也开始+1,最后达不到准确结果
递归锁:在一个大锁中包含一个小锁
场景:学校放学,学生离校了,突然发现自己的文具盒落在了教师中,学校每次只准许一个人进学校(其他东西丢了就是这个人干的),进教室拿的时候也要开教室门(防止有其他人在学校没有走),最后拿到文具盒,离开学校。这个期间学校大门相当于一把锁,教室的门相当于另一把锁。保证了整个过程没有其他人的干扰
1 import threading,time 2 3 def run1(): 4 print("grab the first part data") 5 lock.acquire() 6 global num 7 num += 1 8 lock.release() 9 return num 10 11 def run2(): 12 print("grab the second part data") 13 lock.acquire() 14 global num2 15 num2 += 1 16 lock.release() 17 return num2 18 19 def run3(): 20 lock.acquire() 21 res = run1() 22 print('------between run1 and run2') 23 res2 = run2() 24 lock.release() 25 print(res,res2) 26 27 num,num2 = 0,0 28 lock = threading.RLock() 29 for i in range(10): 30 t = threading.Thread(target=run3) 31 t.start() 32 33 while threading.active_count() != 1: 34 print(threading.active_count()) 35 else: 36 print("----all threads done---") 37 print(num,num2)
相当于先进入run3这个大门,然后在进入run1和run2这个两个小门,然后进行num1和num2的加1,保证了每个线程的执行都是串行的
Python threading模块
线程有2中调用方式
直接调用:
1 import threading 2 import time 3 4 def run(n): 5 print("task ",n) 6 time.sleep(2) 7 8 t1 = threading.Thread(target = run,args = ("t1",)) 9 t2 = threading.Thread(target = run,args = ("t2",)) 10 11 t1.start() 12 t2.start()
运行结果:一下子出来两个结果,但是程序还会等待2s才会结束,一共两秒,因为他们是并行的
继承式调用:
1 import threading 2 import time 3 4 #用类的方式启动线程 5 class MyThread(threading.Thread): 6 def __init__(self,n): 7 super(MyThread,self).__init__() 8 self.n = n 9 def run(self): 10 print("running task ",self.n) 11 12 t1 = MyThread("t1") 13 t2 = MyThread("t2") 14 t1.start() 15 t2.start()
上面只启动了2个线程,我们下面启动50个线程:
1 import threading 2 import time 3 4 def run(n): 5 print("task ",n) 6 time.sleep(2) 7 8 start_time = time.time() 9 for i in range(50): 10 11 t = threading.Thread(target = run,args = ("t-%s" %i,)) 12 t.start() 13 print("cost : ",time.time()-start_time)
运行结果:

问题:创建了50个进程之后只用了这点时间,主程序没有等其他的子线程就往下走
原因:是多线程的原因,一个程序至少有一个线程,程序本身就是一个线程,主线程,主线程启动了子线程之后,子线程就和主线程没有关系了,两个互不影响
解决方法:join()方法,等子线程运行完成之后,主程序才往下走
import threading import time def run(n): print("task ",n) time.sleep(2) print("task has done.... ",n) start_time = time.time() t_objs = [] for i in range(50): t = threading.Thread(target = run,args = ("t-%s" %i,)) t.start() t_objs.append(t) for t in t_objs: t.join() print("------all threads has finished") print("cost : ",time.time()-start_time)
先自己创建一个临时列表,然后存储创建的线程,然后一个一个的用join()方法
创建了50个线程,主线程就是程序的本身,也就是说上面一共有51个线程
#threading.current_thread()显示当前线程是主线程还是子线程
#threading.active_count()显示当前程序运行的线程的个数
print("-----all threads has finished....",threading.current_thread(),threading.active_count())
守护进程
t.setDaemon(True) #把当前线程设置成守护线程,要在start()之前
非守护线程结束,所有守护线程就退出
1 import threading 2 import time 3 def run(n): 4 print("task ",n) 5 time.sleep(2) 6 print("task has done.... ",n) 7 start_time = time.time() 8 t_objs = [] 9 for i in range(50): 10 11 t = threading.Thread(target = run,args = ("t-%s" %i,)) 12 t.setDaemon(True)#把当前线程设置成守护线程,要在start()之前 13 t.start() 14 t_objs.append(t) 15 16 print("-----all threads has finished....",threading.current_thread(),threading.active_count()) 17 print("cost : ",time.time()-start_time)
运行结果:task has done都没有运行,主线程结束之后,所有子线程都强制结束
Semaphore(信号量)
互斥锁同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据,如有3个座位,最多允许3个人同时在座位上,后面的人只能等到有人起来才能够坐进去
1 import threading,time 2 def run(n): 3 semaphore.acquire() 4 time.sleep(1) 5 print("run the thread:%s " %n) 6 semaphore.release() 7 8 if __name__ == '__main__': 9 10 semaphore = threading.BoundedSemaphore(5)#最多允许5个线程同时运行 11 for i in range(20): 12 t = threading.Thread(target = run,args=(i,)) 13 t.start() 14 15 16 while threading.active_count() != 1: 17 pass#print(threading.active_count()) 18 else: 19 print("----all threads done---") 20 21 #一次性执行了5个线程
和线程锁差不多,都要acquire()和release(),区别就是信号量有多把锁,
threading.BoundedSemaphore(5)最多允许5个线程同时运行,那运行结果就是5个结果一起出来,但是实质是这5个要是有3个先完成就会立刻再送进去3个,它不会等5个都完成,它是每出来一个就放进去一个
这5个如果同时改数据就有可能改错,这个主要用于:链接池 ,线程池。mysql链接有链接池的概念,同一时刻最多有几个并发;socketserver,为了保证系统不会被太多线程拉慢,可以用信号量弄同一时刻最多有100个链接进来
事件(event)
a events is a simple synchronization object;
the event represents an internal flag,and threads can wait for the flag to be set,or set or clear the flag themselves
事件是一个简单的同步对象,事件就相当于设置一个全部变量,然后线程不断的检测这个变量的变化然后进行不同的操作
方法:
event = threading.Event()生成一个event对象
event.set()
event.clear()
event.wait()
if the flag is set,the wait method doesn't do anything
标志位设定,代表绿灯,直接通行
if the flag is cleared,wait will block until it becomes set again
标志位被清空,代表红灯,wait等待变绿灯
any number of threads my wait for the same event
红绿灯案例:
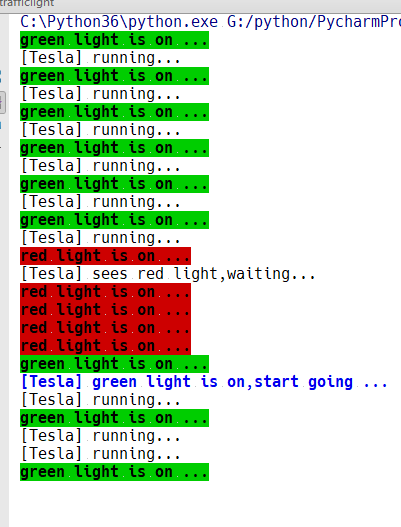
1 import threading 2 import time 3 4 event = threading.Event() 5 def lighter(): 6 count = 0 7 event.set()#一开始先设成绿灯 8 while True: 9 if count > 5 and count <=10 :#改成红灯 10 event.clear()#清空标志位 11 print("�33[41;1mred light is on ...�33[0m") 12 elif count > 10: 13 event.set()#变绿灯 14 print("�33[42;1mgreen light is on ...�33[0m") 15 count = 0 16 else: 17 print("�33[42;1mgreen light is on ...�33[0m") 18 time.sleep(1) 19 count += 1 20 def car(name): 21 while True: 22 if event.is_set():#代表绿灯 23 print("[%s] running..." %name) 24 time.sleep(1) 25 else: 26 print("[%s] sees red light,waiting..." %name) 27 event.wait() 28 print("�33[34;1m[%s] green light is on,start going ...�33[0m" %name) 29 30 light = threading.Thread(target = lighter,) 31 light.start() 32 car1 = threading.Thread(target = car,args=("Tesla",)) 33 car1.start()
运行结果:
queue队列
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads
class queue.Queue(maxsize = 0)先入先出
class queue.LifeQuene(maxsize = 0)last in first out
class queue.PriorityQueue(maxsize = 0)存储数据时可设置优先级的队列
队列就是一个有顺序的容器
列表和队列的区别:列表取出数据后,数据还在列表中,相当如复制数据;队列的数据只有一份,取走就没有了
队列的作用:
解耦,使程序直接实现松耦合
提高处理效率
class queue.Queue:

利用put(),get()方法往队列里加减数据,用qsize()方法得到此刻队列中还有多少数据。
但是有一个问题:当数据都取出来之后,如果还用get()方法去取数据的话,程序就会卡主

可以用get_nowait()方法,如果queue中没有了数据,就会抛出一个异常,这样就不会被卡住,同时也可以用qsize()方法进行判断,如果没有了数据就不要取了
Queue.get(block = True,timeout=None) block参数,如果取不到数据,默认就会卡住,改成false就不会卡住;timeout设置卡住几秒
class queue.LifoQueue(maxsize = 0)#last in first out
1 import queue 2 q = queue.LifoQueue() 3 q.put(1) 4 q.put(2) 5 q.put(3) 6 print(q.get()) 7 print(q.get()) 8 print(q.get())
运行结果:

class queue.PriorityQueue(maxsize = 0)#存储数据室可以设置优先级队列
1 import queue 2 q = queue.PriorityQueue() 3 4 q.put((10,"d1")) 5 q.put((-1,"d2")) 6 q.put((3,"d4")) 7 q.put((6,"d5")) 8 print(q.get()) 9 print(q.get()) 10 print(q.get()) 11 print(q.get())
运行结果:

生产者消费者模型:
在并发编程中使用生产者和消费者模式能够解决大多数并发问题,该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度
例子:
1 import threading,time 2 import queue 3 q = queue.Queue(maxsize = 10) 4 def Producer(name): 5 count = 1 6 while True: 7 q.put("骨头:%s" %count) 8 print("生产了骨头:",count) 9 count += 1 10 time.sleep(0.5) 11 12 13 14 def Consumer(name): 15 while True: 16 if q.qsize() > 0: 17 print("[%s] 取到 [%s],并且吃到了它。。。" %(name,q.get())) 18 time.sleep(1) 19 p = threading.Thread(target = Producer,args=("xiaoming",)) 20 c = threading.Thread(target = Consumer,args=("xiaohong",)) 21 c1 = threading.Thread(target = Consumer,args=("liangliang",)) 22 p.start() 23 c.start() 24 c1.start()
运行结果:

多进程
首先我们要知道,io操作不占用cpu,计算占用cpu
其次python多线程,不适合cpu密集操作型的任务,适合io操作密集型的任务比如:socketserver,可以同时接收多个网络并发连接
多进程基本实例:
import multiprocessing import time def run(name): time.sleep(2) print('hello ',name) if __name__ == '__main__': for i in range(10): p = multiprocessing.Process(target=run,args=('bob %s' %i,)) p.start()
用的multiprocessing.Process()其他的和线程差不多
我们再来看一个例子,我们尝试着取进程号:
1 from multiprocessing import Process 2 import os 3 4 def info(title): 5 print(title) 6 print("module name:",__name__) 7 print("parent process:",os.getppid()) 8 print("process id:",os.getpid()) 9 print(" ") 10 11 def f(name): 12 info('�33[31;1mcalled from child process function f�33[0m') 13 print("hello ",name) 14 15 if __name__ == '__main__': 16 info('�33[32;1mmain process line�33[0m') 17 p = Process(target=f,args=('bob',)) 18 p.start() 19 # p.join()
1.首先我们吧启动进程的语句注释,即在不启动进程的前提下运行程序,得到的结果如下:

这里的226880的进程号其实是pycharm的进程号,即每一个进程默认都会有一个父进程
2.现在我们启动一个进程,运行结果如下:
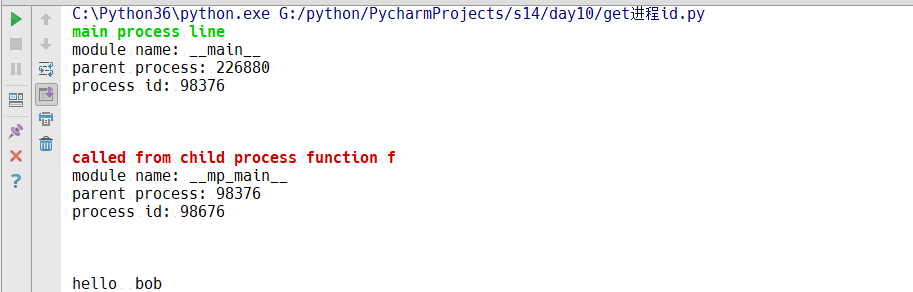
我们通过两个可以知道:每一个程序都是有一个父进程,即便是主程序
进程间通讯
不同进程间内存是不共享的,要想实现两个进程间的数据交换,可以用一下方法:
Queues
使用方法和threading里的queue差不多
线程queue:为了做两个线程间的数据,实现的生产者消费者模型,必须都是线程。比如:在程序中写一个queue,只有在当前主程序下的其他线程才能够被访问,出了这个线程就访问不到了
首先我们试试线程queue,看能不能实现进程之间的共享通讯:
from multiprocessing import Process import queue def f(): q.put([42,None,'Hello']) if __name__ == '__main__': q = queue.Queue() p = Process(target=f) p.start()
运行结果如下:
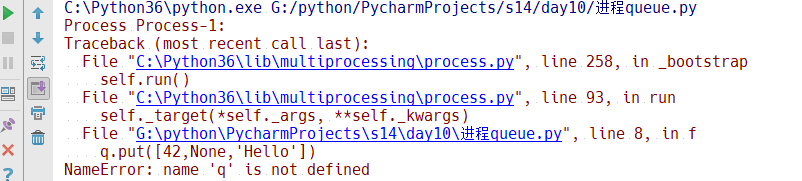
出现一个问题,如果这个是在线程里运行的queue,就没有问题,但是现在在进程中,子进程中报错了,因为这个queue是在父进程中定义的,子进程一旦被父进程启动之后,他两的内存都是独立的。既然内存是独立的,父进程的q就不能被子进程访问。
这时候有的人可能会说如果把这个父进程定义的q传进去应该就能够访问的到了吧,下面我们就来试一下:
1 from multiprocessing import Process 2 import queue 3 4 def f(q2): 5 q2.put([42,None,'Hello']) 6 7 if __name__ == '__main__': 8 q = queue.Queue() 9 p = Process(target=f,args=(q,)) 10 p.start() 11 print(q.get())
运行结果:

出现了错误,首先我们要记住,我们想要把一个线程q传给一个子进程,这个是不可以的,如果你想传的话就必须用进程q
1 from multiprocessing import Process,Queue 2 def f(q2): 3 q2.put([42,None,'Hello']) 4 5 if __name__ == '__main__': 6 q = Queue() 7 p = Process(target=f,args=(q,)) 8 p.start() 9 print(q.get())
这个时候子进程就能够访问到

现在我们来讨论一下父进程这个q是怎么传给子进程的:
现在我们好像是数据共享了,两个进程共享了一个q,其实不是这样的,其实是相当于克隆了一个q,父进程中创建了子进程,就要把q克隆一份给子进程,子进程往q中放了一份数据, 相当于两个q,但是想要两个之间通信,就需要在中间建立一个中间通道,通过pickle对数据的序列化反序列化的方式进行传递
不管怎么说,不管他底层是怎么运转的,两个进程之间已经实现了通信,但这个通信相当于数据的传递,没有做到修改数据
Pips
管道通信 ,连个进程之间是独立的,要想通信,可以在中间建立一个类似于“电话线”的管道,这样就可以实现通信了
案例:
1 from multiprocessing import Process,Pipe 2 3 def f(conn): 4 conn.send([42,None,'Hello from child']) 5 conn.close() 6 if __name__ == '__main__': 7 parent_conn,child_conn = Pipe()#生成一个管道实例,会返回两个对象,相当于管道的两头 8 p = Process(target=f,args=(child_conn,)) 9 p.start() 10 print(parent_conn.recv()) 11 p.join()
Pipe()生成了一个管道实例,相当于电话线的两头,一个父亲一个儿子,把儿子的传给子进程,子进程通过send()传递信息,父进程通过recv()获得信息。如果发送多条信息,父进程也要有多个接收,否则就会卡住。
当然父进程也可以发送信息给子进程,还是用send(),和recv()一样
上面是两个进程之间的数据的通讯,只是数据的传递,还不是共享,如果要实现共享应该怎么办呢,那就需要使用manager:
Managers
manager可以实现列表,字典,锁lock,RLOck,信号量,状态,事件,等等的共享,比如:
1 from multiprocessing import Process,Manager 2 import os 3 def f(d,l): 4 d[os.getpid()] = os.getpid() 5 l.append(os.getpid()) 6 print(l) 7 8 if __name__ == '__main__': 9 with Manager() as manager: 10 d = manager.dict()#生成一个字典,生成一个可在多个进程之间传递和共享的字典 11 l = manager.list(range(5)) 12 p_list = [] 13 for i in range(10): 14 p = Process(target=f,args=(d,l)) 15 p.start() 16 p_list.append(p) 17 for res in p_list:#等待结果 18 res.join() 19 20 print(d) 21 print(l)
先生成一个字典和一个有了5个数的列表,然后把这个些传给创建的10个子进程,在子进程里进行修改字典和列表中的内容,运行结果如下:
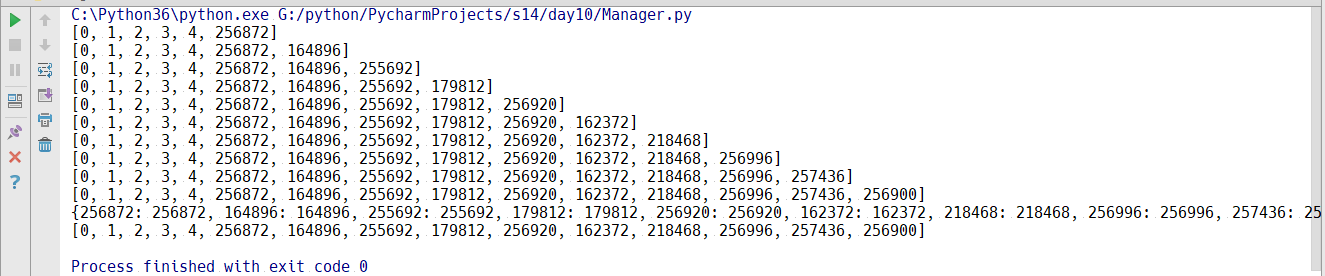
这就实现了在进程中数据的真正的共享,可以传递,可以修改。要用到manager.
有的人可能会问,10个进程在修改传递数据,要不要给他们加锁,其实不用,manager已经自己默认给加锁了,他就不允许两个进程同时修改数据。其实根本没有办法实现两个进程之间同时修改数据,因为进程和数据是独立的,其实他内部也要自己进行加锁操作,因为它要把数据同时copy好几份,和之前的q是一样的,表面上虽然是共享一个字典,实际上是copy10个字典10个列表,最终又合到 了一起
进程同步
在进程中还有一个锁:
1 from multiprocessing import Process,Lock 2 def f(l,i): 3 l.acquire() 4 try: 5 print("hello world ",i) 6 finally: 7 l.release() 8 if __name__ == '__main__': 9 lock = Lock() 10 for num in range(10): 11 Process(target=f,args=(lock,num)).start()
从multiprocessing中导入Lock,然后实例化一个锁,把锁传给子进程,用acquire和release进行加锁解锁,运行结果:
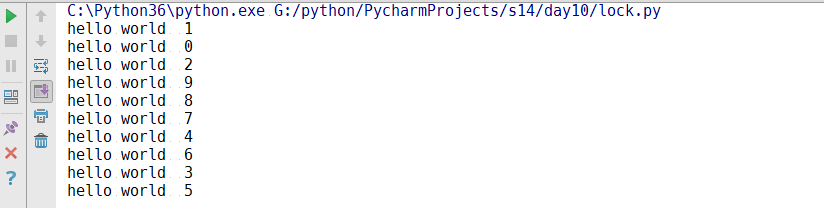
为什么需要锁呢?虽然每个进程都是独立的,但是你看他们现在都在共享一个屏幕来显示他们的运行,这个锁存在的意义就在于:因为屏幕共享,如果你也想打数据到屏幕上,我也想,就有可能打乱了,所以这个锁就可以保证在打印数据的时候,保证这个时候自己的进程可以独占,导致屏幕的显示不会乱(在linux中会有所体现)
进程池
如果你启动了100个进程,你就会有所感觉会有卡顿,变慢了,因为起一个进程就相当于克隆一份父进程的内存数据,如果父进程占用1G的内存空间,起100个进程就会占用101G,所以说开销特别大,为了避免这个问题,就有一个进程池。限制同一时间有多少进程在cpu上运行
我们没有线程池,当然可以通过信号量搞一个线程池,但是python没有做线程池,因为 线程启动的开销太小,启动太多的线程唯一的坏处就是:导致cpu的切换过于频繁,导致系统过慢,
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中更没有可供使用的进程池,那么程序就会等待,直到进程池中有可用的进程为止:
进程池中有两个方法:
1.apply
2.apply_async
1 from multiprocessing import Process,Pool 2 import time,os 3 def Foo(i): 4 time.sleep(2) 5 print('in the process ',os.getpid()) 6 return i+100 7 8 def Bar(arg): 9 print('--->exec done:',arg) 10 if __name__ == '__main__': 11 pool = Pool(5) 12 13 for i in range(10): 14 #pool.apply_async(func=Foo,args=(i,),callback=Bar) 15 pool.apply(func=Foo,args=(i,)) 16 print("end") 17 pool.close() 18 #pool.join()#进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭,
这里要注意的是:先关pool,在执行.join方法,否则就会直接结束,不执行子进程的内容,还有就是在windows上,如果没有if __name__ == '__main__',程序就会报错,但是在linux中不会
if __name__ == '__main__':这是什么意思呢:
这句话是为了区分你是主动运行这个脚本, 还是在别的地方把它当做一个模块去调用,如果你主动运行这个脚本,下面的语句就执行,否则就不执行
ok,解释完之后我们回到进程池:
pool = Pool(5)--->pool = Pool(processes = 5)#运行进程池中同时放入5个进程,正常应该是5个5个进程的打印,实际上是一个一个进程的打印,这是因为apply意思就是同步执行,串行,apply_async意思就是异步执行,并行,如果用apply_async就可以5个5个一起执行
在apply_async中有一个callback参数,意思就是当子进程运行结束,自动执行回调函数,而且是主进程调用回调
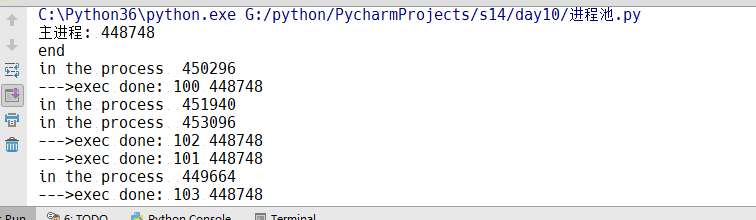
例如:我启动10个进程到10台机器上去调用备份,备份数据库啥的,备份完了之后要写一份日志,为什么不在子进程中直接调数据库写呢?现在起了10个进程, 每个进程执行完了让进程直接连数据库写日志也可以。这个和父进程写日志的区别就是:父进程连数据库连上一次,长连接就可以写了,子进程要写的话就要都连接数据库,这样要有10个连接,要是有100个进程就要启动100个连接,父进程直接就连好了,生成了对象实例,连好之后,每个子进程备份完毕调用这个实例,就通过一个父进程的实例去写日志就可以了,这样效率就很高了。