上一节中,我们使用autograd的包来定义模型并求导。本节中,我们将使用torch.nn包来构建神经网络。
一个nn.Module包含各个层和一个forward(input)方法,该方法返回output.
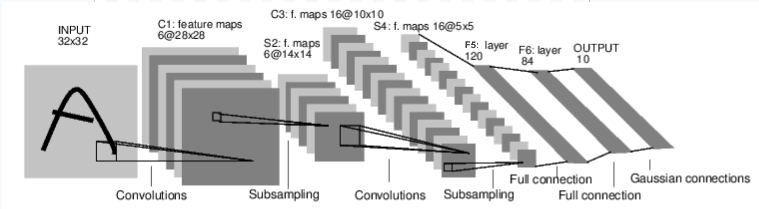
上图是一个简单的前馈神经网络。它接受一个输入。然后一层接着一层地传递。最后输出计算的结果。
神经网络模型的训练过程
神经网络的典型训练过程如下:
- 定义包含一些可学习的参数(或者叫做权重)的神经网络模型。
- 在数据集上迭代。
- 通过神经网络处理输入。
- 计算损失函数(输出结果和正确值的差值大小)。
- 将梯度反向传播回网络的权重等参数。
- 更新网络的权重。主要使用以下的更新原则:weight = weight - learining_rate*gradient.
完整的代码如下(跟官方比,做了详细的中文注释):
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data.dataloader as Data
import torchvision #torchvision模块包括了一些图像数据集,如MNIST,cifar10等
import matplotlib.pyplot as plt
# 1 准备数据
# 所有的torchvision.datasets数据集的类都是torch.utils.data.Dataset的子类,实现了__getitem__和__len__方法。故可传递给torch.utils.data.DataLoader来加载
# 创建用于Train的数据集,若root目录无数据集,则Download;若root目录有数据集,则从PIL图像数据转换为Tensor
train_data = torchvision.datasets.MNIST(root='./mnist',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.MNIST(root='./mnist',train=False,transform=torchvision.transforms.ToTensor())
print("train_data:",train_data.data.size())
print("train_labels:",train_data.targets.size())
print("test_data:",test_data.data.size())
# 根据数据集创建响应的dataLoader
# shuffle(bool, 可选) – 如果每一个epoch内要打乱数据,就设置为True(默认:False)
train_loader = Data.DataLoader(dataset=train_data, batch_size=50, shuffle=True)
test_loader = Data.DataLoader(dataset=test_data, batch_size=500, shuffle=False)
# 2 创建模型
class CNN(nn.Module): # 定义了一个类,名字叫CNN
#注意: 在模型中必须要定义 `forward` 函数,`backward` 函数(用来计算梯度)会被`autograd`自动创建。 可以在 `forward` 函数中使用任何针对 `Tensor` 的操作。
def __init__(self): # 每个类都必须有的构造函数,用来初始化该类
super(CNN, self).__init__() # 先调用父类的构造函数
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
# 本函数配置了卷积层和全连接层的维度
# Conv2d(in_cahnnels, out_channels, kernel_size, stride, padding=0 ,...)
self.conv1 = nn.Conv2d(1, 16, 5, 1, 2) # 卷积层1: 二维卷积层, 1x28x28,16x28x28, 卷积核大小为5x5
self.conv2 = nn.Conv2d(16, 32, 5, 1, 2) # 卷积层2: 二维卷积层, 16x14x14,32x14x14, 卷积核大小为5x5
# an affine(仿射) operation: y = Wx + b # 全连接层1: 线性层, 输入维度32x7x7,输出维度128
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10) # 全连接层2: 线性层, 输入维度128,输出维度10
def forward(self, x): #定义了forward函数
# Max pooling over a (2, 2) window
conv1_out = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # 先卷积,再池化
# If the size is a square you can only specify a single number
conv2_out = F.max_pool2d(F.relu(self.conv2(conv1_out)), 2) # 再卷积,再池化
res = conv2_out.view(conv2_out.size(0), -1) # 将conv3_out展开成一维(扁平化)
fc1_out = F.relu(self.fc1(res)) # 全连接1
out = self.fc2(fc1_out) # 全连接2
#return out
return F.log_softmax(out),fc1_out #返回softmax后的Tensor,以及倒数第二层的Tensor(以进行低维Tensor的可视化)
cnn = CNN() #新建了一个CNN对象,其实是一系列的函数/方法的集合
cnn = cnn.cuda() #*.cuda()将模型的所有参数和缓存移动到GPU
print(cnn)
def plot_with_labels(lowDWeights, labels):
plt.cla() #clear当前活动的坐标轴
X, Y = lowDWeights[:, 0], lowDWeights[:, 1] #把Tensor的第1列和第2列,也就是TSNE之后的前两个特征提取出来,作为X,Y
for x, y, s in zip(X, Y, labels):
c = cm.rainbow(int(255 * s / 9));
#plt.text(x, y, s, backgroundcolor=c, fontsize=9)
plt.text(x, y, str(s),color=c,fontdict={'weight': 'bold', 'size': 9}) #在指定位置放置文本
plt.xlim(X.min(), X.max());
plt.ylim(Y.min(), Y.max());
plt.title('Visualize last layer');
plt.show();
plt.pause(0.01)
# 3 定义损失函数-这里默认是交叉熵函数
loss_func = torch.nn.CrossEntropyLoss()
# 4 初始化:优化器
optimizer = optim.Adam(cnn.parameters(), lr=0.01) #list(cnn.parameters())会给出一个参数列表,记录了所有训练参数(W和b)的数据
# optimizer =optim.Adam([ {'params': cnn.conv1.weight}, {'params': cnn.conv1.bias, 'lr': 0.002,'weight_decay': 0 },
# {'params': cnn.conv2.weight}, {'params': cnn.conv2.bias, 'lr': 0.002,'weight_decay': 0 },
# {'params': cnn.fc1.weight}, {'params': cnn.fc1.bias, 'lr': 0.002,'weight_decay': 0 },
# {'params': cnn.fc2.weight}, {'params': cnn.fc2.bias, 'lr': 0.002,'weight_decay': 0 },
# {'params': cnn.conv3.weight}, {'params': cnn.conv3.bias, 'lr': 0.002,'weight_decay': 0 },
# {'params': cnn.conv4.weight}, {'params': cnn.conv4.bias, 'lr': 0.002,'weight_decay': 0 },
# {'params': cnn.conv5.weight}, {'params': cnn.conv5.bias, 'lr': 0.002,'weight_decay': 0 },], lr=0.001, weight_decay=0.0001)
# 5 训练:
def train(epoch):
print('epoch {}'.format(epoch))
#直接初始化为0的是标量,tensor调用item()将返回标量值
train_loss = 0
train_acc = 0
#step是enumerate()函数自带的索引,从0开始
for step, (batch_x, batch_y) in enumerate(train_loader):
# 把batch_x和batth_y移动到GPU
batch_x = batch_x.cuda()
batch_y = batch_y.cuda()
# 正向传播
out,_ = cnn(batch_x)
loss = loss_func(out, batch_y)
train_loss += loss.item()
# torch.max(tensor,dim:int):tensor找到第dim维度(第0维度是数据下标)上的最大值
# return: 第一个Tensor是该维度的最大值,第二个Tensor是最大值相应的下标
pred = torch.max(out, 1)[1]
# 直接对逻辑量进行sum,将返回True的个数
train_correct = (pred == batch_y).sum()
train_acc += train_correct.item()
if step % 20 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(epoch, step * len(batch_x), len(train_loader.dataset),100. * step / len(train_loader), loss.item()))
#反向传播
optimizer.zero_grad() # 所有参数的梯度清零
loss.backward() #即反向传播求梯度
optimizer.step() #调用optimizer进行梯度下降更新参数
print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(train_data)), train_acc / (len(train_data))))
from matplotlib import cm
try:
from sklearn.manifold import TSNE; HAS_SK = True
except:
HAS_SK = False; print('Please install sklearn for layer visualization')
# 6 准确率
def test():
cnn.eval()
eval_loss = 0
eval_acc = 0
# 打开imshow()交互模式:更新图像后直接执行以后的代码,不阻塞在plt.show()
plt.ion()
#无需反向传播计算梯度,不需要进行求导运算
with torch.no_grad():
for step, (batch_x, batch_y) in enumerate(test_loader):
batch_x = batch_x.cuda()
batch_y = batch_y.cuda()
out,last_layer = cnn(batch_x)
loss = loss_func(out, batch_y)
#loss = += F.nll_loss(out, batch_y, size_average=False).item()
eval_loss += loss.item()
pred = torch.max(out, 1)[1]
num_correct = (pred == batch_y).sum()
eval_acc += num_correct.item()
#若需绘图,将下面代码块注释去掉
if step % 100 == 0:
#t-SNE 是一种非线性降维算法,非常适用于高维数据降维到2维或者3维,进行可视化
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
#最多只画500个点
plot_only = 500
#fit_transform函数把last_layer的Tensor降低至2个特征量,即3个维度(2个维度的坐标系)
low_dim_embs = tsne.fit_transform(last_layer.cpu().data.numpy()[:plot_only, :])
labels = batch_y.cpu().numpy()[:plot_only]
plot_with_labels(low_dim_embs, labels)
#若需绘图,将上面代码块注释去掉
print('Test Loss: {:.6f}, Accuracy: {}/{} ({:.2f}%'.format(eval_loss / (len(test_data)),eval_acc, len(test_data) ,100.*eval_acc / (len(test_data))))
plt.ioff()
# 共训练/测试 20轮
# 每轮训练整个数据集1遍,每轮有len(dataset)/batch_size次训练
# 每次训练要训练batch_size个数据
# 每个batch的数据,第一个维度是数据的下标:0,1,2,...,batch_size-1
for epoch in range(1, 21):
train(epoch)
test()
除了上面代码段中的实现,你可能还需要了解以下知识:
损失函数与autograd反向传播
一个损失函数需要一对输入:模型输出和目标,然后计算一个值来评估输出距离目标有多远。
根据之前学习的理论,一般是计算y和y'的交叉熵.
例如,对于线性拟合案例,损失函数就是均方误差,即MSE.
output = net(input)
target = torch.randn(10) # a dummy target, for example
target = target.view(1, -1) # make it the same shape as output
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
将输出:
tensor(1.3389, grad_fn=<MseLossBackward>)
现在,如果你跟随损失到反向传播路径,可以使用它的 .grad_fn 属性,你将会看到一个这样的计算图:
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
所以,当我们调用 loss.backward(),整个图都会微分,而且所有的在图中的requires_grad=True 的张量将会让他们的 grad 张量累计梯度。
为了演示,我们将跟随以下步骤来跟踪反向传播。
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
输出:
<MseLossBackward object at 0x7fab77615278>
<AddmmBackward object at 0x7fab77615940>
<AccumulateGrad object at 0x7fab77615940>
为了实现反向传播损失,我们所有需要做的事情仅仅是使用 loss.backward()。你需要清空现存的梯度,要不梯度将会和现存的梯度累计到一起。
现在我们调用 loss.backward() ,然后看一下 con1 的偏置项在反向传播之前和之后的变化。
net.zero_grad() # zeroes the gradient buffers of all parameters,清空现存的梯度
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
输出:
conv1.bias.grad before backward
tensor([0., 0., 0., 0., 0., 0.])
conv1.bias.grad after backward
tensor([-0.0054, 0.0011, 0.0012, 0.0148, -0.0186, 0.0087])
上面介绍了如何使用损失函数。
更新神经网络参数
最简单的更新规则就是随机梯度下降:weight = weight - learning_rate * gradient。
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
复杂的神经网络参数可这样使用:
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
t-SNE:数据可视化
本节摘自 这里。
数据降维与可视化——t-SNE
t-SNE 是目前来说效果最好的数据降维与可视化方法,但是它的缺点也很明显,比如:占内存大,运行时间长。但是,当我们想要对高维数据进行分类,又不清楚这个数据集有没有很好的可分性(即同类之间间隔小,异类之间间隔大),可以通过 t-SNE 投影到 2 维或者 3 维的空间中观察一下。如果在低维空间中具有可分性,则数据是可分的;如果在高维空间中不具有可分性,可能是数据不可分,也可能仅仅是因为不能投影到低维空间。
t-distributed Stochastic Neighbor Embedding(t-SNE)
t-SNE(TSNE)将数据点之间的相似度转换为概率。原始空间中的相似度由高斯联合概率表示,嵌入空间的相似度由“学生 t 分布”表示。
虽然 Isomap,LLE 和 variants 等数据降维和可视化方法,更适合展开单个连续的低维的 manifold。但如果要准确的可视化样本间的相似度关系,如对于下图所示的 S 曲线(不同颜色的图像表示不同类别的数据),t-SNE 表现更好。因为t-SNE 主要是关注数据的局部结构。
通过原始空间和嵌入空间的联合概率的 Kullback-Leibler(KL)散度来评估可视化效果的好坏,也就是说用有关 KL 散度的函数作为 loss 函数,然后通过梯度下降最小化 loss 函数,最终获得收敛结果。
使用 t-SNE 的缺点大概是:
- t-SNE 的计算复杂度很高,在数百万个样本数据集中可能需要几个小时,而 PCA 可以在几秒钟或几分钟内完成
- Barnes-Hut t-SNE 方法(下面讲)限于二维或三维嵌入。
- 算法是随机的,具有不同种子的多次实验可以产生不同的结果。虽然选择 loss 最小的结果就行,但可能需要多次实验以选择超参数。
- 全局结构未明确保留。这个问题可以通过 PCA 初始化点(使用init ='pca')来缓解。
其参数及描述如下:
n_components int, 默认为 2,嵌入空间的维度(嵌入空间的意思就是结果空间)
perplexity float, 默认为 30,数据集越大,需要参数值越大,建议值位 5-50
early_exaggeration float, 默认为 12.0,控制原始空间中的自然集群在嵌入式空间中的紧密程度以及它们之间的空间。 对于较大的值,嵌入式空间中自然群集之间的空间将更大。 再次,这个参数的选择不是很关键。 如果在初始优化期间成本函数增加,则可能是该参数值过高。
learning_rate float, default:200.0, 学习率,建议取值为 10.0-1000.0
n_iter int, default:1000, 最大迭代次数
n_iter_without_progress int, default:300, 另一种形式的最大迭代次数,必须是 50 的倍数
min_grad_norm float, default:1e-7, 如果梯度低于该值,则停止算法
metric string or callable, 精确度的计量方式
init string or numpy array, default:”random”, 可以是’random’, ‘pca’或者一个 numpy 数组(shape=(n_samples, n_components)。
verbose int, default:0, 训练过程是否可视
random_state int, RandomState instance or None, default:None,控制随机数的生成
method string, default:’barnes_hut’, 对于大数据集用默认值,对于小数据集用’exact’
angle float, default:0.5, 只有method='barnes_hut'时可用
其具有的属性有:
attributes description
embedding_ 嵌入向量
kl_divergence 最后的 KL 散度
n_iter_ 迭代的次数
其Method有:
Methods description
fit 将 X 投影到一个嵌入空间
fit_transform 将 X 投影到一个嵌入空间并返回转换结果
get_params 获取 t-SNE 的参数
set_params 设置 t-SNE 的参数
下列代码详细解释了MNIST数据集可进行的可视化:
# coding='utf-8'
"""t-SNE 对手写数字进行可视化"""
from time import time
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.manifold import TSNE
def get_data():
digits = datasets.load_digits(n_class=6)
data = digits.data
label = digits.target
n_samples, n_features = data.shape
return data, label, n_samples, n_features
def plot_embedding(data, label, title):
x_min, x_max = np.min(data, 0), np.max(data, 0)
data = (data - x_min) / (x_max - x_min)
fig = plt.figure()
ax = plt.subplot(111)
for i in range(data.shape[0]):
plt.text(data[i, 0], data[i, 1], str(label[i]),
color=plt.cm.Set1(label[i] / 10.),
fontdict={'weight': 'bold', 'size': 9})
plt.xticks([])
plt.yticks([])
plt.title(title)
return fig
def main():
data, label, n_samples, n_features = get_data()
print('Computing t-SNE embedding')
tsne = TSNE(n_components=2, init='pca', random_state=0)
t0 = time()
result = tsne.fit_transform(data)
fig = plot_embedding(result, label,
't-SNE embedding of the digits (time %.2fs)'
% (time() - t0))
plt.show(fig)
if __name__ == '__main__':
main()