卷积网络
卷积神经网络(Convolutional Neural Network,CNN)专门处理具有类似网格结构的数据的神经网络。如:
- 时间序列数据(在时间轴上有规律地采样形成的一维网格);
- 图像数据(二维的像素网格);
卷积网络是指至少在网络的一层中使用卷积运算来替代一般的矩阵乘法运算的神经网络。
卷积
前面讲过卷积,
相关算法这里直接使用。
卷积公式为:(s(t)=int_{-infty}^{t}x( au)w(t- au)d au),记作(s(t)=(x*w)(t))。
这里卷积第一个参数(函数(x))叫做输入,第二个参数叫做核函数,输出有时叫做特征映射。
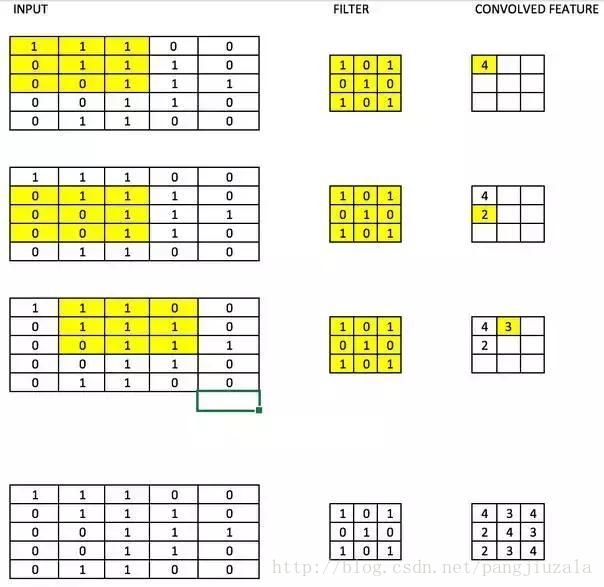
卷积滤波器(原文)
CNN中的滤波器与加权矩阵一样,它与输入图像的一部分相乘以产生一个回旋输出。我们假设有一个大小为
28 * 28的图像,我们随机分配一个大小为3 * 3的滤波器,然后与图像不同的3 * 3部分相乘,形成所谓
的卷积输出。滤波器尺寸通常小于原始图像尺寸。在成本最小化的反向传播期间,滤波器值被更新为重量值。
卷积神经网络(原文)
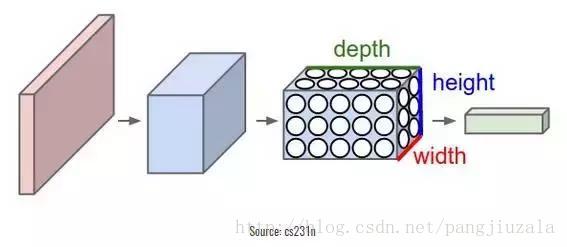
卷积神经网络基本上应用于图像数据。假设我们有一个输入的大小(28 * 28 * 3),如果我们使用正常的
神经网络,将有2352(28 * 28 * 3)参数。并且随着图像的大小增加参数的数量变得非常大。我们“卷积”
图像以减少参数数量(如上面滤波器定义所示)。当我们将滤波器滑动到输入体积的宽度和高度(宽度为28,
高度为28)时,将产生一个二维激活图,给出该滤波器在每个位置的输出。我们将沿深度(深度为3)尺寸堆叠
这些激活图,并产生输出量。
你可以看到下面的图,以获得更清晰的印象。
池化(Pooling)(原文)
通常在卷积层之间定期引入池层。这基本上是为了减少一些参数,并防止过度拟合。最常见的池化类型是
使用MAX操作的滤波器尺寸(2,2)的池层。它会做的是,它将占用原始图像的每个4 * 4矩阵的最大值。
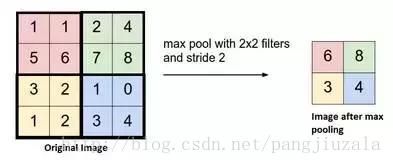
你还可以使用其他操作(如平均池)进行池化,但是最大池数量在实践中表现更好。
填充(Padding)
填充是指在图像之间添加额外的零层,以使输出图像的大小与输入相同。这被称为相同的填充。
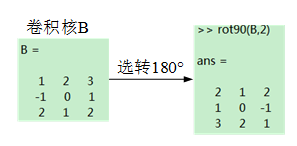
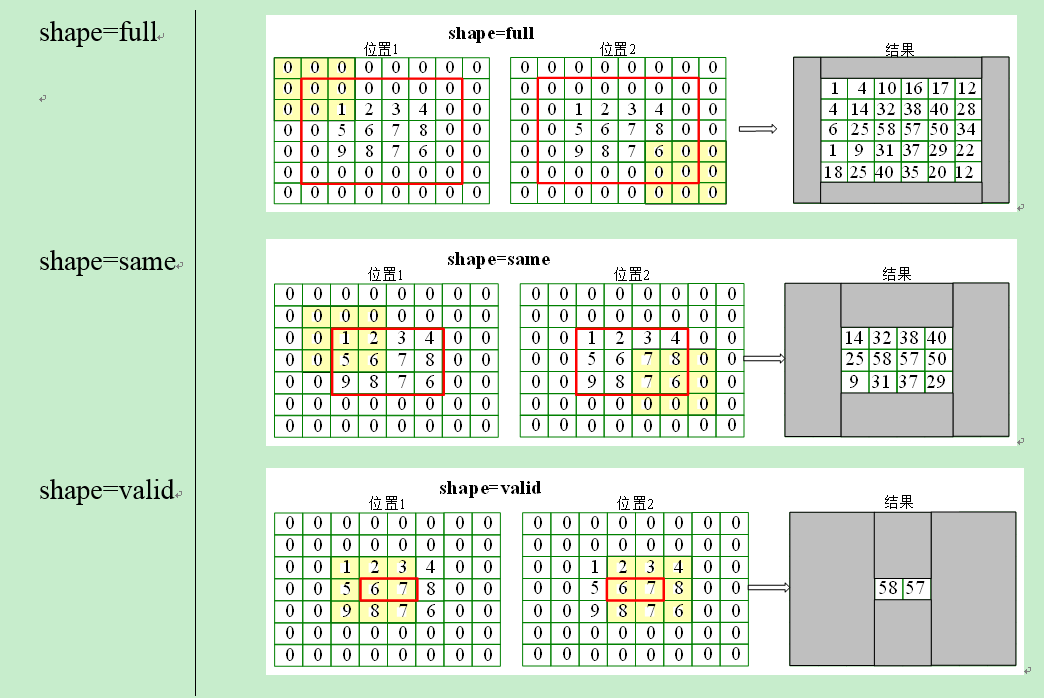
在应用滤波器之后,在相同填充(shape=same)的情况下,卷积层具有等于实际图像的大小。
有效填充(shape=valid)是指将图像保持为具有实际或“有效”的图像的所有像素。在这种情
况下,在应用滤波器之后,输出的长度和宽度的大小在每个卷积层处不断减小。
数据集增强
创建假数据以实现更好的泛化:对数据进行变换或加噪声(如对图形进行旋转平移,加高斯噪声等)后作为训练数据集,保证分类效果不变|
卷积神经网络案例1:MNIST进阶(原文)
----中间几章辣么多的理论的东西,现在我们继续看实现部分。----
首先应该回顾TensorFlow学习笔记3-从MNIST开始。
其中,在MNIST上只有91%正确率,实在太糟糕。在此,我们用一个稍微复杂的模型:卷积神经网络来改善效果。这会达到大概99.2%的准
确率。虽然不是最高,但是还是比较让人满意。
权重初始化
(w)初始化为高斯噪声,防止输出恒为0,进而一开始就处在激活状态,而偏置(b)初始化为较小的正数。
为了代码更简洁,我们把这部分抽象成一个函数。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
卷积和池化
卷积使用1步长(stride size),0边距(padding size)的模板,保证输出和输入是同一个大小。我们的池化用
简单传统的2x2大小的模板做max pooling。为了代码更简洁,我们把这部分抽象成一个函数。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
其中TensorFlow中的tf.nn.conv2d函数:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=true, name=None)
name参数:给返回的tensor命名。给输出feature map起名字。- 第一个参数
input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32或float64; - 第二个参数
filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型为float32或float64; - 第三个参数
strides:卷积时在图像每一维的步长,一个一维的向量,长度4;如果你的数据是图片,则为[1,stepx,stepy,1]。 - 第四个参数
padding:string类型的量,只能是"SAME"或"VALID",这个值决定了卷积方式; - 第五个参数
use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true;
输出,就是我们常说的feature map,shape仍然是[batch, height, width, channels]这种形式。
例如:如输入三通道rgb图,滤波器的out_channels设为1的话,就是三通道对应值相加,最后输出一个卷积和,即一个通道。
第一层卷积
第一层由一个卷积接一个max pooling完成。卷积在5x5的卷积核中共算出32个特征。卷积的权重张量形状
是[5, 5, 1, 32],前两个维度是卷积核的大小,接着是输入的通道数目,最后是输出的通道数目。 而对于
每一个输出通道都有一个对应的偏置量。
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
为了用这一层,我们把x变成一个4d向量,其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(因为是灰度图所以这里的通道数为1,如果是rgb彩色图,则为3)。
x_image = tf.reshape(x, [-1,28,28,1])
然后用权重对x_image进行卷积, 添加偏置, 应用ReLU函数, 和max-pool函数. 我们把x_image和权值向量进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行max pooling。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) #单通道的图像数据(28*28)经卷积后变为32通道的特征MAP(28*28)
h_pool1 = max_pool_2x2(h_conv1) # 32通道的特征MAP(28*28)经池化后变为32通道的特征MAP(14*14)
第二层卷积
为了构建一个更深的网络,我们会把几个类似的层堆叠起来。第二层中,5x5的卷积核共得到64通道的特征MAP。
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) #32通道的特征MAP(14*14)经卷积后变为64通道的特征MAP(14*14)
h_pool2 = max_pool_2x2(h_conv2) # 64通道的特征MAP(14*14)经池化后变为64通道的特征MAP(7*7)
密集连接层(为了将现在的特征值的数目进一步减小)
现在,图片尺寸减小到7x7,加入一个有1024个神经元(1024个神经元,意味着W的列数为1024?)的全连接层,用于处理整个图片。我们把池化层输出的张量reshape成一些向量,乘上权重矩阵,加上偏置,然后对其使用ReLU。
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) #将h_pool2这个64通道的特征MAP(7*7)展开到1维进行扁平化,现在h_pool2_flat是一个-1*(7*7*64)的设计矩阵,每行代表1张图片
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) #h_fc1是(-1)*1024的设计矩阵。
Dropout
为了减少过拟合,我们在输出层之前加入dropout。我们用一个placeholder来代表一个神经元的输出在dropout中保持不变的概率。这样我们可以在训练过程中启用dropout,在测试过程中关闭dropout。 TensorFlow的tf.nn.dropout操作除了可以屏蔽神经元的输出外,还会自动处理神经元输出值的scale。所以用dropout的时候可以不用考虑scale。
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
输出层(其实这个等效于TensorFlow学习笔记3-从MNIST开始中的神经元结构)
最后,我们添加一个softmax层,就像前面的单层softmax regression一样。
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
训练和评估模型
这个模型的效果如何呢?
为了进行训练和评估,我们使用与之前简单的单层SoftMax神经网络模型几乎相同的一套代码,只是我们会用更加复杂的ADAM优化器来做梯度最速下降,在feed_dict中加入额外的参数keep_prob来控制dropout比例。然后每100次迭代输出一次日志。
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print "step %d, training accuracy %g"%(i, train_accuracy)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print "test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.assets, y_: mnist.test.labels, keep_prob: 1.0})
以下是完整代码:
# 加载数据
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 产生随机变量,符合 normal 分布
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 产生常量矩阵
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 定义2维的convolutional图层
# strides:每跨多少步抽取信息,strides[1, x_movement,y_movement, 1], 对图片而言,strides[0]和strides[3]必须为1
# padding:边距处理,“SAME”表示输出图层和输入图层大小保持不变,设置为“VALID”时表示舍弃多余边距(丢失信息)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 定义pooling图层
# pooling:解决跨步大时可能丢失一些信息的问题,max-pooling就是在前图层上依次不重合采样2*2的窗口最大值
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
x = tf.placeholder(tf.float32, [None, 784])
x_image = tf.reshape(x, [-1, 28, 28, 1]) # 将原图reshape为4维,-1表示数据是黑白的,28*28=784,1表示颜色通道数目
y_ = tf.placeholder(tf.float32, [None, 10])
### 1. 第一层卷积网络
# 把x_image的厚度由1增加到32,长宽由28*28缩小为14*14
W_conv1 = weight_variable([5, 5, 1, 32]) # 按照[5,5,输入通道=1,输出通道=32]生成一组随机变量
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # 输出size 28*28*32(因为conv2d()中x和y步长都为1,边距保持不变)
h_pool1 = max_pool_2x2(h_conv1) # 输出size 14*14*32
### 2. 第二层卷积网络
# 把h_pool1的厚度由32增加到64,长宽由14*14缩小为7*7
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
### 3. 第一层全连接
# 把h_pool2由7*7*64,变成1024*1
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) # 把pooling后的结构reshape为一维向量
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder('float')
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # 按照keep_prob的概率扔掉一些,为了减少过拟合
### 4. 输出层
#使用softmax计算概率进行分类, 最后一层网络,1024 -> 10,
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))
sess = tf.Session()
sess.run(tf.initialize_all_variables())
for i in range(20000): #训练20000次
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(session = sess, feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
sess.run(train_step, feed_dict = {x: batch[0], y_: batch[1], keep_prob: 0.5})
print('test accuracy %g' % accuracy.eval(session = sess, feed_dict={x: mnist.test.assets, y_: mnist.test.labels, keep_prob: 1.0}))
正确率达到了99.27%。
参考文献
主要参考TensorFlow中文社区网站,深度学习(古德费罗),以及互联网上其他资源。