两大框架图解
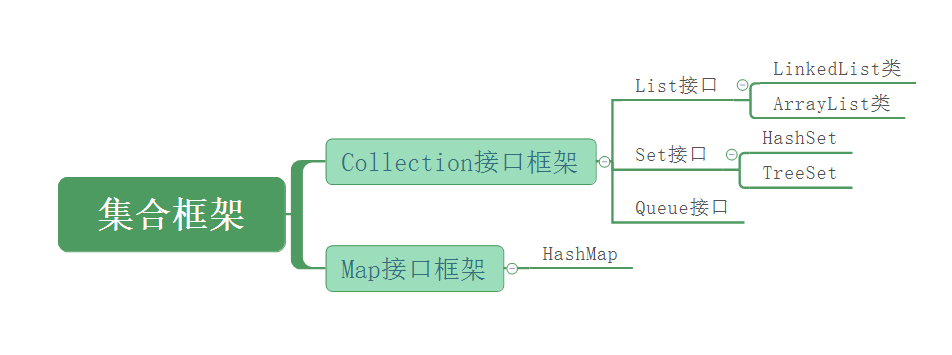
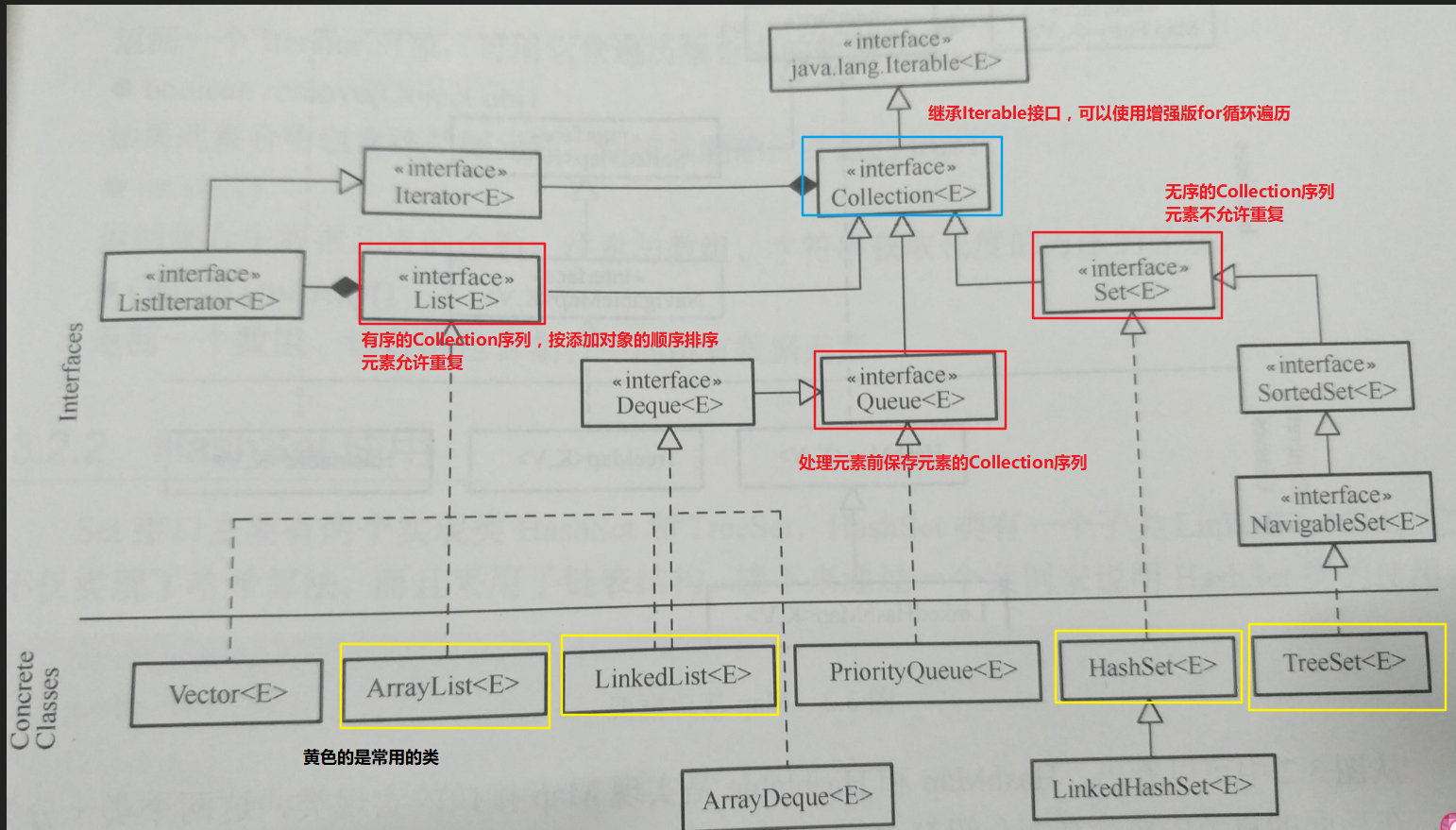
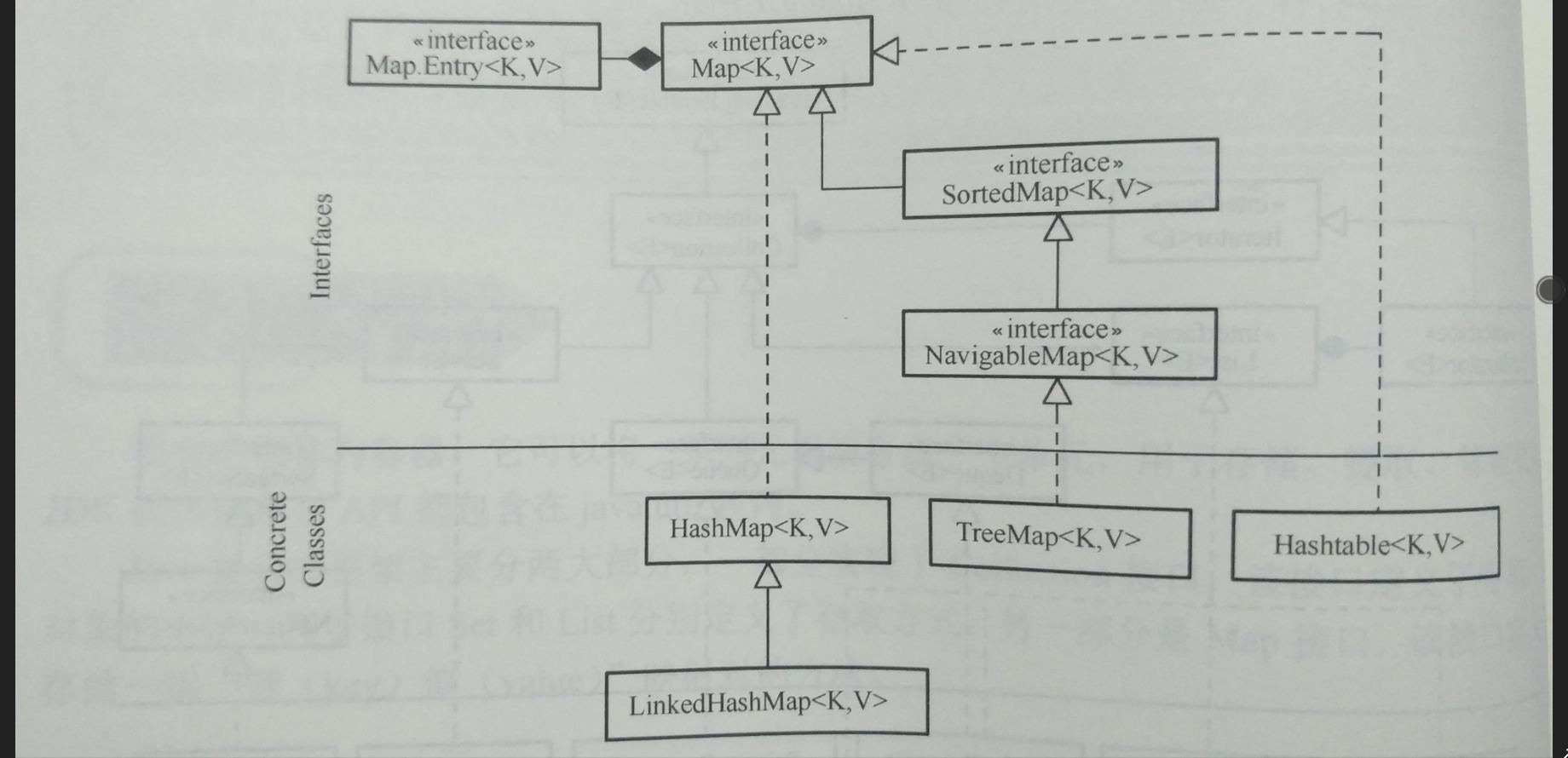
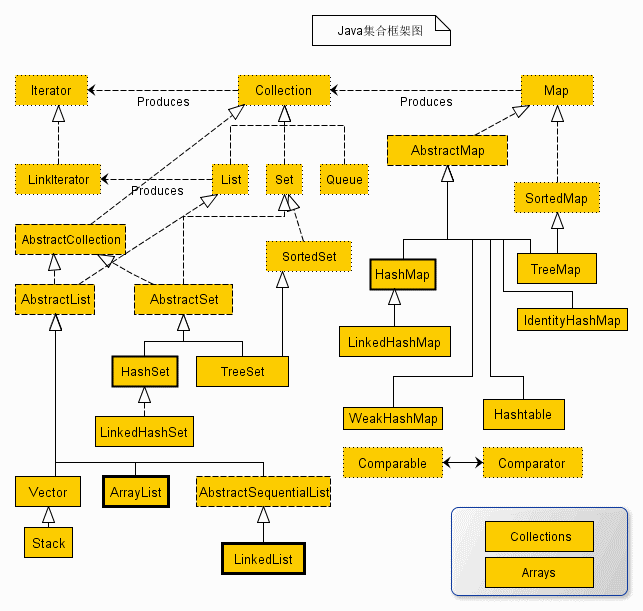
Collection接口
由第一张图,我们可以知道,Collection接口的子接口有三种,分别是List接口,Set接口和Queue接口
List接口
允许有重复的元素,元素按照添加的顺序进行排序
-
接口方法
- void add(int index,Objext o)
在集合的指定位置插入元素 - Object get(int index)
返回集合中某个指定位置的元素 - int indexOf(Object o)
返回第一次出现该元素的索引(下标),如果不包含此元素,返回-1 - int lastIndexOf(Object o)
返回最后一次出现该元素的索引(下标),如果不包含此元素,返回-1 - Object remove(int index)
移除集合某个索引的元素 - Object set(int index,Object o)
用指定的元素替换集合中某个指定下标的数据元素
- void add(int index,Objext o)
-
接口实现类的使用
-
ArrayList
新增方法:
addFirst
getFirst
removeFirst
addLast
getLast
removeLast特点:在存储方式上是采用数组进行顺序存储
List list = new ArrayList(); List<泛型> list = new ArrayList<>(); -
LinkedList
特点:在存储方式上是采用链表进行链式存储
LinkedList<> list = new LinkedList<>();
-
PS:由于ArrayList是采用数组进行存储的,所以添加元素或者是删除元素时,需要批量移动元素,所以性能较差。但查询元素的时候,可以通过下标直接进行访问,所以遍历元素或随机访问元素的时候效率高。
而LinkedList与ArrayList相反
list迭代
如果想在list的迭代中操作list中的元素,例如删除,添加,使用listiterator,listiterator有add,set,remove
List<Book> books = new ArrayList<>();
//添加数据
for (int i = 1; i < 10; i++) {
Book book = new Book();
book.setBno("00" + i);
books.add(book);
}
System.out.println(books.size());
//通过ListIterator在遍历删除数据
ListIterator<Book> bookListIterator = books.listIterator();
String bno = "002";
while (bookListIterator.hasNext()) {
Book next = bookListIterator.next();
if (next.getBno().equals(bno)) {
bookListIterator.remove();
break;
}
}
//输出结果测试
System.out.println("-----");
System.out.println(books.size());
for (Book book : books) {
System.out.println(book.toString());
}Set接口
不允许有重复的元素,元素没有顺序
-
接口方法
addclearcontainsremove
和之前的List差不多,这里就不多说 - 接口实现类的使用
-
HashSet
下面的图片很明显,体现了没有重复元素的规则
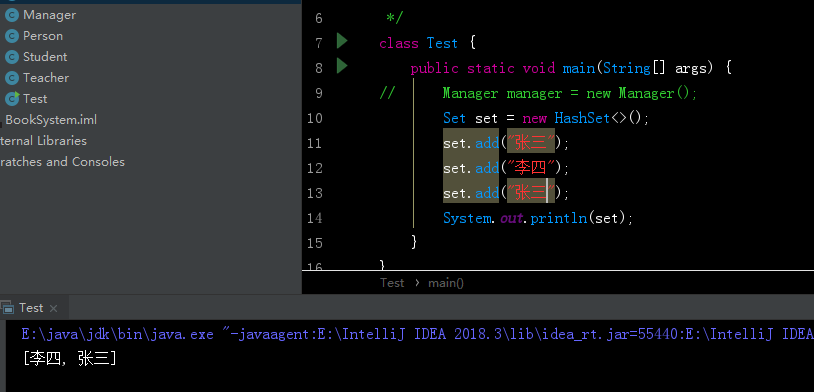
**一般使用的话还是使用泛型使用** Set<Book> books = new HashSet<>(); -
TreeSet
由之前介绍的第四张图可以看到,TreeSet既继承了Set接口,也继承了SortedSet接口(排序接口)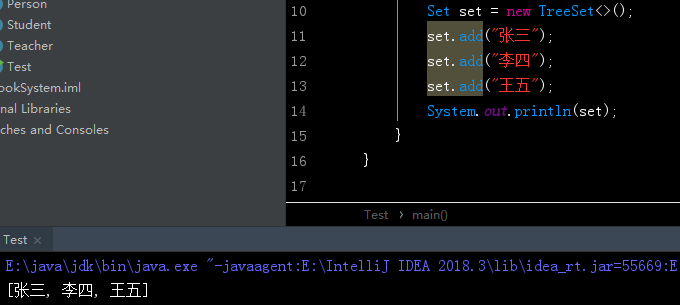
没有使用泛型,默认使用的是String类型,String类实现了Comparable接口,默认是按字典排序,但是图中明显没有实现排序?不理解。。
我使用英文开头,才能实现排序
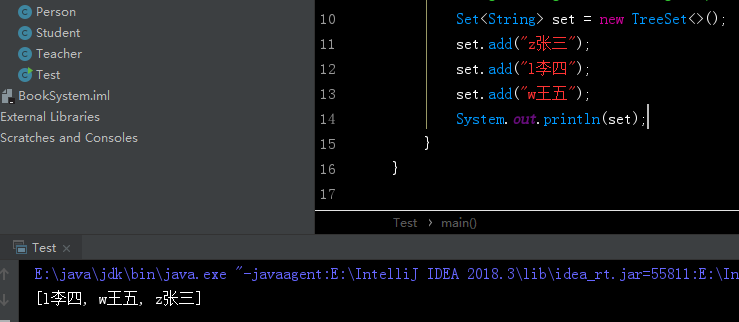
- Set集合遍历
//Iterator Iterator iterator = set.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } //foreach for (String s:set) { System.out.println(s); } -
Queue接口
较少使用。。
Map接口
使用键值对(key value)进行数据存储,key与value是一种映射关系- 接口方法
Object put(Object key,Object value)将一个键值对存到Map中Object get(Object key)由key获得valueObject remove(Object key)删除该键值对Set keyset()返回当前包含当前map的所有key的Set集合Collection values()返回当前包含当前map的所有value的Collection集合boolean containsKey(Object key)是否包含某个keyboolean containsValue(Object Value)是否包含某个Valueint size()返回当前map集合键值对的个数
-
接口实现类的使用
-
HashMap的使用
Map<String,String> map = new HashMap<>();
Map<Integer,String> map = new HashMap<>();
-
TreeMap的使用
Map<String,String> map = new TreeMap<>();
与之前的TreeSet一样,TreeMap也是实现了SortedMap借口,带有排序,默认是按照key的数值自然排序(也就是升序)
-