前言
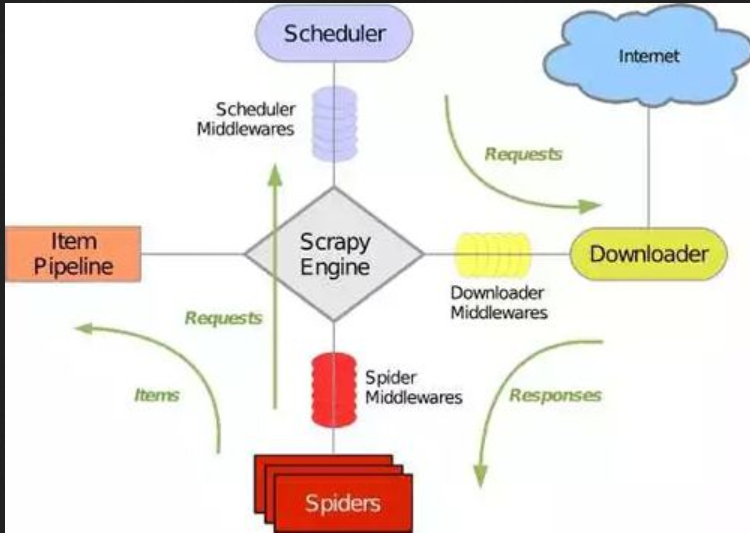
首先我们看一下scrapy架构,
一,分布式爬虫原理:
scrapy爬虫分三大步:
- 第一步,获取url,并生成requests
- 第二步,spider将requests通过引擎,给调度器,调度器将requests放入队列中,等待下载器来取,下载器下载页面后,返回response
- 第三步,spider获取到下载器给的response,解析,存储。
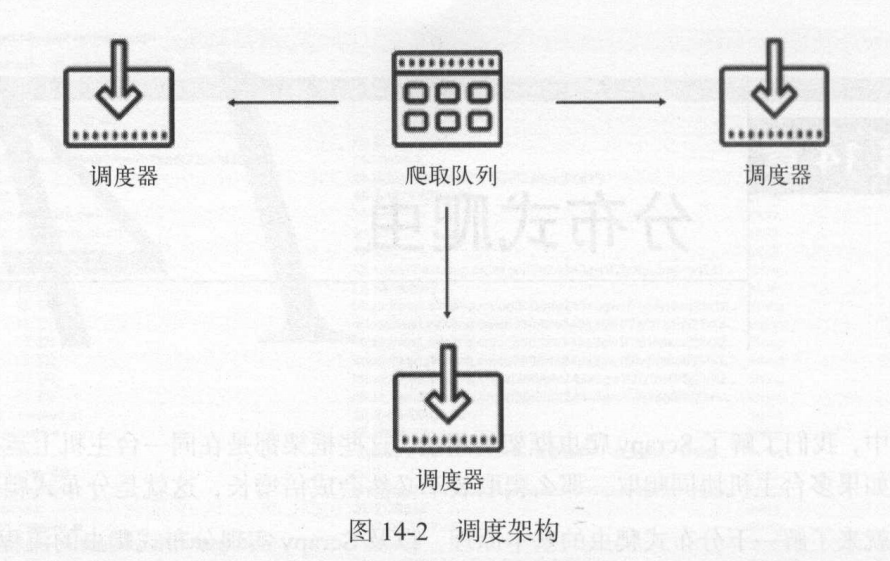
如果我们想进一步提高scrapy的爬取效率,在这三大步中,第一步第三步速度很快,大部分时间是浪费在第二步,只有提高下载器的下载速度才能提高爬取效率。如果两个Scheduler同时从队列里面取 Request ,每个Scheduler 都有其对应的 Downloader,那么
在带宽足够、正常爬取且不考虑队列存取压力的情况下, 爬取效率会有什么 ?没错,爬取效率会翻倍。
这样, Scheduler可以扩展多个,Downloader 也可以扩展多个, 而爬取队列Queue必须始终为1个,也就是所谓的共享爬取队列。 这样才能保证 Scheduer 从队列里调度某个Queue之后,其他 Scheduler 不会重复调度此 Request ,就可以做到多个 Schduler 同步爬取 这就是分布式爬虫的基本雏形
二,redis数据库:
多台主机协同爬取的前提是共享爬取队列,我们将共享爬取队列放入数据库中,方便多台主机同时获取requests,而选择redis数据库主要是以下三个原因。
- 维护爬取队列,分布式爬虫的requests队列是存在于redis数据库中,redis数据库是基于内存存储的数据库,存取效率高。
- 去重问题,既去掉Queue重复的requests,避免重复下载,redis数据库有集合的存储数据结构。每台主机生成的request,和redis数据库中的requests指纹对比,没有的话,就加入集合,有的话,就舍弃掉。
- 防止中断,requests队列是放在数据库中的,爬虫停止后,重新爬取,会按着原来爬取的队列接着爬取,而不是重新爬取。
三,分布式爬虫实现
实现分布式爬虫,首先实现一个共享的爬取队列,还要实现去重的功能,另外,重写一个 Scheduer ,使之可以从共享的爬取队列存取 Request。这些功能前人帮我们实现好了,就是Scrapy-Redis的python包。我们只需要导入直接用就可以了。