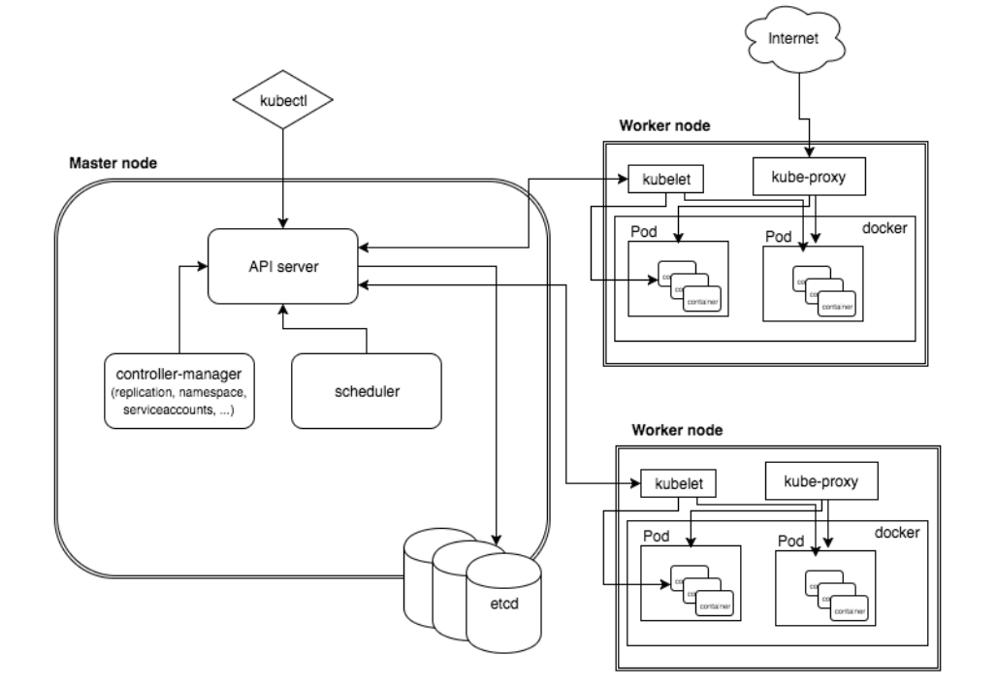
kubernetes 创建Pod 的 工作流:
step.1
kubectl 向 k8s api server 发起一个create pod 请求(即我们使用Kubectl敲一个create pod命令) 。
step.2
k8s api server接收到pod创建请求后,不会去直接创建pod;而是生成一个包含创建信息的yaml。
step.3
apiserver 将刚才的yaml信息写入etcd数据库。到此为止仅仅是在etcd中添加了一条记录, 还没有任何的实质性进展。
step.4
scheduler 查看 k8s api ,类似于通知机制。
首先判断:pod.spec.Node == null?
若为null,表示这个Pod请求是新来的,需要创建;因此先进行调度计算,找到最“闲”的node。
然后将信息在etcd数据库中更新分配结果:pod.spec.Node = nodeA (设置一个具体的节点)
ps:同样上述操作的各种信息也要写到etcd数据库中中。
首先判断:pod.spec.Node == null?
若为null,表示这个Pod请求是新来的,需要创建;因此先进行调度计算,找到最“闲”的node。
然后将信息在etcd数据库中更新分配结果:pod.spec.Node = nodeA (设置一个具体的节点)
ps:同样上述操作的各种信息也要写到etcd数据库中中。
step.5
kubelet 通过监测etcd数据库(即不停地看etcd中的记录),发现 k8s api server 中有了个新的Node;
如果这条记录中的Node与自己的编号相同(即这个Pod由scheduler分配给自己了);
则调用node中的docker api,创建container。
如果这条记录中的Node与自己的编号相同(即这个Pod由scheduler分配给自己了);
则调用node中的docker api,创建container。
kubernetes 创建 ReplicaSet 的 工作流:
ReplicaSet与Pod的不同,就是在流程中增加了与“备份机制”相关的步骤。
step.1
kubectl 发起 create replicaSet 请求
step.2
k8s api server 接受 replicaSet 创建请求,创建yaml。
step.3
k8s api server将yaml的信息写入etcd数据库。
step.4
Controller-Manager中的ReplicaSetController,在etcd数据库中读到了新的replicaSet 信息后,
向k8s api server发起请求,创建3个Pod(个数可以自己指定)。
向k8s api server发起请求,创建3个Pod(个数可以自己指定)。
step.5
scheduler 在etcd中读到相应信息
若 3pod.spec.Node == null
则执行调度计算,找到最“闲”的若干个Node(如果有一个Node真的太闲,可能3个Pod都会被起在这个Node上面)
pod1.spec.Node = nodeA (更新记录)
pod2.spec.Node = nodeB
pod3.spec.Node = nodeA (Node都是随机分配的)
若 3pod.spec.Node == null
则执行调度计算,找到最“闲”的若干个Node(如果有一个Node真的太闲,可能3个Pod都会被起在这个Node上面)
pod1.spec.Node = nodeA (更新记录)
pod2.spec.Node = nodeB
pod3.spec.Node = nodeA (Node都是随机分配的)
将这些信息写回etcd数据库中。
step.6
nodeA 的 kubelet 读etcd时读到apiserver的信息,调用docker api;创建属于自己的pod1/pod3的container
step.7
nodeB kubelet 读到 k8s api server的信息,调用docker api,创建pod2的container。
注意:api server负责各个模块之间的通信。集群内的各个功能模块通过APIServer将信息存入etcd,当需要获取和操作这些数据时,则通过APIServer提供的REST接口(用GET、LIST或WATCH)来实现