博客转载自:https://blog.csdn.net/u010821666/article/details/78793225 原文标题:深度学习结合SLAM的研究思路/成果整理之
1. 深度学习跟SLAM的结合点
深度学习和slam的结合是近几年比较热的一个研究方向,具体的研究方向,我简单分为三块,如下。
1.1 深度学习结合SLAM的三个方向
用深度学习方法替换传统SLAM中的一个/几个模块
- 特征提取,特征匹配,提高特征点稳定性,提取点线面等不同层级的特征点。
- 深度估计
- 位姿估计
- 重定位
- 其他
在传统SLAM之上加入语义信息
- 图像语义分割
- 语义地图构建
端到端的SLAM
其实端到端就不能算是SLAM问题了吧,SLAM是同步定位与地图构建,端到端是输入image输出action,没有定位和建图。
- 机器人自主导航(深度强化学习)等
1.2 相关的部分论文整理
1.2.1 用深度学习方法替换传统SLAM中的一个/几个模块。
替换多个模块
- Tateno K, Tombari F, Laina I, et al. CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction[J]. arXiv preprint arXiv:1704.03489, 2017.
* 在有预测深度下的实时单目稠密SLAM*
(输入:彩色图 LSD-SLAM NYUDv2数据集 ICL-NUIM数据集)
摘要:
基于使用卷积神经网络CNN进行深度预测的最新进展,本文研究了深度神经网络生成的深度预测地图,如何用于精确而稠密的重建,我们提出了一种直接法单目SLAM中得到的深度度量,如何与CNN预测得到的稠密深度地图自然地融合在一起的方法。我们的融合方法在图像定位这一单目SLAM方法效果不佳的方面有优势。比如说低纹理区域,反之亦然。我们证明了深度预测在估计重建的绝对尺度中应用可以克服单目SLAM的主要限制。最后,我们提出了高效融合稠密SLAM中单帧得到的语义标签的方法 ,从单视角中得到了语义连贯的场景重建。基于两个参照数据集的评测结果表明我们的方法有良好的鲁棒性和准确性。
注:
NYUDv2数据集 数据集下载链接
用于室内场景语义分割的RGB-D图像数据集,来自Kinect,1449对已标注的RGB-Depth图像,40万张未标注图像。
ICL-NUIM数据集 数据集下载链接
包含两个场景的图像:起居室和办公室 与TUM RGB-D 数据集的评测工具兼容。帧率30,每段大概几十秒,所以一共几千张图吧。
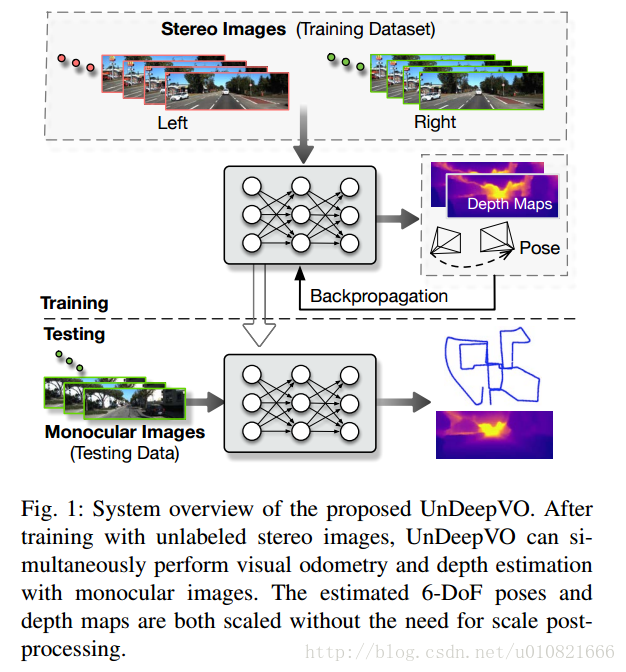
- Li R, Wang S, Long Z, et al. UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning[J]. arXiv preprint arXiv:1709.06841, 2017.
UnDeepVO:使用无监督深度学习的单目视觉里程计
(双目图像训练数据集 单目图像测试 KITTI数据集)
摘要:
我们在本文中提出了一种名叫UnDeepVO的新型的单目视觉里程计系统,UnDeepVO可以估计单目相机的6自由度位姿以及使用深度神经网络估计单目视角的深度。UnDeepVO有两个显著的特性:一个是无监督深度学习方法,另一个是绝对尺度回复。特别的,我们使用了双目的图像对训练UnDeepVO来恢复尺度,然后使用连续的单目图像进行了测试。因此,UnDeepVO是一个单目系统。训练网络的损失函数是基于时间和空间稠密信息定义的。图一是系统的概览图。基于KITTI数据集的实验表明UnDeepVO在位姿估计方面,准确性高于其他的单目VO方法。
特征相关(特征提取匹配等)
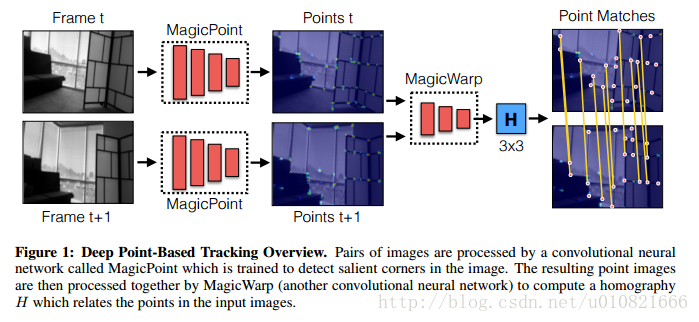
- DeTone D, Malisiewicz T, Rabinovich A. Toward Geometric Deep SLAM[J]. arXiv preprint arXiv:1707.07410, 2017.
面向几何的深度SLAM
(两个CNN,角点提取和匹配 ,实时,单核CPU30FPS)
摘要:
我们展示了一个使用了两个深度卷积神经网络的点跟踪系统。第一个网络,MagicPoint,提取单张图像的显著性2D点。这些提取出来的点可以用作SLAM,因为他们在图像中相互独立且均匀分布。我们比较了这个网络和传统的点检测方法,发现两者在图像有噪声存在是存在明显的性能差异。当检测点是几何稳定的时候,转换估计会变得更简单,我们设计了第二个网络,名为MagicWarp,它对MagicPoint的输出,一系列点图像对进行操作,然后估计跟输入有关的单应性。这种转换引擎和传统方法的不同在于它只是用点的定位,而没有使用局部点的描述子。两个网络都使用了简单的合成数据进行训练,不需要安规的外部相机建立ground truth和先进的图形渲染流水线。系统速度快且轻量级,可以在单核CPU上达到30帧每秒的速度。
- Lecun Y. Stereo matching by training a convolutional neural network to compare image patches[M]. JMLR.org, 2016.
通过训练比较图像块的卷积神经网络进行立体匹配
(输入:左右图 KITTI数据集 Middlebury数据集)
摘要:
我们提出了一种从已校正过的图像对中提取深度信息的方法。我们的方法侧重于大多数stereo算法的第一步:匹配开销计算。我们通过使用卷积神经网络从小图像块中学习相似性度量来解决这个问题。训练采用有监督方式,使用相似和不相似的成对图像块构建了一个二分类数据集。我们研究了用于此项任务的两种网络架构:一个针对速度进行调整,另一个针对精度。卷积神经网络的输出被用来初始化stereo立体匹配开销。在这之后,进行一系列后处理操作:基于交叉的开销聚合,半全局匹配,左右图一致性检验,亚像素增强,中值滤波和双边滤波。我们在KITTI2012,KITTI2015数据集,Middlebury双目数据集上评测了自己的方法,结果显示我们的方法优于此三个数据集上的其他同类方法。

注:Middlebury Stereo Datasets
数据集下载链接
- Kwang Moo Yi, Eduard Trulls, Vincent Lepetit, et al. LIFT: Learned Invariant Feature Transform[J]. 2016:467-483.
LIFT:通过学习生成的不变特征变换
(比SIFT特征更加稠密,已开源)
摘要:
我们提出了一种新型的深度网络架构,实现了完整的特征点处理流水线:检测,方向估计和特征描述。虽然之前的工作已经分别成功地解决了这几个问题,但我们展示了如何将这三个问题结合起来,通知保持端到端的可微性。我们证明了我们的深度流水线方法,性能优于许多基准数据集的state-of-the-art的方法,且不需要再训练。
左边是SIFT,右边是LIFT
源代码 https://github.com/cvlab-epfl/LIFT


位姿估计,深度估计
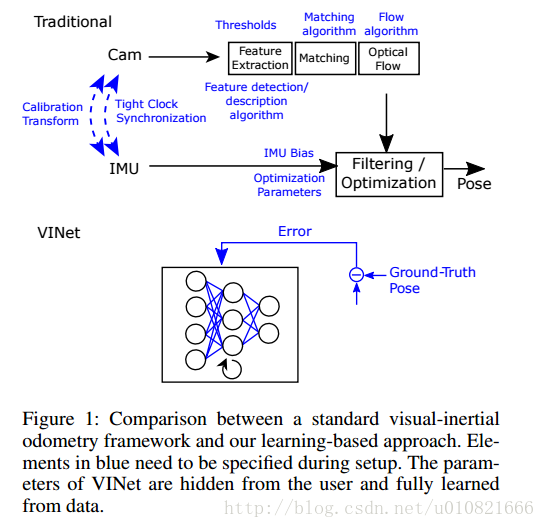
- Clark R, Wang S, Wen H, et al. VINet: Visual-Inertial Odometry as a Sequence-to-Sequence Learning Problem[C]//AAAI. 2017: 3995-4001.
VINet:将视觉-惯性里程计看做一个序列到序列的学习问题(……这个怎么翻)
(使用了图像和IMU数据,CNN和RNN)
摘要:
本文中我们提出了一种使用视觉和惯性数据做运动估计的,流形上的?序列到序列的学习方法。在中间特征表示这一级别上融合数据的视觉-惯性里程计进行端到端训练,是我们已知的最好的方法(?)。我们的方法相比传统方法有很多优势。具体来说,它不需要相机和IMU数据之间进行冗长乏味的人工同步,也同样不需要IMU和相机数据之间进行人工标定。另一个优点是我们的模型可以自然且巧妙地结合特定区域的信息,可以显著减少漂移。在标定数据准确的情况下,我们的方法跟传统的state-of-the-art的方法效果旗鼓相当,在存在标定和同步误差的情况下,我们的方法可以通过训练达到比传统方法更好的的效果。
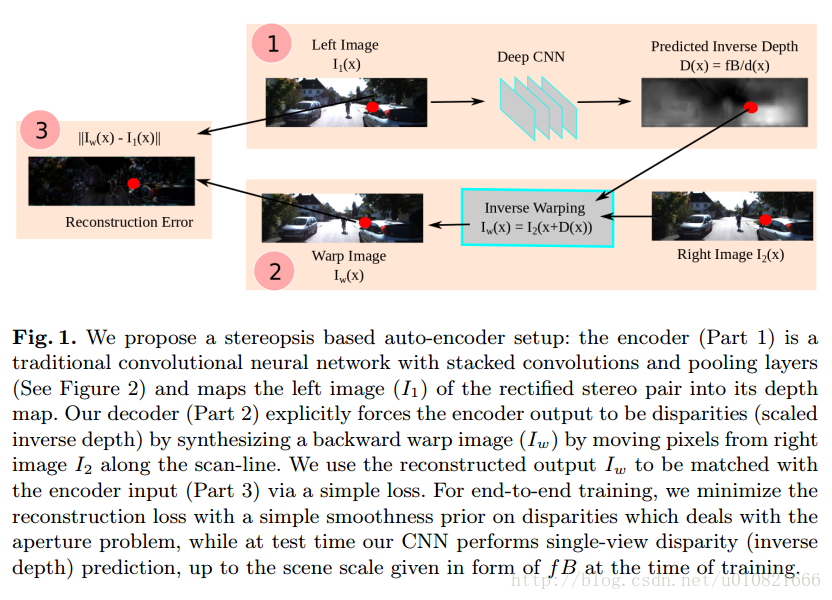
- Garg R, Vijay K B G, Carneiro G, et al. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue[J]. 2016:740-756.
用于单视角深度估计的无监督CNN:??
(KITTI数据集 无监督学习)
摘要:
当前深度卷积神经网络的一个显著缺点就是需要使用大量人工标注的数据来进行训练。本项研究中,我们提出了一种无监督的框架来使用深度卷积神经网络进行单视角深度预测,不需要先行训练和标注过的ground-truth深度。我们通过一种类似于自编码的方式训练网络。训练过程中,我们认为有着微小且已知的相机运动的源图像和目的图像是一个stereo对。我们训练卷积编码器来预测源图像的深度图。为此,我们显式构造了一个使用预测深度和已知的视角间位移的目的图像的inverse warp反变换?,用于重建源图像。重建过程中的光测误差是编码器的重建损失。以这样的方法获取训练数据比同类系统要简单得多,不需要人工标注和深度传感器与相机之间的标定。在KITTI数据集上,执行单视角深度估计任务时,我们的网络,在保证相同性能情况下,训练时间比其他state-of-the-art的有监督方法少一半。
- Xu J, Ranftl, René, Koltun V. Accurate Optical Flow via Direct Cost Volume Processing[J]. 2017.
光流法不太关注,这个名字也是翻译不出来…………
英文摘要:
We present an optical flow estimation approach that operates on the full four-dimensional cost volume. This direct
approach shares the structural benefits of leading stereo matching pipelines, which are known to yield high accuracy. To this day, such approaches have been considered impractical due to the size of the cost volume. We show that the full four-dimensional cost volume can be constructed in a fraction of a second due to its regularity. We then exploit this regularity further by adapting semi-global matching to the four-dimensional setting. This yields a pipeline that achieves significantly higher accuracy than state-of-the-art optical flow methods while being faster than most. Our approach outperforms all published general-purpose optical flow methods on both Sintel and KITTI 2015 benchmarks.

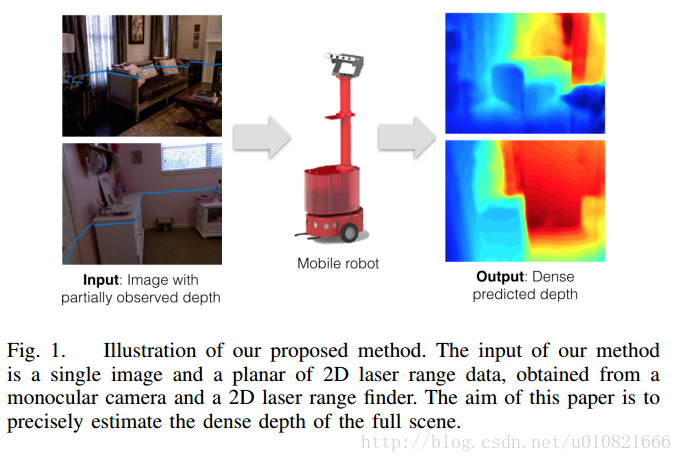
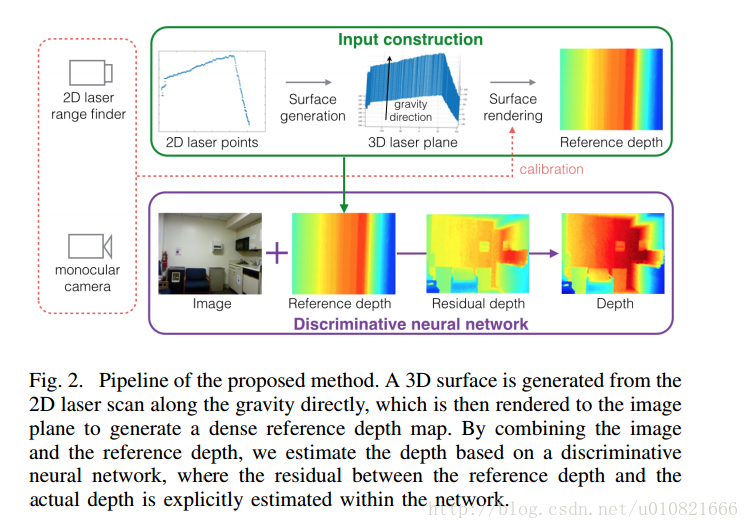
- Liao Y, Huang L, Wang Y, et al. Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation[J]. 2017.
一条线上的解析几何:使用部分激光观测的单目深度估计
(输入:单目图像和2D激光距离数据 NYUDv2数据集 KITTI数据集)
激光的也不太关注。
Abstract— Many standard robotic platforms are equipped with at least a fixed 2D laser range finder and a monocular camera. Although those platforms do not have sensors for 3D depth sensing capability, knowledge of depth is an essential part in many robotics activities. Therefore, recently, there is an increasing interest in depth estimation using monocular images. As this task is inherently ambiguous, the data-driven estimated depth might be unreliable in robotics applications. In this paper, we have attempted to improve the precision of monocular
depth estimation by introducing 2D planar observation from the remaining laser range finder without extra cost. Specifically, we construct a dense reference map from the sparse laser range data, redefining the depth estimation task as estimating the distance between the real and the reference depth. To solve the problem, we construct a novel residual of residual neural network, and tightly combine the classification and regression losses for continuous depth estimation. Experimental results suggest that our method achieves considerable promotion compared to the state-of-the-art methods on both NYUD2 and KITTI, validating the effectiveness of our method on leveraging the additional sensory information. We further demonstrate the potential usage of our method in obstacle avoidance where our methodology provides comprehensive depth information compared to the solution using monocular camera or 2D laser range finder alone。
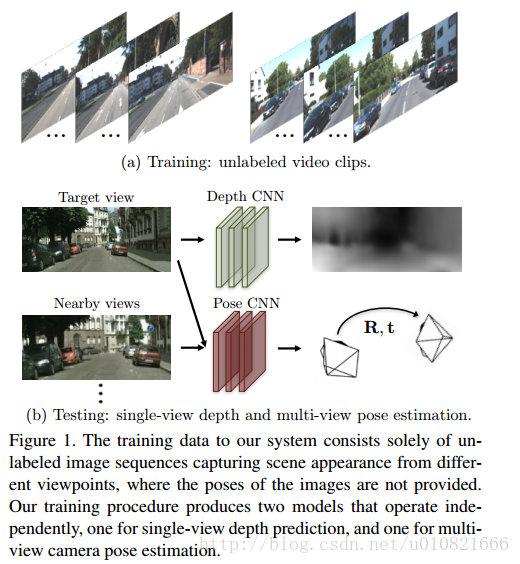
- Zhou T, Brown M, Snavely N, et al. Unsupervised learning of depth and ego-motion from video[J]. arXiv preprint arXiv:1704.07813, 2017.
视频深度和自运动的无监督学习 SFM-learner
(训练使用未标注单目视频片段,已开源)
摘要:我们提出了一个用非结构化视频序列进行单目深度和相机运动估计的无监督学习网络。和最近的几项研究相同的是,我们使用了端到端的方法,用视图合成作为监督信号,不同的是,我们的方法是完全无监督的,只需要少量的单目视频序列即可训练。我们的方法使用了单视角深度和多视角位姿两个网络,使用计算出的深度和位姿将附近视图变换为目标视图生成损失函数(?)。因此,训练过程中网络通过损失函数连接在一起,但是测试时,两个网络可以独立用于应用。KITTI数据集上的经验评测证明我们的方法有以下优点:1)与使用ground-truth位姿或深度进行训练的有监督方法相比,在估计单目深度是效果相当。2)与有可比较输入设置的现有SLAM系统相比,位姿估计性能良好。
源代码 https://github.com/tinghuiz/SfMLearner
- Vijayanarasimhan S, Ricco S, Schmid C, et al. SfM-Net: Learning of Structure and Motion from Video[J]. arXiv preprint arXiv:1704.07804, 2017.
SFM-Net:从视频中学习结构与运动
SfM-Net是SfM-learner的升级版
摘要:
我们提出了SfM-Net,一个geometry-aware几何敏感?的神经网络用于视频中的运动估计,此网络分解了基于场景和对象深度的帧间像素运动,相机运动,3D对象旋转和平移。给定一个帧的序列,SfM-Net预测深度,分割,相机和刚体运动,然后将这些转换为稠密帧间运动场(光流),可微的扭曲帧最后做像素匹配和反向传播。模型可以通过不同程度的监督方法进行训练:1)自监督的投影光测误差(photometric error)(完全无监督)的方式,2)用自运动(相机运动)进行有监督训练的方式,3)使用深度(比如说RGBD传感器提供的)进行有监督训练的方式。SfM-Net提取了有意义的深度估计并成功地估计了帧间的相机运动和评议。它还能在没有监督信息提供的情况下,成功分割出场景中的运动物体。
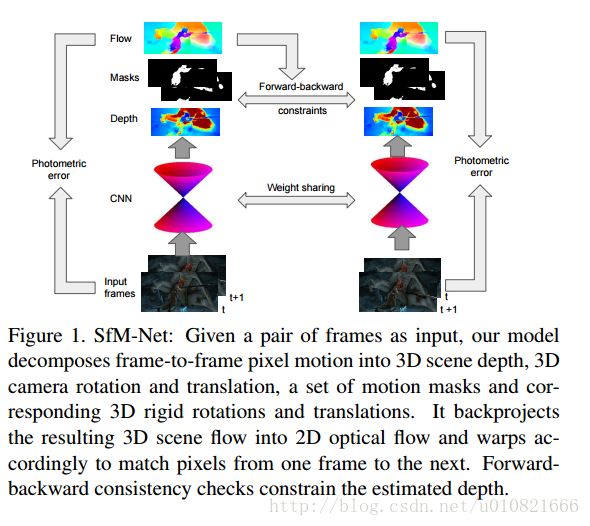
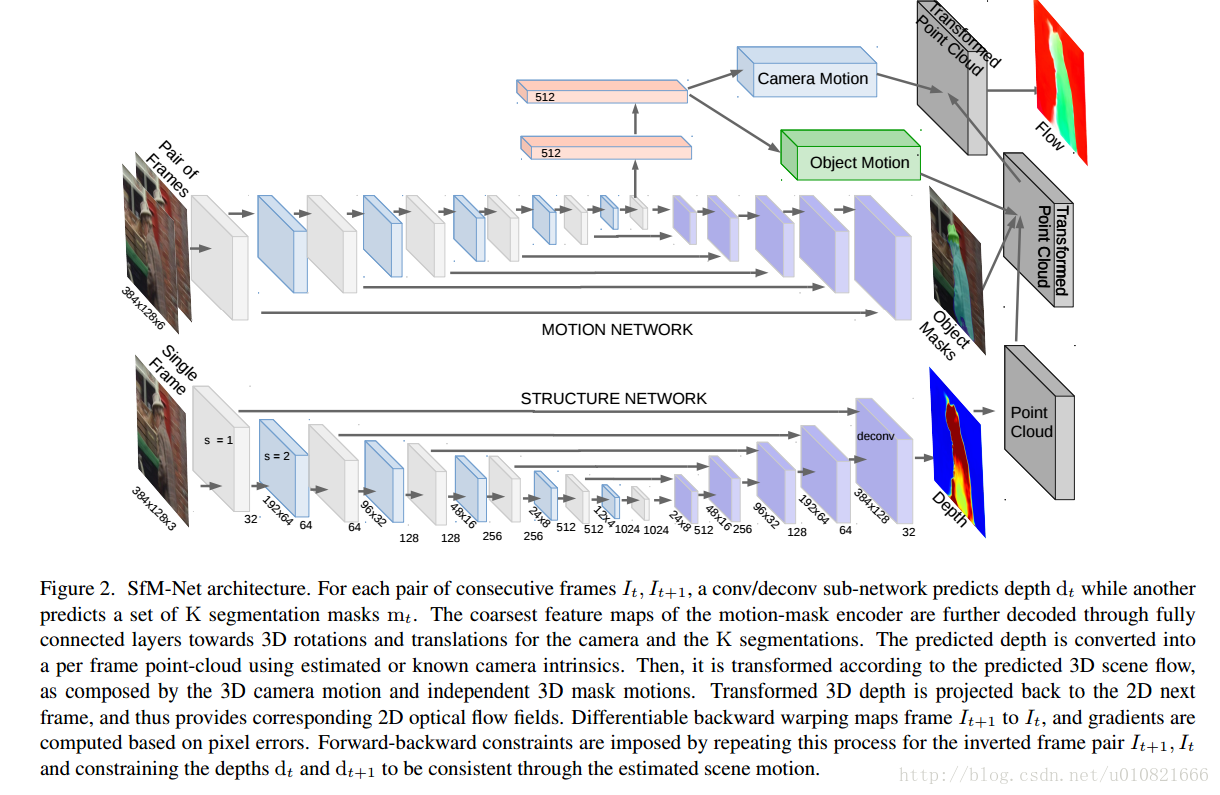
- Benjamin Ummenhofer, Huizhong Zhou, Jonas Uhrig, et al. DeMoN: Depth and Motion Network for Learning Monocular Stereo[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2017:5622-5631.
DeMoN:学习单双目?深度和运动的网络
(已开源)
摘要:
本文中我们将运动中的结构公式化并将其作为一个学习问题。我们端到端地训练了一个卷积网络用于从连续无约束的图像对中计算深度和相机运动。整个架构由多层编解码网络组成,核心部分是一个可以改进自身预测的迭代网络。这个网络不仅估计深度和运动,还可以估计表面法线,图像之间的光流和匹配的脏新都。基于空间相对差异的损失函数是这个方法中至关重要的组成部分。相比于传统的从运动中得到两帧结构的方法,我们的方法更加准确和鲁棒。跟流行的从单张图像获取深度的网络不同的是,DeMoN学习了匹配的概念,能够对训练过程中看不到的结构更好地泛化。
使用pose, depth作为监督信息,来估计pose和depth。
源代码 https://github.com/lmb-freiburg/demon

重定位
可能重定位用深度学习比较难做吧,毕竟是个偏几何的问题,暂时不太关注
- Wu J, Ma L, Hu X. Delving deeper into convolutional neural networks for camera relocalization[C]// IEEE International Conference on Robotics and Automation. IEEE, 2017.
- Alex Kendall, Matthew Grimes, Roberto Cipolla. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization[J]. 2015, 31:2938-2946.
PoseNet:用于实时六自由度相机重定位的卷积神经网络。
PoseNet是2015年的研究成果,算是SLAM跟深度学习结合的比较有开创性的成果。
源代码 https://github.com/alexgkendall/caffe-posenet

另有一篇很有意思的论文
- Vo N, Jacobs N, Hays J. Revisiting IM2GPS in the Deep Learning Era[J]. 2017.
深度学习时代图像-GPS的重定位
思路很有意思,使用一张照片在全世界范围内进行定位。

1.2.2 在传统SLAM之上加入语义信息
图像语义分割&语义地图构建
-
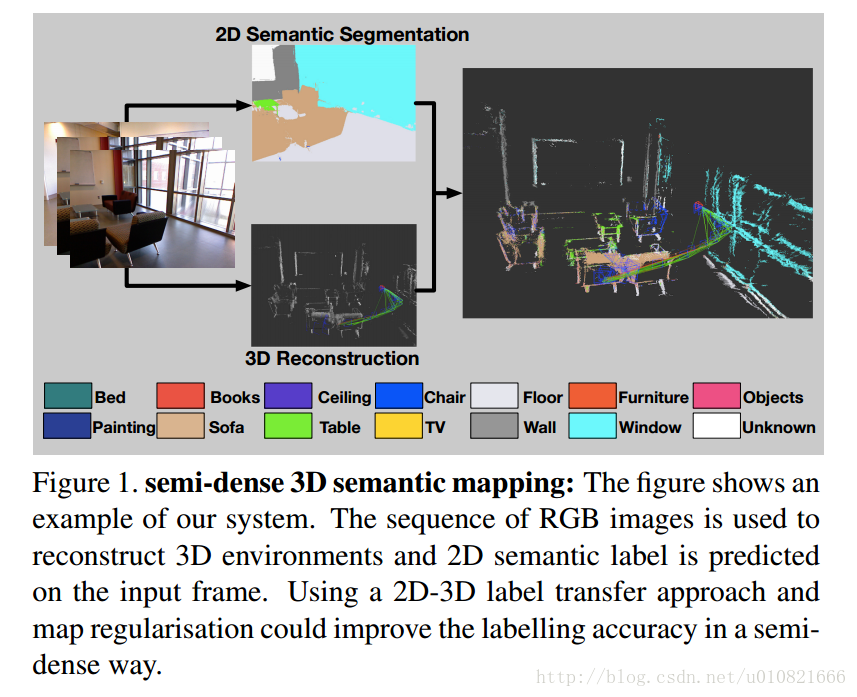
Li X, Belaroussi R. Semi-Dense 3D Semantic Mapping from Monocular SLAM[J]. arXiv preprint arXiv:1611.04144, 2016.
单目SLAM的半稠密语义建图
(LSD-SLAM,室内外场景)
摘要:
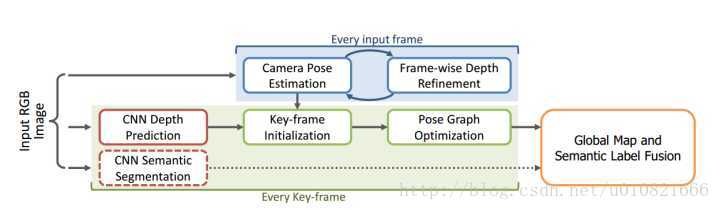
将计算机视觉中的几何与图像相结合,已经被证明是机器人在各种各样的应用中的一种很有发展前景的解决方案。stereo相机和RGBD传感器被广泛用于实现快速三维重建和密集轨迹跟踪。然而,它们缺乏不同规模环境无缝切换的灵活性,比如说,室内和室外场景。此外, 在三维建图中,语义信息仍然很难获取。我们通过结合state-of-art的深度学习方法和半稠密的基于单目相机视频流的SLAM,应对此种挑战。在我们的方法中,二维的语义信息,结合了有空间一致性的相连关键帧之间的correspondence对应关系之后,再进行三维建图。在这里并不需要对一个序列里的每一个关键帧进行语义分割,所以计算时间相对合理。我们在室内室外数据集上评测了我们的方法,在通过baseline single frame prediction基准单帧预测实现二维语义标注方面取得了效果的提升。基本框架图如下:
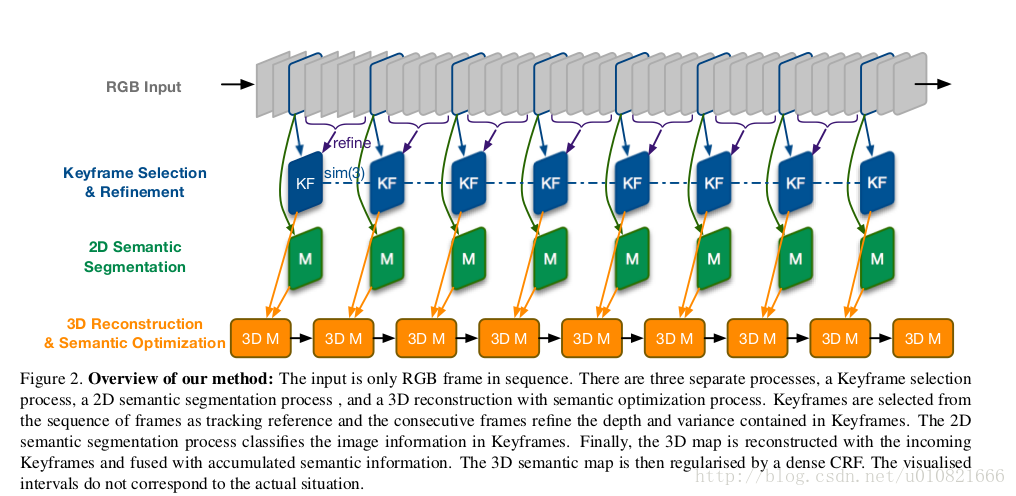
输入RGB图像->选择关键帧并refine->2D语义分割->3D重建,语义优化
- Sünderhauf N, Pham T T, Latif Y, et al. Meaningful Maps With Object-Oriented Semantic Mapping[J]. 2017.
这个题目怎么翻译是好?面向对象语义建图的有意义地图
(输入:RGB-D图像 SSD ORB-SLAM2)
摘要:
智能机器人必须理解它们周围场景的几何和语义两方面的特性,才能跟环境进行有意义地交互。到目前为止,大多数研究已经分别解决了这两个建图问题,侧重于几何信息建图或者是语义信息建图。在本文中我们解决了,既包含有语义意义和对象级别的实体,也包含基于点或网格的几何表示的环境地图构建的问题。我们同时也对已知对象类别中看不到的实例建立了几何点云模型,并建立了以这些对象模型为中心实体的地图。我们的系统利用了稀疏的基于特征的RGB-D SLAM,基于图像的深度学习目标检测方法和三维无监督的分割方法。
基本框架图如下:
输入RGB-D图像 -> ORB-SLAM2应用于每一帧,SSD(Single Shot MultiBox Detector)用于每一个关键帧进行目标检测,3D无监督分割方法对于每一个检测结果生成一个3D点云分割 -> 使用类似ICP的匹配值方法进行数据关联,以决定是否在地图中创建新的对象或者跟已有对象建立检测上的关联 -> 地图对象的3D模型(3D点云分割,指向ORB-SLAM2中位姿图的指针,对每个类别的累计置信度)
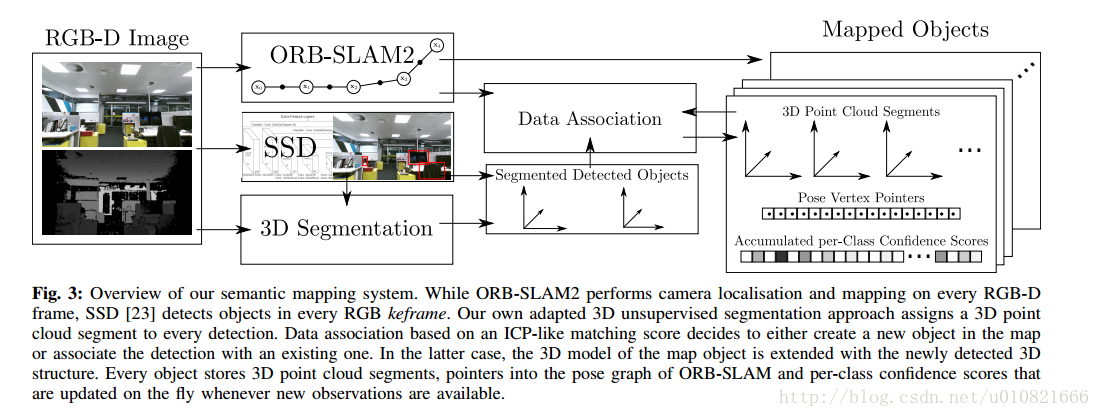
- Ma L, Stückler J, Kerl C, et al. Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras[J]. 2017.
基于RGB-D相机和多视角深度学习的一致语义建图
(NYUDv2数据集 )
摘要:
视觉场景理解是使机器人能够在环境中进行有目的的行动的一项重要的能力。本文中,我们提出了一种新型的深度神经网络方法以在RGB-D图像序列中进行语义分割。主要的创新点在于用一种自监督的方式训练我们的网络用于预测多视角一致的语义信息。在测试时,此网络的基于语义关键帧地图的语义预测,相比单视角图片训练出来的网络上的语义预测,融合的一致性更高。我们的网络架构基于最新的用于RGB和深度图像融合的单视角深度学习方法来进行语义风格,并且通过多尺度误差最小化优化了这一方法的效果。我们使用RGB-D SLAM得到相机轨迹,并且将RGB-D图像的预测扭曲成ground-truth的标注过的帧,以在训练期间提高多视角的一致性。(不是很理解)(We obtain the camera trajectory using RGB-D SLAM and warp the predictions of RGB-D images into ground-truth annotated frames in order to enforce multi-view consistency during training.)在测试时,多视角的预测被融合到关键帧当中去。我们提出并分析了在训练和测试过程中提高多视角一致性的方法。我们评价了多视角一致性训练的优点,并指出,深度特征的池化和多视角的融合,能够提升基于NYUDv2数据集评价指标的语义分割的性能。我们端到端方式训练的网络,在单视角分割和多视角语义融合方面,都取得了在NYUDv2数据集下,state-of-art的效果。
注:NYUDv2数据集 数据集下载链接
用于室内场景语义分割的RGB-D图像数据集,来自Kinect,1449对已标注的RGB-Depth图像,40万张未标注图像。

- Mccormac J, Handa A, Davison A, et al. SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks[J]. 2016.
语义融合:使用CNN的稠密3D语义建图
(NYUDv2数据集 室内场景 实时 )
摘要:
使用视觉传感进行更鲁棒,更准确和细节更丰富的建图,已经被证明有利于机器人在各种各样应用中的运用。在接下来的机器人智能和直观的用户交互中,地图需要扩展几何和外观信息–它们需要包含语义信息。我们使用卷积神经网络CNNs和state-of-the-art的稠密SLAM系统,以及提供了即使在多圈扫描轨迹时,也能得到室内RGB-D视频中帧间的长期稠密correspondence对应关系的ElasticFusion来解决这一问题。这些对应关系使得CNN的多视角语义预测,概率上融合到地图中去。此方法不仅能够生成有效的语义3D地图,也表明在NYUv2数据集上,融合多个预测能够提升预测性能,即使是基于基准单帧预测的2D语义标注。同时我们也证明在预测视角变化更多,重建数据集更小时,单帧分割的性能会进一步得到提升。我们的系统能够在实时的情况下有交互地使用,帧率能达到~25HZ。

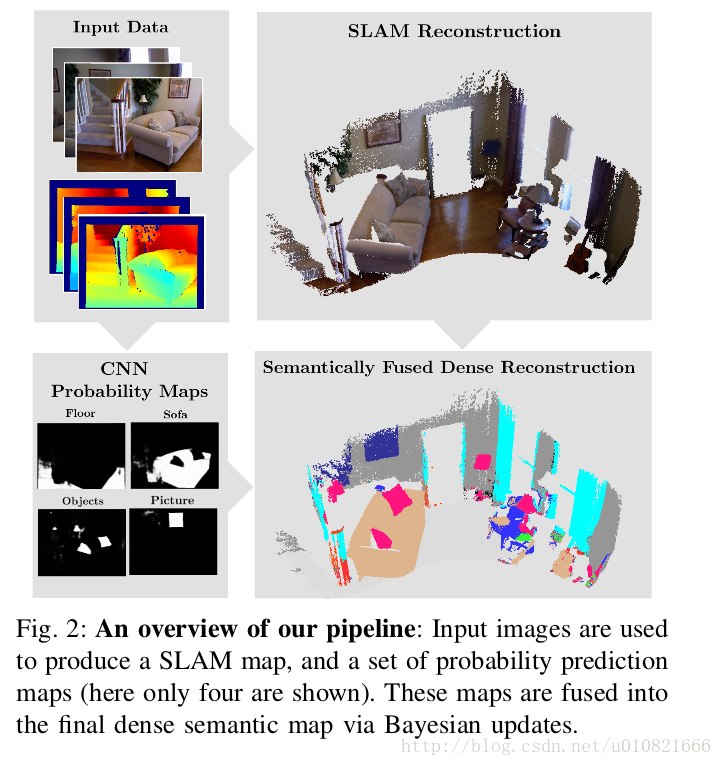
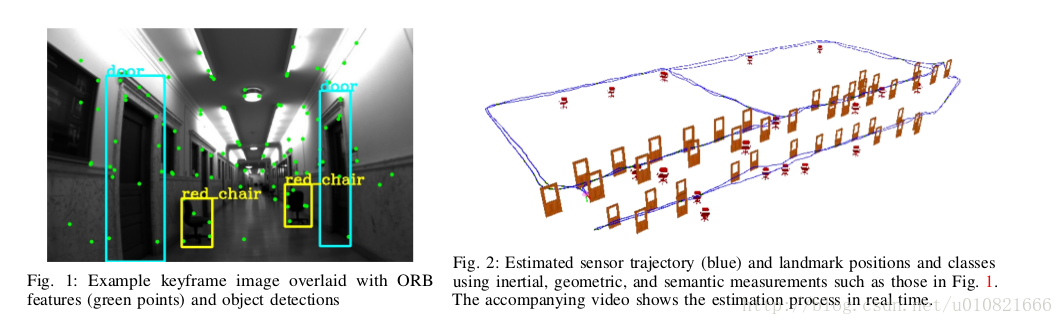
- * Bowman S L, Atanasov N, Daniilidis K, et al. Probabilistic data association for semantic SLAM[C]// IEEE International Conference on Robotics and Automation. IEEE, 2017:1722-1729.*
语义SLAM的概率数据关联
(KITTI数据集 ORB-SLAM2 数学公式多 室内外场景 实时 暂未开源)
摘要:
传统的SLAM方法多依赖于低级别的几何特征:点线面等。这些方法不能给环境中观察到的地标添加语义标签。并且,基于低级特征的闭环检测依赖于视角,并且在有歧义和或重复的环境中会失效。另一方面,目标识别方法可以推断出地标的类型和尺度,建议一个小而简单的可识别的地标集合,以用于视角无关的无歧义闭环。在同一类物体有多个的地图中,有一个很关键的数据关联问题。当数据关联和识别是离散问题时,通常可以通过离散的推断方法来解决,传统SLAM会对度量信息进行连续优化。本文中,我们将传感器状态和语义地标位置的优化问题公式化,其中语义地标位置中集成了度量信息,语义信息和数据关联信息,然后我们由将这个优化问题分解为相互关联的两部分:离散数据关联和地标类别概率的估计问题,以及对度量状态的连续优化问题。估计的地标和机器人位姿会影响到数据关联和类别分布,数据关联和类别分布也会反过来影响机器人-地标位姿优化。我们的算法性能在室内和室外数据集上进行了检验论证。
另,有一篇我很感兴趣的论文,不过跟SLAM没有结合,亮点在于街景的语义分割
Pohlen T, Hermans A, Mathias M, et al. Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes[J]. 2016.
用于街景语义分割的全分辨率残差网络
作者开放了源代码~~https://github.com/TobyPDE/FRRN
1.2.3 端到端SLAM
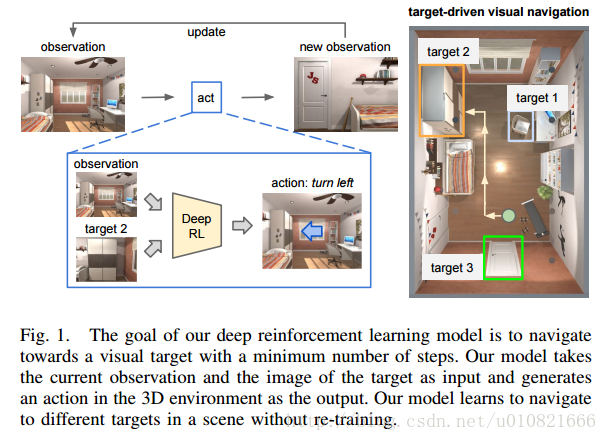
- Zhu Y, Mottaghi R, Kolve E, et al. Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning[J]. 2016.
使用DRL深度加强学习实现机器人自主导航
摘要:
深度强化学习中有两个较少被提及的问题:1. 对于新的目标泛化能力不足,2. 数据低效,比如说,模型需要几个(通常开销较大)试验和误差集合,使得其应用于真实世界场景时并不实用。 在这篇文章中,我们解决了这两个问题,并将我们的模型应用于目标驱动的视觉导航中。为了解决第一个问题,我们提出了一个actor-critic演员评论家模型,它的策略是目标函数以及当前状态,能够更好地泛化。为了解决第二个问题,我们提出了 AI2-THOR框架,它提供了一个有高质量的3D场景和物理引擎的环境。我们的框架使得agent智能体能够采取行动并和对象之间进行交互。因此,我们可以高效地收集大量训练样本。我们提出的方法 1)比state-of-the-art的深度强化学习方法收敛地更快,2)可以跨目标跨场景泛化,3)通过少许微调就可以泛化到真实机器人场景中(尽管模型是在仿真中训练的)4)不需要特征工程,帧间的特征匹配和对于环境的特征重建,是可以端到端训练的。
视频链接
https://youtu.be/SmBxMDiOrvs
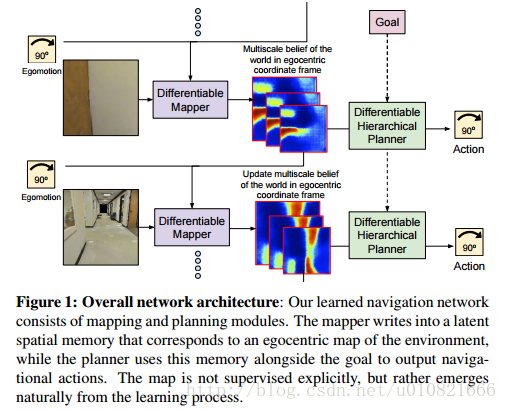
- Gupta S, Davidson J, Levine S, et al. Cognitive Mapping and Planning for Visual Navigation[J]. 2017.
用于视觉导航的感知建图和规划
摘要:
我们提出了一个用于在陌生环境中导航的神经网络结构。我们提出的这个结构以第一视角进行建图,并面向环境中的目标进行路径规划。 The Cognitive Mapper
and Planner (CMP)主要依托于两个观点:1.一个用于建图和规划的统一的联合架构中,建图由规划的需求所驱动的。2. 引入空间记忆,使得能够在一个并不完整的观察集合的基础之上进行规划。CMP构建了一个自上而下的belief map置信地图,并且应用了一个可微的神经网络规划器,在每一个时间步骤中决策下一步的行动。对环境积累的置信度使得可以追踪已被观察到的区域。我们的实验表明CMP的性能优于reactive strategies反应性策略 和standard memory-based architectures 标准的基于记忆的体系结构 两种方法,并且在陌生环境中表现良好。另外,CMP也可以完成特定的语义目标,比如说“go to a chair”到椅子那儿去。
图1:整个网络的架构:我们学习的导航网络由构图和规划模块组成。构图模块负责将环境信息引入到空间记忆中去,空间记忆对应于一个以自身为中心的环境地图。规划器使用这样的空间记忆与导航目标一起输出导航行为。构图模块没有明显的监督机制,而是在学习过程中自然地呈现出来。
谷歌大法好~ 代码,模型,演示视频链接 https://sites.google.com/view/cognitive-mapping-and-planning/
1.3 研究现状总结
用深度学习方法替换传统slam中的一个/几个模块:
目前还不能达到超越传统方法的效果,相较传统SLAM并没有很明显的优势(标注的数据集少且不全,使用视频做训练数据的非常少。SLAM中很多问题都是数学问题,深度学习并不擅长等等原因)。
在传统SLAM之上加入语义信息
语义SLAM算是在扩展了传统SLAM问题的研究内容,现在出现了一些将语义信息集成到SLAM的研究,比如说用SLAM系统中得到的图像之间的几何一致性促进图像语义分割,也可以用语义分割/建图的结果促进SLAM的定位/闭环等,前者已经有了一些研究,不过还是集中于室内场景,后者貌似还没有什么相关研究。如果SLAM和语义分割能够相互促进相辅相成,应该能达到好的效果。
另:使用SLAM帮助构建大规模的图像之间有对应关系的数据集,可以降低深度学习数据集的标注难度吧,应该也是一个SLAM助力深度学习的思路。