Scrapy框架
介绍
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方
式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API
所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。整体架构大致如下:
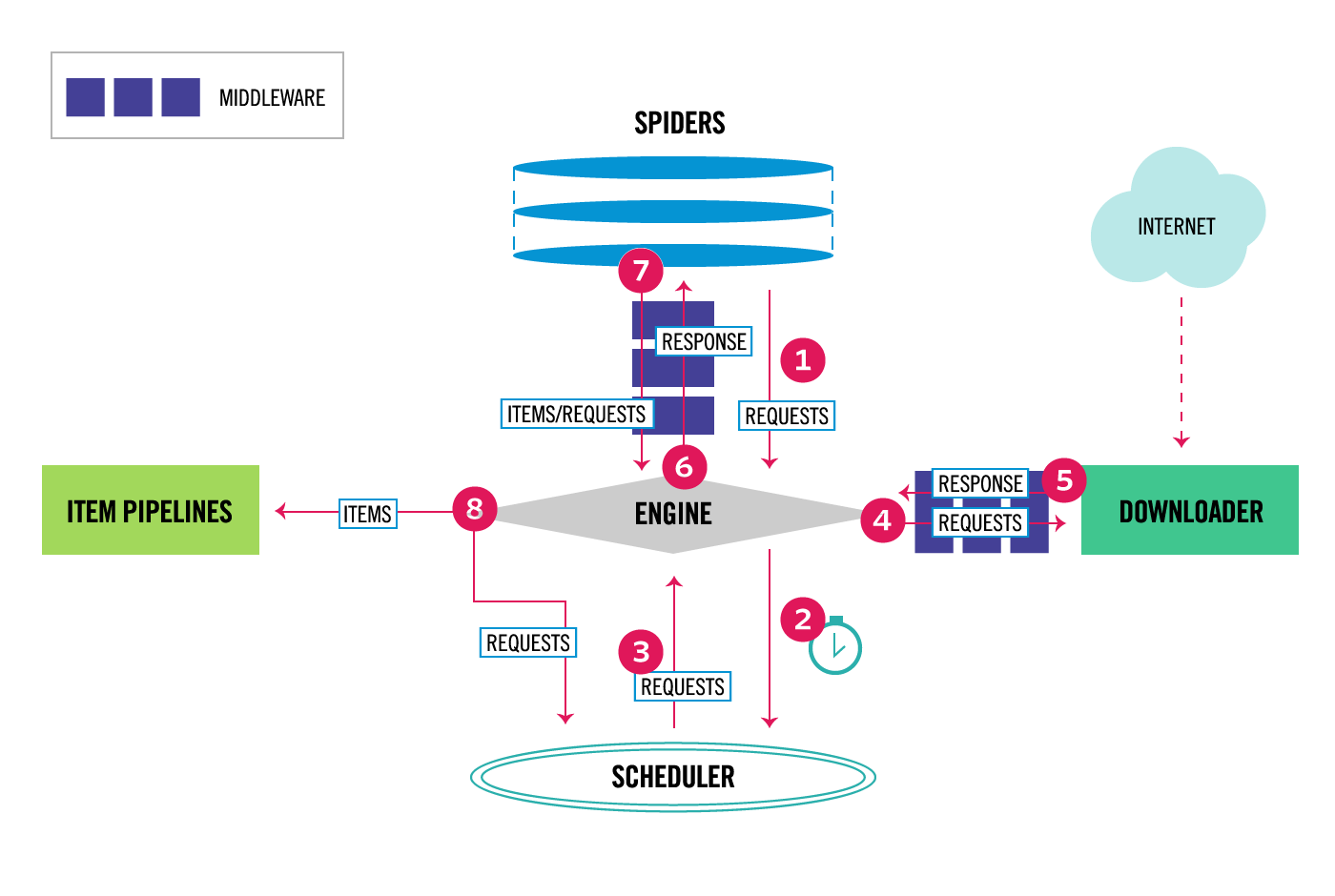
框架构成
- 引擎(Engine)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件.有关详细信息,请参见上面的数据流部分. - 调度器(SCHEDULER)
用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回.可以想像成一个URL的优先级队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址 - 下载器(DOWNLOADER)
用于下载网页内容,并将网页内容返回给引擎,下载器是建立在twisted这个搞笑的异步模型上的。
- 爬虫(spider)
蜘蛛是开发人员自定义的类,用来解析响应,并且提取条目,或者发送新的请求 - 项目管道(ITEM PIPLINES)
在项目被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从egine传到DOWLOADER的请求请求,已经从下载程序传到engine的响应response,
- 爬虫中间件(spider Middlewares)
位于engine和spider之间,主要工作是处理spider的输入(即响应(和输出(即请求)
官网链接:https://docs.scrapy.org/en/latest/topics/architecture.html
流程解读
首先sprider部分就是我们要写的爬虫程序,item pipelines就是用来对数据进行持久化存储的。然后是两个中间件,这些是需要我们来写的。
流程:你写的spider,经过中间件后,交给引擎,引擎然后抛给调度器,让调度器来去重,结束后还给引擎,然后由引擎把这个爬虫通过中间件(和上面的不是同一个)发给下载器,从目标网站获取数据,然后再通过这个中间件给引擎,引擎在发送给管道来进行存储。
安装
#Windows平台
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
只用执行以下命令就行了。
pip install wheel
pip install lxml
pip install pyopenssl
pip install pywin32
pip install twisted
pip install scrapy
以上就完成了安装scrapy。
命令
#1 查看帮助
scrapy -h
scrapy <command> -h
#2 有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要
Global commands:
startproject #创建项目 scrapy startproject 项目名
genspider #创建爬虫程序 scrapy genspider 爬虫名 目标url
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
edit #编辑器,一般不用
parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确
bench #scrapy bentch压力测试,看你能爬多快。
#3 官网链接
https://docs.scrapy.org/en/latest/topics/commands.html
项目文件
.jpg)
spiders:我们写的爬虫就是在这个文件夹下,进入项目根目录下然后执行命令
''scrapy genspider 爬虫名 目标url'',生成的py文件,会自动放进spiders里面。可以在这个文件夹里写多个爬虫。
middlewares:写中间件的地方。
pipelines:管道,来连接数据库的,做持久化存储。
settings:配置文件,如:递归的层数、并发数,延迟下载等。 强调:配置文件的选项必须大写否则视为无效 ,正确写法USER_AGENT='xxxx'
scrapy.cfg:项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中。
items.py: 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
每次想要启动这个爬虫文件都要输入"scrapy crawl 爬虫文件"命令行,会非常麻烦,所以可以写一个run文件,用来启动这个项目。
.jpg)
run.py
from scrapy.cmdline import execute
# "scrapy crawl 爬虫文件" 和这个一一对应
execute(['scrapy','crawl','tmall'])
#上面这个会把信息都打印出来,如果不想看日志信息,就加一个--nolog
execute(['scrapy','crawl','tmall','--nolog'])
然后右键运行这个run文件就好了。
注意:要去settings里面改一个参数 ROBOTSTXT_OBEY = True ,改为False,这个参数是问你是否遵循机器人协议(君子协议)的,如果遵循的话,爬虫都不用干了。
项目流程
# -*- coding: utf-8 -*-
import scrapy
class TmallSpider(scrapy.Spider):
#指定这个爬虫的名字,启动的时候按照这个名字来,而不是文件名
name = 'tmall'
#允许的域名
allowed_domains = ['www.tmall.com']
#开始就会像这里面的路由发送get请求。
start_urls = ['http://www.tmall.com/']
#解析的时候就会调用这个函数。
def parse(self, response):
pass
这里的请求是由框架发送的,如果我们想在这个请求上实现一些逻辑,就目前而已不能实现,所以进Spider的源码看一下。看到一个start_requests方法。
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
#上面都不用去看,就直接看这里。循环start_urls,返回一个可迭代对象。dont_filter=True的意思就是让调度器不去重。
for url in self.start_urls:
yield Request(url, dont_filter=True)
所以如果我们想要在最开始的请求上实现逻辑,就重写这个方法即可。
# -*- coding: utf-8 -*-
import scrapy
class TmallSpider(scrapy.Spider):
name = 'tmall'
allowed_domains = ['www.tmall.com']
start_urls = ['http://www.tmall.com/']
def start_requests(self):
for url in self.start_urls:
#看一下这个Request都有些什么参数,进入源码,看下面就明白了,这里的callback调用了下面的parse,如果我们不指定callback的话,默认也是走parse。
yield scrapy.Request(url=url,callback=self.parse,
dont_filter=True)
#这里的response可以使用各种框架的语法,这里用的是css选择器,也可以用xpath
def parse(self, response):
#这里只会返回一个css对象,如果想要拿到值,不许要加上.extract()
# response.css('[name="totalPage"]::attr(value)')# css对象
# response.css('[name="totalPage"]::attr(value)').extract() #['80']
#response.css('[name="totalPage"]::attr(value)').
#extract_first() # 80
Request
class Request(object_ref):
#这里面我们先只看url和callback和meta和dont_filter以及errback就好了
#url就是请求的url,callback就是回调函数,meta就是放代理ip的,errback是错误处理
def __init__(self, url, callback=None, method='GET', headers=None,body=None,cookies=None, meta=None, encoding='utf-8', priority=0,dont_filter=False, errback=None, flags=None, cb_kwargs=None):
爬取天猫小案例
用一个案例来讲解以上的内容
# -*- coding: utf-8 -*-
import scrapy
from urllib.parse import urlencode
from xiaopapa import items
class TmallSpider(scrapy.Spider):
name = 'tmall'
allowed_domains = ['www.tmall.com']
start_urls = ['http://www.tmall.com/']
def __init__(self,*args,**kwargs):
super(TmallSpider,self).__init__(*args,**kwargs)
self.api = "http://list.tmall.com/search_product.htm?"
def start_requests(self):
self.param = {
"q": "钢铁侠",
"totalPage": 1,
"jumpto": 1,
}
url = self.api + urlencode(self.param)
yield scrapy.Request(url=url,callback=self.gettotalpage,
dont_filter=True)
def gettotalpage(self, response):
#获取“钢铁侠”搜索条件下所有的页码
totalpage = response.css('[name="totalPage"]::attr(value)')
.extract_first()
#转化为整型
self.param['totalPage'] = int(totalpage)
#这里先不用真实的页数,因为请求次数太多了,你的ip会被天猫封掉。
# for i in range(1,self.param['totalPage']+1):
for i in range(1,3):
#jumpto是跳转到下一页的参数,不需要登录就能查看^_^
self.param['jumpto'] = i
url = self.api + urlencode(self.param)
#继续使用回调函数,调用下一个,其实可以都写在一个里面,这么分开写是 为了解耦合
yield scrapy.Request(url=url,callback=self.get_info,
dont_filter=True)
def get_info(self,response):
#拿到包含说有产品标签的列表
product_list = response.css('.product')
for product in product_list:
title = product.css('.productTitle a::attr(title)')
.extract_first()
price = product.css('.productPrice em::attr(title)')
.extract_first()
status = product.css('.productStatus em::text')
.extract_first()
item = items.XiaopapaItem()
item['title'] = title
item['price'] = price
item['status'] = status
yield item
目前就到这里,可以看到这里使用item,看一下item
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class XiaopapaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
把它写成这样,固定写法
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class XiaopapaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
status = scrapy.Field()
再回到上面返回一个item对象。返回到了哪里?
答案就是,返回到了pipelines管道里,做持久化存储,因为我们已经在爬虫文件里做完了数据分析,拿到了想要的数据了,通过item发送给了管道。
接下来看pipelines怎么操作
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class XiaopapaPipeline(object):
def process_item(self, item, spider):
return item
以上是原本的样子,我们应该自己来写
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
class XiaopapaPipeline(object):
def __init__(self,host,port,db,table):
self.host = host
self.port = port
self.db = db
self.table = table
@classmethod
def from_crawler(cls,crawl):
#这里是从配置文件中拿参数,所以需要我们现在settings里配置好数据库参数
port = crawl.settings.get('PORT')
host = crawl.settings.get('HOST')
db = crawl.settings.get('DB')
table = crawl.settings.get('TABLE')
#这里调用上面的__init__,当然也可以不写这个类方法,
#直接在上面的init里面全操作完,这么写主要是为了解耦合
return cls(host,port,db,table)
#在这里开启数据库
def open_spider(self,crawl):
self.client = pymongo.MongoClient(port=self.port
,host=self.host)
db_obj = self.client[self.db]self.table_obj= db_obj
[self.table]
#在这里关闭数据库
def close_spider(self,crawl):
self.client.close()
def process_item(self, item, spider):
#保存数据到mongodb数据库
self.table_obj.insert(dict(item))
return item
settings
除了配置数据库参数之外,一个非常重要的点,就是一定要把一个参数的注释解开。
HOST = '127.0.0.1'
PORT = 27017
DB = 'tmall'
TABLE = 'products'
#这个一定要解开,不然无法保存数据,这个是配置管道的优先级的,数字越小,优先级越高。
ITEM_PIPELINES = {
'xiaopapa.pipelines.XiaopapaPipeline': 300,
}
为什么需要多个管道?
因为有时候你可能需要把所有数据在mongodb存一份,在mysql存一份,在文件里存一份,而且你想要先在mongodb里存,然后再mysql,最后再在文件里存,这时候就可以写三个管道,,如下,就是写一份到文件。
class MyxiaopapaPipeline1(object):
def open_spider(self, crawl):
self.f = open("xxx.txt","at",encoding="utf-8")
def close_spider(self, crawl):
self.f.close()
def process_item(self, item, spider):
self.f.write(json.dumps(dict(item)))
return item
注意:比如你爬了10000条数据,不是10000条先全部存到mongodb再存下一个数据库,因为他是基于多线程的,所以爬取的数据都是异步的,是一条一条从爬虫文件里yield出来被管道接收的,所以是一条先给优先级最高的存,然后再优先级第二的,以此类推。
请求头配置
settings
#这是全局的请求头配置
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"
}
中间件配置
DOWNLOADER_MIDDLEWARES = {
'myxiaopapa.middlewares.xiaopapaDownloaderMiddleware': 300, # 数值越小,优先级越高
# 'myxiaopapa.middlewares.xiaopapaDownloaderMiddleware1': 400, # 数值越小,优先级越高
# 'myxiaopapa.middlewares.xiaopapaDownloaderMiddleware2': 500, # 数值越小,优先级越高
}
通常不太可能出现三个中间件,两个就足够了,一个用来走代理池,一个用来搞请求头。
.jpg)