前奏:
日常会遇到一个表里存在许多的数据,其实是存在一定的弊端的:
1、组织结构不清晰
2、浪费硬盘空间
3、扩展性极差
上述的弊端产生原因类似于把代码全部写在一个py文件里,此时我们最好将其拆成多个表格,也就是解耦合。
外键的使用:
多对一的情况:
1、在创建表时,先建被关联的表dep,再建立关联表emp
create table dep(
id int primary key auto_increment,
dep_name char(10),
dep_comment char(60)
);
create table emp(
id int primary key auto_increment,
name char(16),
gender enum('male','female') not null default 'male',
dep_id int,
foreign key(dep_id) references dep(id)
);
2、在插入记录时,必须先插入被关联的表dep后,才能插入关联表emp
insert into dep(dep_name,dep_comment) values
('教学部','辅导学生学习'),
('外交部','形象大使'),
('技术部','解决问题');
insert into emp(name,gender,dep_id) values
('aaa','male',1),
('bbb','male',2),
('ccc','male',1),
('ddd','male',1),
('eee','female',3);
# 当想修改emp里的dep_id或dep里面的id时返现都无法成功 此处的dep是被关联的表
# 当想删除dep表的教学部的时候,也无法删除
# 方式:先删除教学部对应的所有的员工,再删除教学部,也就是先把关联的emp表的教学部所对应的数据全删除。
# 此时产生一个问题:受限于外键约束,导致操作数据变得非常复杂,能否有一张简单的方式,让我不需要考虑在操作目标表的时候还去考虑关联表的情况,比如我删除部门,那么这个部门对应的员工就应该跟着立即清空---增加语句: on delete cascade
#此时需要把之前的数据清空,重新操作
create table dep(
id int primary key auto_increment,
dep_name char(10),
dep_comment char(60)
);
create table emp(
id int primary key auto_increment,
name char(16),
gender enum('male','female') not null default 'male',
dep_id int,
foreign key(dep_id) references dep(id)
on update cascade
on delete cascade
);
insert into dep(dep_name,dep_comment) values
('教学部','辅导学生学习'),
('外交部','形象大使'),
('技术部','解决问题');
insert into emp(name,gender,dep_id) values
('aaa','male',1),
('bbb','male',2),
('ccc','male',1),
('ddd','male',1),
('eee','female',3);
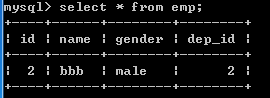
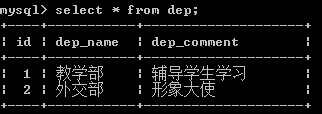
查看表中内容,做个参考
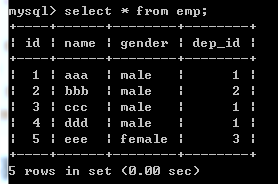
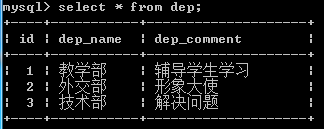
delete from emp where dep_id=1;
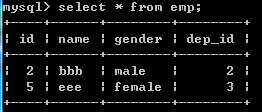
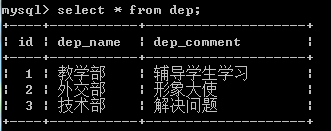
此时发现,删除关联表中的数据,被关联表中数据却不会有什么改变。 原因是:只能通过对被关联的表进行操作,关联的表中数据会自动同步 删除部门后,对应的部门里面的员工表数据会对应删除,更新也是一样 delete from dep where id =3;
多对多
类似于 图书与作者的关系:一本书可以由多个作者一起创作,一个作者可以出版多本书
先来想如何创建表?图书表需要有一个外键关联作者,作者也需要有一个外键字段关联图书。
create table author(
id int primary key auto_increment,
name char(10)
);
create table book(
id int primary key auto_increment,
bname char(10),
price int
);
insert into author(name) values
('aaa'),
('bbb'),
('ccc);
insert into book(bname,price) values
('金瓶妹',200),
('葵花宝',800),
('九阴真经',500),
('九阳神功',100);
到这步会发现,让谁成为被关联对象都不合适
此时需要在创建第三方的一个表来处理这种情况
create table author2book(
id int primary key auto_increment,
author_id int,
book_id int,
foreign key(author_id) references author(id)
on update cascade
on delete cascade,
foreign key(book_id) references book(id)
on update cascade
on delete cascade
);
insert into author2book(author_id,book_id) values
(1,3),
(1,4),
(2,2),
(2,4),
(3,1),
(3,2),
(3,3),
(3,4);
查看原始结果;
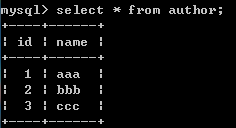
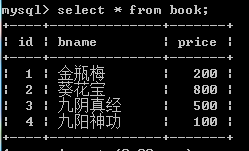

delete from book where id=3;
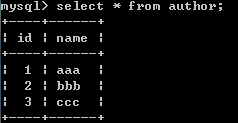
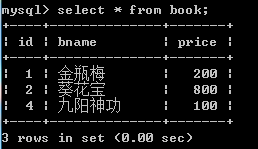

对被关联的book表操作删除了一行数据,关联的表author2book数据会发生改变,另外一个author表没有改变。
一对一:
例如:一个人进入了一家培训机构,发现里面的条件还不错,就选择留下来进修。报名之前是客户,报名之后是学生。
create table customer(
id int primary key auto_increment,
name char(20) not null,
qq char(10) not null,
phone char(16) not null
);
create table student(
id int primary key auto_increment,
class_name char(20) not null,
customer_id int unique, #该字段一定要是唯一的
foreign key(customer_id) references customer(id) #外键的字段一定要保证unique
on delete cascade
on update cascade
);
修改表:
小点:msql对大小写不敏感! 语法: 1、修改表名 alter table 表名 rename 新表名 2、增加字段 alter table 表名 add 字段名 数据类型[约束条件] alter table 表名 add 字段名 数据类型[约束条件] first #把增加的字段放到第一位 alter table 表名 add 字段名 数据类型[约束条件] after #把增加的字段放到最后一位 3、删除字段 alter table 表名 drop 字段名 delete from 表名 where 条件 4、修改字段 alter table 表名 change 旧字段名 新字段名 旧数据类型[约束条件] alter table 表名 change 旧字段名 新字段名 新数据类型[约束条件] alter table 表名 modify 字段名 数据类型[约束条件] #modify 只能修改字段类型和完整约束,不能更改字段名
复制表:
理解:查询语句执行的结果也是一张表,将其当成虚拟表 复制表结构+记录 不会复制:主键、外键和索引 create table new_server select * from server; 只复制表结构; select * from server where 1=2; #条件为假,查不到任何记录 create table new_server select * from server where 1=2; #只 存在表的结构。表里的具体数据为空 create table ttt like server; #复制索引和主外键,存在表的结构,但是没有具体的表里的数据。
补充点:表之间的数据转移: 复制旧表的数据到新表(两个表的结果一样) insert into new_form select * from old_form; 复制旧表的数据到新表(两个表的结构不一样) insert into new_form(字段1,字段2....) select 字段1, 字段2,...from old_form;