1.登陆百度AI的官网
1.注册:没有账号注册 2.创建应用
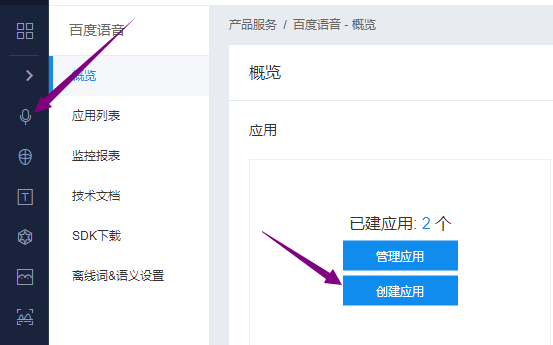
3.创建应用

4.查看应用的ID
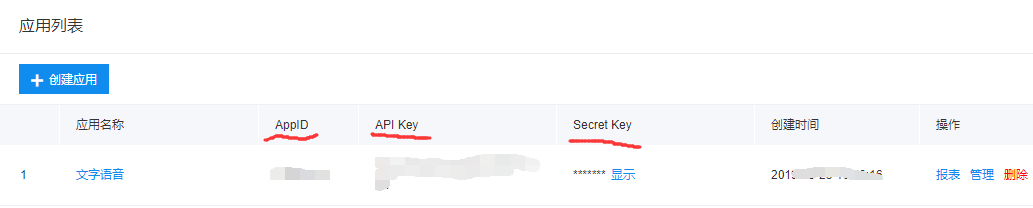
5.Python代码
from aip import AipSpeech APP_ID = "appid " API_KEY="**********" SECRET_KEY="**************" client = AipSpeech(APP_ID,API_KEY,SECRET_KEY)
6.语音识别
# 语音识别
def speech_sb(file_path_name):
os.system(f'ffmpeg -y -i {file_path_name}.m4a -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {file_path_name}.pcm')
with open(f'{file_path_name}.pcm', 'rb') as fp:
return fp.read()
## 调用语音识别
ret = client.asr(speech_sb('123'), 'pcm', 16000, {
'dev_pid': 1536,
})
7.语音合成
#语音合成 def speech_hc(title,text):
# title是生成文件的标题,text是哟啊合成的文本 result = client.synthesis(text) if not isinstance(result, dict): with open(f'{title}.mp3', 'wb') as f: f.write(result) return else: return result
8.自然语言处理加图灵机器人
# 自然语音的处理 def my_npl(text,id):
#传入要对比的文本,id主要用于图灵机器人, print(nlp_client.simnet(text,"你叫什么名字").get('score')) if nlp_client.simnet(text,"你叫什么名字").get('score')>=0.7: ret_name = "我是Sopython,Sopython就是我" return ret_name else: ret_tj = tuling(text,id) if isinstance(ret, dict): ret_tj = ret_tj.get("results")[0].get("values").get('text') print(ret_tj) return ret_tj
#{'corpus_no': '6672231296183866724', 'err_msg': 'success.', 'err_no': 0, 'result': ['叫什么名字'], 'sn': '90391695291553499907'}
ret = my_npl(ret.get('result'),132) # 调用完语音识别之后,获取到识别的结果传入自然语言处理,id=132
# 如果自定义的自然语言处理成功的话,那么就返回自定的结果,否则的话调用图灵机器人来回答问题
# 最后返回处理的结果,
9.图灵机器人
1.注册图灵机器人 2.创建机器人
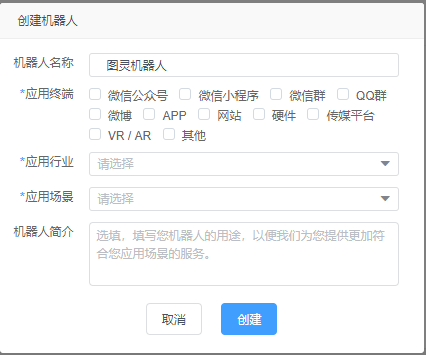
3.Python代码
# 调用图灵的机器人
def tuling(text, id):
data = {
"perception": {
"inputText": {
"text": f"{text}"
}
},
"userInfo": {
"apiKey": "a1f6dbf66978411c9127585f7779cd04",
"userId": f"{id}"
}
}
res = requests.post("http://openapi.tuling123.com/openapi/api/v2", json=data)
# print(res.content)
res_json = res.json()
return res_json
#返回图灵机器人自己的答案
想了解更多关于百度AI信息:http://ai.baidu.com
想了解更多关于图灵机器人信息:http://www.tuling123.com