MySQL详细的攻略和玩法,你值得拥有
基础篇
增
1.创建数据库
create database 数据库名;
2.创建数据库指定字符集
create database 数据库名 character set utf8/gbk;
3.创建表
create table 表名(字段1名 字段1类型,字段2名 字段2类型);
create table student(name varchar(20),age int(2));
4.创建表指定引擎和字符集
create table 表名(字段1名 字段1类型,字段2名 字段2类型) engine=myisam/innodb charset=utf8/gbk;
5.添加表字段
- 最后面添加格式: alter table 表名 add 字段名 字段类型;
- 最前面添加格式: alter table 表名 add 字段名 字段类型 first;
- xxx后面添加格式: alter table 表名 add 字段名 字段类型 after xxx;
6.插入数据
- 全表插入格式: insert into 表名 values (值1,值2,值3);
- 指定字段格式: insert into 表名 (字段1,字段2) values(值1,值2);
- 批量插入:
insert into 表名 values (值1,值2,值3),(值1,值2,值3),(值1,值2,值3),(值1,值2,值3);
insert into 表名 (字段1,字段2) values(值1,值2),(值1,值2),(值1,值2);
删
1.删除数据库 drop database 数据库名;
2.删除表 drop table 表名;
3.删除表字段 alter table 表名 drop 字段名;
4.删除数据 delete from 表名 where 条件;
5.删除表中的所有行 truncate table 表名;
改
1.修改表名 rename table 原名 to 新名;
2.修改表引擎和字符集
alter table 表名 engine=myisam/innodb charset=utf8/gbk;
3.修改字段名和类型
alter table 表名 change 原名 新名 新类型;
4.修改字段类型和位置
alter table 表名 modify 字段名 新类型 first/after xxx;
5.修改数据 update 表名 set 字段名=值,字段名=值 where 条件;
6.修改表中字段的comment信息
alter table 表名 modify column 字段名 字段类型 comment ‘修改后的字段注释’;
查
1.查看所有数据库 show databases;
2.查看数据库详情 how create databse 数据库名;
3.查询所有表 show tables;
4.查看表详情 show create table 表名;
5.查看表字段 desc 表名;
6.查询数据 select 字段信息 from 表名 where 条件;
7.查看所有的注释信息 show full columns from 表名;
提高篇
主键约束与自增
- 什么是主键: 用于表示数据唯一性的字段称之为主键
- 什么是约束: 就是创建表的时候给字段添加唯一的限制条件
- 主键约束: 插入数据库必须是唯一且非空
- 格式:

测试结果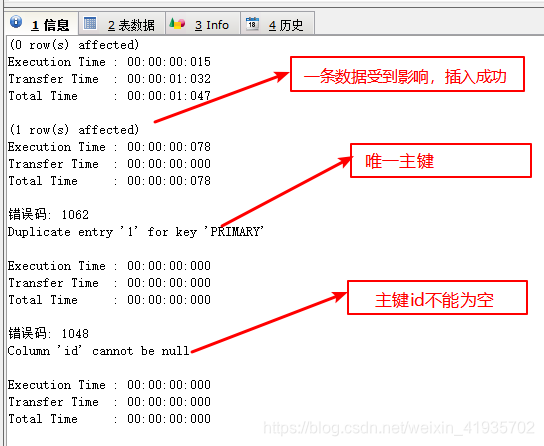
primary key auto_increment - 自增数值只增不减
- 从历史最大值基础上+1
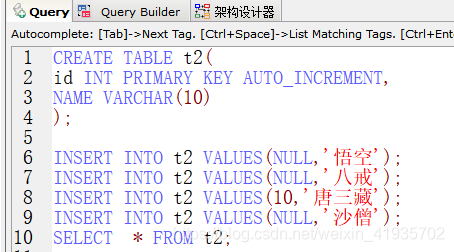
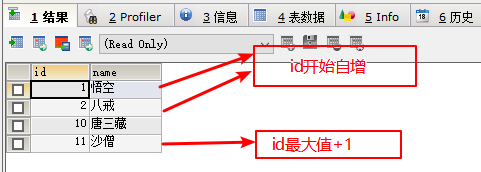

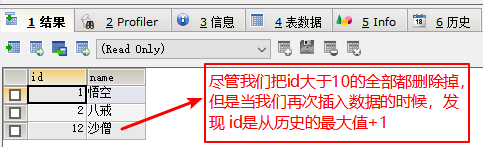
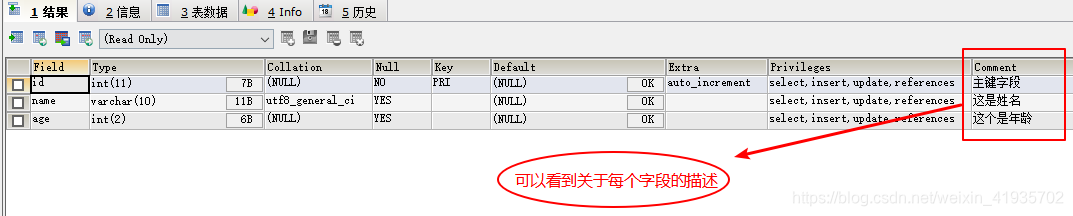
表内字段注释与别名
- 对表的字段进行描述
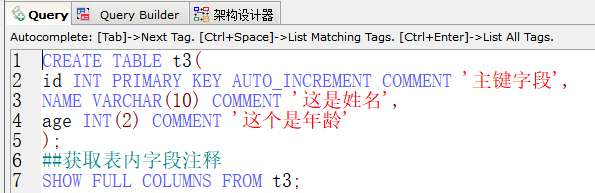
- 获取表内字段注释:SHOW FULL COLUMNS FROM 表名;
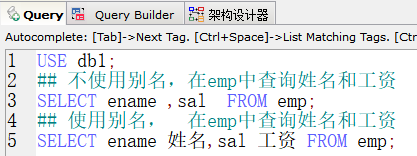
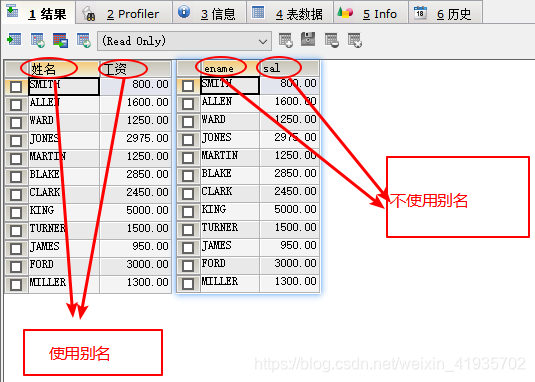
- 别名
is null,not is null与去重
1.查询奖金为null的员工信息
select * from emp where comm is null;
2.查询mgr不为null值得员工姓名
select ename from emp where mgr is not null;
3.去重 distinct
select distinct job from emp;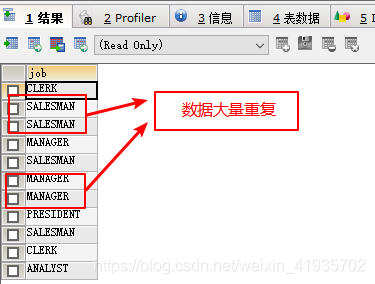
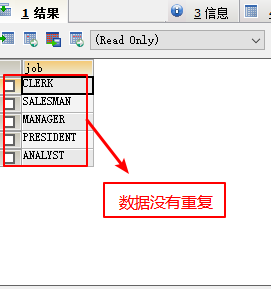
数据类型与日期
-
整数:常用类型int(m) 和 bigint(m), m代表显示长度,需要结合zerofill关键字使用

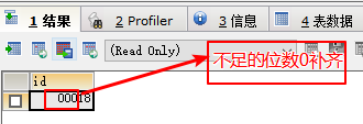
-
浮点数:常用类型 double(m,d) m代表总长度 d代表小数长度 decimal超高精度浮点数,当涉及超高精度运算时使用
-
字符串: char(m)固定长度 执行效率高 最大长度255 varchar(m)可变长度 节省资源 最大65535 超高255建议使用text, text可变长度 最大65535
-
日期:date 只能保存年月日 ,time 只能保存时分秒 ,datetime 最大值 9999-12-31 默认值为null,
timestamp 最大值2038-1-19 默认值 当前的系统时间timestamp 最大值2038-1-19 默认值 当前的系统时间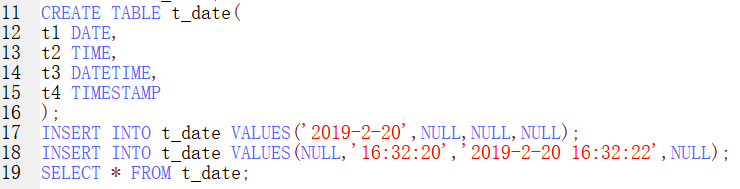
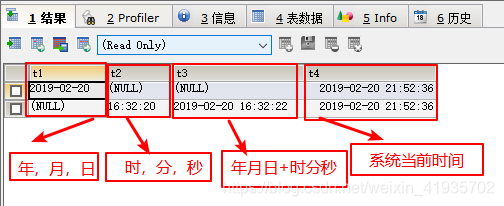
日期相关函数
- 获取当前的年月日时分秒
select now(); - 获取当前的日期 current
select curdate(); - 获取当前的时间
select curtime(); - 从年月日时分秒中提取年月日
select date(now()); - 从年月日时分秒提取时分秒
select time(now()); - 从年月日时分秒中提取时间分量 年 月 日 时 分 秒
- extract(year from now())
- extract(month from now())
- extract(day from now())
- extract(hour from now())
- extract(minute from now())
- extract(second from now())
select extract(year from now());
案例:查询员工表中的所有员工姓名和入职的年份
select ename,extract(year from hiredate) from emp;
比较运算符 > < = >= <= !=和<>
- 查询工资高于2000的所有员工编号empno,姓名ename,职位job,工资sal
select empno,ename,job,sal from emp where sal>2000; - 查询工资小于等于1600的所有员工的编号,姓名,工资
select empno,ename,sal from emp where sal<=1600; - 查询部门编号是20的所有员工姓名、职位、部门编号deptno
select ename,job,deptno from emp where deptno=20; - 查询职位是manager的所有员工姓名和职位
select ename,job from emp where job=‘manager’; - 查询不是10号部门的所有员工编号,姓名,部门编号(两种写法)
select empno,ename,deptno from emp where deptno!=10;
select empno,ename,deptno from emp where deptno<>10; - 查询t_item表单价price等于23的商品信息
select * from t_item where price=23;
select * from t_item where price=23 G; - 查询单价不等于8443的商品标题title和商品单价
select title,price from t_item where price!=8443;
and和or
and 并且&& 需要同时满足多个条件时使用
or 或|| 需要满足多个条件中的某一个条件时使用
- 查询20号部门工资大于2000的员工信息
select * from emp where deptno=20 and sal>2000; - 查询20号部门或者工资小于1000的员工信息
select * from emp where deptno=20 or sal<1000;
in , not in 和between x and y
- 查询工资为5000,950,3000的员工信息
select * from emp where sal=5000 or sal=950 or sal=3000;
select * from emp where sal in (5000,950,3000); - 查询James、king、ford的工资和奖金
select sal,comm from emp where ename in(‘james’,‘king’,‘ford’); - 查询工资不是5000,950,3000的员工信息
select * from emp where sal not in (5000,950,3000); - 查询工资在2000到3000之间的员工信息
select * from emp where sal>=2000 and sal<=3000;
select * from emp where sal between 2000 and 3000;
模糊查询 like
-
_代表单个未知字符
-
%代表0或多个未知字符
-
举例:
以a开头 a%
以b结尾 %b
包含c %c%
第一个字符是a 倒数第二个字符是b a%b_
匹配163邮箱 %@163.com
任意邮箱 %@%.com -
案例:
- 查询员工姓名以k开头的员工信息
select * from emp where ename like ‘k%’; - 查询标题包含记事本的商品标题和商品单价
select title,price from t_item where title like ‘%记事本%’; - 查询单价低于100的记事本
select * from t_item where price<100 and title like ‘%记事本%’;
分页查询和排序
- 分页查询:limit 跳过的条数,请求的条数(每页的条数)
- 查询员工表工资最高的前五条数据
select * from emp order by sal desc limit 0,5;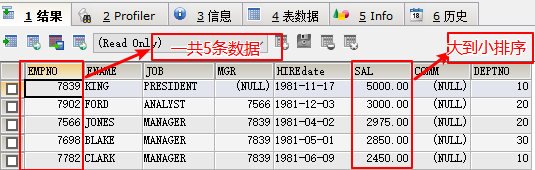
-以上数据的第二页数据
select * from emp order by sal desc limit 5,5; - 查询商品表单价升序第三页每页四条数据
select * from t_item order by price limit 8,4;
- 排序:order by 字段名 asc/desc;
- 查询员工姓名和工资降序
select ename,sal from emp order by sal desc; - 查询30号部门的员工信息 工资降序排序
select * from emp where deptno=30 order by sal desc; - 查询名字中包含a并且工资大于1000的员工信息按照工资升序排序
select * from emp where ename like ‘%a%’ and sal>1000 order by sal;
concat()函数
- 可以将字符串进行拼接
1.查询员工表每个员工的姓名和工资 要求工资显示单位元
select ename 姓名,concat(sal,‘元’) 元 from emp;
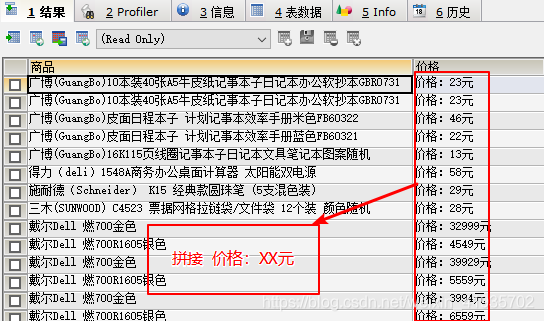
2.查询商品表,显示商品名称,单价(价格:25元)
select title 商品,concat(‘价格:’,price,‘元’) 价格 from t_item;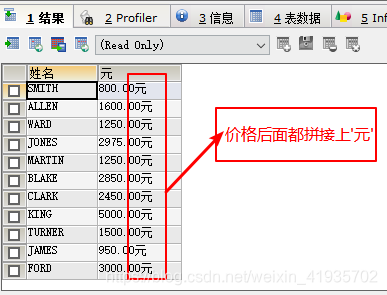
聚合函数
- 对多行数据进行统计查询: 求和 平均值 最大值 最小值 计数
- 求和:sum(求和的字段)
统计20号部门的工资总和
select sum(sal) from emp where deptno=20; - 平均值:avg(字段)
统计所有员工的平均工资
select avg(sal) from emp; - 最大值:max(字段)
查询30号部门的最高工资
select max(sal) from emp where deptno=30; - 最小值:min(字段)
查询30号部门的最低工资
select min(sal) from emp where deptno=30; - 计数: count(字段) 一般写count(*) 只有涉及null值时才使用字段名
查询员工表中10号部门的员工数量
select count(*) from emp where deptno=10;
查询所有员工中有上级领导的员工数量
select count(mgr) from emp;
高级篇
分组查询
- group by 字段名,字段名,按照什么进行分组,当出现每个的时候,往往就需要group by
- 案例:
- 查询每个部门的平均工资
select deptno,avg(sal) from emp group by deptno; - 每个部门的最高工资
select deptno,max(sal) from emp group by deptno; - 每个部门的人数
select deptno,count(*) from emp group by deptno;
having
- where后面只能写普通字段的条件,不能写聚合函数的条件
- having后面可以写普通字段条件,但是不建议这么做,having一般要和分组查询结合使用,后面写聚合函数的条件
- having写在分组查询的后面
- 案例
- 查询每个部门的平均工资,要平均工资大于2000
select deptno,avg(sal) a from emp
group by deptno
having a>2000; - 查询每个分类category_id的平均单价,要求平均单价低于100
select category_id,avg(price) a from t_item
group by category_id
having a<100; - 查询分类category_id为238和917的平均单价
select category_id,avg(price) from t_item
where category_id in(238,917)
group by category_id;
子查询(嵌套查询)
- 案例:
- 查询emp表中工资最高的员工信息
select max(sal) from emp;
select * from emp where sal=5000;
-把上面两条嵌套到一起
select * from emp where sal=(select max(sal) from emp); - 查询emp表中工资大于平均工资的所有员工的信息
select * from emp where sal>(select avg(sal) from emp); - 查询工资高于20号部门最高工资的员工信息
select * from emp where sal>(select max(sal) from emp where deptno=20);
关联查询
- 同时查询多张表的数据的查询方式称为关联查询
- 关联查询时必须写关联关系,如果不写会得到两张表的乘积,这个乘积称为笛卡尔积。这是一个错误的查询结果切记不要出现
- 查询每个员工的姓名和所属部门的名字
select e.ename,d.dname
from emp e,dept d
where e.deptno=d.deptno; - 查询部门地点在new york的 部门名称以及该部门下所有的员工姓名
select d.dname,e.ename
from emp e,dept d
where e.deptno=d.deptno and d.loc=‘new york’;
等值连接和内连接
- 等值连接: select * from A,B where A.x=B.x and A.age=18;
- 内连接:select * from A join B on A.x=B.x where A.age=18;
- 外链接(左外和右外): select * from A left/right join B on A.x=B.x where A.age=18;
- 案例
1.查询每个员工的姓名和对应的部门名称(使用的内连接)
select e.ename,d.dname
from emp e join dept d
on e.deptno=d.deptno;
2.查询所有的部门名称和对应的员工姓名(使用外链接)
select d.dname,e.ename
from emp e right join dept d
on e.deptno=d.deptno;
3.查询工资低于2000的员工姓名、工资和部门信息
select e.ename,e.sal,d.*
from emp e join dept d
on e.deptno=d.deptno
where e.sal<2000;
关联查询总结
- 关联查询的查询方式有几种? 3种:等值连接、内连接、外链接
- 如果查询的是两张表的交集数据使用等值连接或内连接(推荐)
- 如果查询的数据是一张表的全部数据和另外一张表的交集数据使用外链接
表设计之关联关系
一对一
-
什么是一对一:有AB两张表,A表中一条数据对应B表中的一条数据,同时B表中一条数据也对应A表中的一条数据
-
应用场景:用户表和用户信息扩展表,商品表和商品信息扩展表
-
如何建立关系:在从表中添加外键字段指向主表的主键
-
练习: 创建用户表user(id,username,password) 和扩展表userinfo(user_id,nick,loc) 并且保存以下数据
-
建表:
create table user(id int primary key auto_increment,username varchar(10),password varchar(10));
create table userinfo(user_id int,nick varchar(10),loc varchar(10));libai admin 李白 建国门外大街
liubei 12345 刘皇叔 荆州
liudehua aabbcc 刘德华 香港
insert into user values(null,‘libai’,‘admin’),(null,‘liubei’,‘12345’),(null,‘liudehua’,‘aabbcc’);
insert into userinfo values(1,‘李白’,‘建国门外大街’),(2,‘刘皇叔’,‘荆州’),(3,‘刘德华’,‘香港’);
- 查询libai的密码是什么
select password from user where username=‘libai’; - 查询每个用户的用户名和昵称
select u.username,ui.nick
from user u join userinfo ui
on u.id=ui.user_id; - 查询刘德华的用户名
select u.username
from user u join userinfo ui
on u.id=ui.user_id
where ui.nick=‘刘德华’;
一对多
- 什么是一对多:有AB两张表:A表中一条数据对应B表的多条数据,同时B表中的一条数据对应A表的一条数据
- 场景: 员工表和部门表 商品表和商品分类表
- 如何建立关系:在多的表中添加外键指向另外一张表的主键
- 练习:创建t_emp(id,name,dept_id)和t_dept(id,name)
create table t_emp(id int primary key auto_increment,name varchar(10),dept_id int);
create table t_dept(id int primary key auto_increment,name varchar(10));
- 保存以下数据:神仙部门的孙悟空和猪八戒,妖怪部门的蜘蛛精和白骨精
insert into t_dept values(null,‘神仙’),(null,‘妖怪’);
insert into t_emp values(null,‘孙悟空’,1),(null,‘猪八戒’,1),(null,‘蜘蛛精’,2),(null,‘白骨精’,2); - 查询每个员工的姓名和对应的部门名称
select e.name,d.name
from t_emp e join t_dept d
on e.dept_id=d.id; - 查询猪八戒的所在的部门名
select d.name
from t_emp e join t_dept d
on e.dept_id=d.id where e.name=‘猪八戒’; - 查询妖怪部的员工都有谁
select e.name
from t_emp e join t_dept d
on e.dept_id=d.id where d.name=‘妖怪’;
多对多
- 什么是多对多:有AB两张表,A表中的一条数据对应B表中的多条数据,同时B表中的一条数据对应A表中的多条
- 应用场景: 老师表和学生表
- 如何建立关系:通过第三张关系表保存两张主表的关系
- 练习:
创建老师表,学生表和关系表
create table teacher(id int primary key auto_increment,name varchar(10));
create table student(id int primary key auto_increment,name varchar(10));
create table t_s(tid int,sid int);
- 往以上表中保存苍老师的学生小刘和小丽,传奇老师的学生小刘,小王和小丽
insert into teacher values(null,‘苍老师’),(null,‘传奇老师’);
insert into student values(null,‘小刘’),(null,‘小王’),(null,‘小丽’);
insert into t_s values(1,1),(1,3),(2,1),(2,2),(2,3); - 查询每个学生姓名和对应的老师姓名
select s.name,t.name
from student s join t_s ts
on s.id=ts.sid
join teacher t
on t.id=ts.tid; - 查询苍老师的学生都有谁
select s.name
from student s join t_s ts
on s.id=ts.sid
join teacher t
on t.id=ts.tid where t.name=‘苍老师’;
自关联
- 在当前表中添加外键外键的值指向当前表的主键,这种关联方式称为自关联
create table person(id int primary key auto_increment,name varchar(10),mgr int);
保存以下数据: 如来->唐僧->悟空->猴崽子
insert into person values(null,‘如来’,null),(null,‘唐僧’,1),(null,‘悟空’,2),(null,‘猴崽子’,3);
- 查询每个人的名字和上级的名字
select p.name,m.name 上级
from person p left join person m
on p.mgr=m.id;
索引
- 什么是索引: 索引是数据库中提高查询效率的技术,类似于字典的目录
- 为什么使用索引:如果不使用索引数据会零散的保存在每一个磁盘块当中,查询数据时需要挨个的遍历每一个磁盘块查找数据,如果数据量超级大,遍历每一个磁盘块是件非常耗时的事情,添加索引后,会将磁盘块以树桩结构进行保存,查询数据时会有目的性的访问部分磁盘块,因为访问的磁盘块数量降低所以能起到提高查询效率的作用
- 索引是越多越好吗?
不是,因为索引会占磁盘空间,通过某个字段创建的索引可能永远用不上,则这个索引完全没有存在的意义,只需要对查询时频繁使用的字段创建索引 - 有索引就一定好吗?
不一定,如果数据量小使用索引反而会降低查询效率 - 索引的分类(了解)
- 聚集索引(聚簇索引): 通过主键创建的索引为聚集索引,添加了主键约束的表会自动添加聚集索引,聚集索引的树桩结构中保存了数据
- 非聚集索引:通过非主键字段创建的索引叫做非聚集索引,树桩结构中只保存了数据所在磁盘块的地址并没有数据。
索引的使用:
-
创建索引
create index 索引名 on 表名(字段名[(字符长度)]);
CREATE INDEX a ON emp(ename(10));
创建索引之前,对比创建索引之后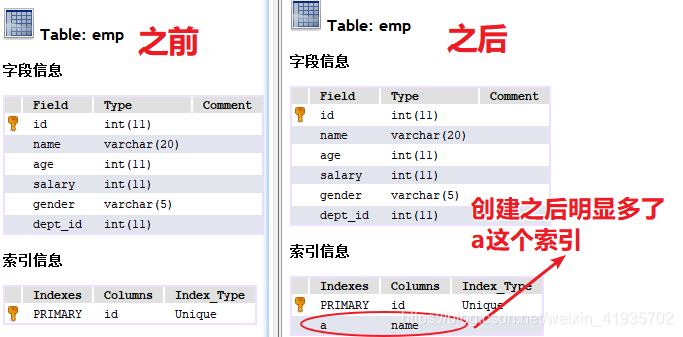
-
查看索引:
show index from emp;
-
删除索引
drop index 索引名 on 表名;
drop index a on emp; -
复合索引
通过多个字段创建的索引称为复合索引
-格式:create index 索引名 on 表名(字段1,字段2);
频繁使用多个字段进行数据查询时为了提高查询效率可以创建复合索引
select * from item2 where title=‘100’ and price<100;
create index i_item2_title_price on item2(title,price);
索引总结:
- 索引是用于提高查询效率的技术,类似目录
- 索引会占用磁盘空间不是越多越好
- 如果数据量小的话 添加索引会降低查询效率
- 尽量不要在频繁改动的表上添加索引
事务
- 什么是数据库中的事务?
事务是数据库中执行同一业务多条SQL语句的工作单元,可以保证多条SQL语句全部执行成功或者全部执行失败 - 事务相关指令:
开启事务 begin;
提交事务 commit;
回滚事务 rollback;
最终奥义
连接数据库(jdbc)
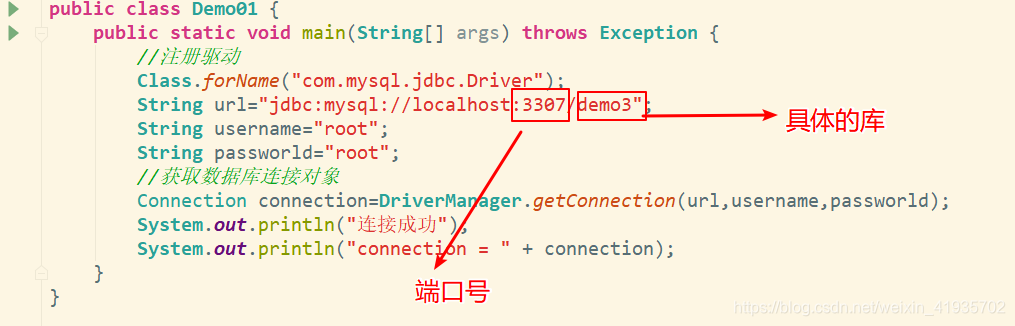
测试结果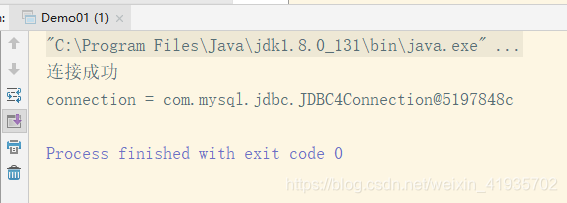
数据库连接池
1.准备配置文件 jdbc.properties

2.创建DBUtils
package Util;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
import org.apache.commons.dbcp.BasicDataSource;
public class DBUtils {
private static String driver;
private static String url;
private static String username;
private static String password;
private static BasicDataSource dataSource;
static {
Properties prop = new Properties();
InputStream ips = DBUtils.class.getClassLoader().getResourceAsStream("jdbc.properties");
try {
prop.load(ips);
driver = prop.getProperty("driver");
url = prop.getProperty("url");
username = prop.getProperty("username");
password = prop.getProperty("password");
// 创建数据源对象
dataSource = new BasicDataSource();
dataSource.setDriverClassName(driver);
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
dataSource.setInitialSize(5);
dataSource.setMaxActive(30);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
ips.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static Connection getConn() throws Exception {
return dataSource.getConnection();
}
public static void close(Connection conn, Statement stat, ResultSet rs) {
try {
if (rs != null) {
rs.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (stat != null) {
stat.close(