1.flume是分布式的日志收集系统,把收集来的数据传送到目的地去。
2.flume里面有个核心概念,叫做agent。agent是一个java进程,运行在日志收集节点。
3.agent里面包含3个核心组件:source、channel、sink。
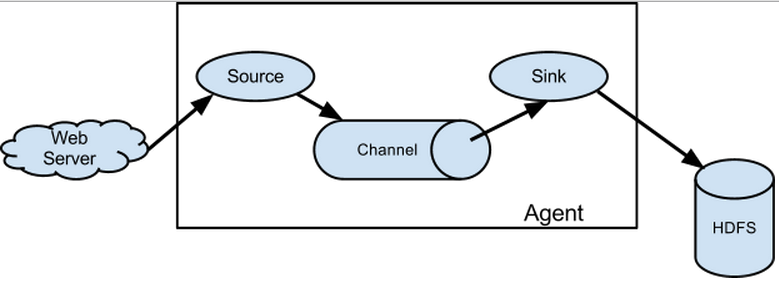
3.1 source组件是专用于收集日志的,可以处理各种类型各种格式的日志数据,包括avro、thrift、exec、jms、spooling
directory、netcat、sequence generator、syslog、http、legacy、自定义。
source组件把数据收集来以后,临时存放在channel中。
3.2 channel组件是在agent中专用于临时存储数据的,可以存放在memory、jdbc、file、自定义。
channel中的数据只有在sink发送成功之后才会被删除。
3.3 sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、
自定义。
4.在整个数据传输过程中,流动的是event。事务保证是在event级别。
5.flume可以支持多级flume的agent,支持扇入(fan-in)、扇出(fan-out)。(扇入,多个文件输入;扇出:输出多个目的地)
6.安装flume
6.1解压flume
执行命令:tar -zxvf apache-flume-1.4.0.bin.tar.gz
tar -zxvf apache-flume-1.4.0.src.tar.gz
6.2(没用)将解压后的apache-flume-1.4.0.src复制到apache-flume-1.4.0.bin下
执行命令:cp -ri apache-flume-1.4.0.src/* apache-flume-1.4.0.bin/
cd apache-flume-1.4.0.bin/ //查看有没有复制过来
6.3改名字
执行命令:mv apache-flume-1.4.0.bin/ flume
6.4书写配置文件example
#agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#Spooling Directory是监控指定文件夹中新文件的变化,一旦新文件出现,就解析该文件内容,然后写入到channle。写入完成
后,标记该文件已完成或者删除该文件。
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/root/hmbbs
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://hadoop0:9000/hmbbs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/root/hmbbs_tmp/123
agent1.channels.channel1.dataDirs=/root/hmbbs_tmp/
7.执行命令bin/flume-ng agent -n agent1 -c conf -f conf/example -Dflume.root.logger=DEBUG,console