来源:《这就是搜索引擎核心技术详解》 2014.5
1搜索引擎及其技术框架
1.1搜索引擎发展史
1)分类目录
“导航时代”,代表:Yahoo和国内hao123。通过人工收集整理,把属于各个类别的高质量网站或者网页分门别类罗列,用户可以根据分级目录来查找高质量的网站。
采取分类目录的方式,一半被收录的网站质量都较高,但是这种方式可扩展性不强,绝大部分网站不能被收录。
2)文本检索
采用经典的信息检索模型,比如:布尔模型、向量空间模型或者概率模型,来计算用户查询关键词和网页内容的相关程度。
相比分类目录,这种方式可以收录大部分网页,并能够按照网页内容和用户查询的匹配程度进行排序,但是总体而言,搜索结果不是很好。
3)链接分析
利用网页之间的链接关系。网页链接代表了一种推荐关系,所以通过链接分析可以在海量内容中找出重要的网页,这种重要性本质上是对网页流行程度的一种衡量,因为被推荐次数多的网页其实代表了其具有流行性。
Google率先提出并使用PageRank链接分析技术,目前几乎所有的商业搜索引擎都采取了链接分析技术。
这种搜索引擎并未考虑用户的个性化要求,所以只要输入的查询要求相同,所有用户都会获得相同的搜索结果。
4)用户中心的一代
以理解用户需求为核心。不同用户即使输入统一查询关键词,但其目的也可能不一样。比如:同样输入“苹果”作为查询词,一个追捧iPhone的时尚青年和一个果农的目的会有相当大的差距。目前搜索引擎大都致力于解决如下问题:如何能够理解用户发出的某个很短小的查询词背后包含的真正需求。
为了能够获取用户的真是需求,搜索引擎做了很多技术方面的尝试。比如利用用户发送查询词的时间和地理位置信息,利用用户过去发出的查询词及相应的点击记录等历史信息等技术手段,来试图理解用户此时此地的真正需求。
1.2搜索引擎的目标
更全:从其索引的网页数量而言的。目前任意一个商业搜索引擎索引网页的覆盖范围都只占了互联网页面的一部分,可以通过网络爬虫相关技术来达到此目标。
更快:这个目标则贯穿于搜索引擎的大多数技术方向,比如索引相关技术、缓存等技术的提出都市直接为了达到此目的。
更准:最为关键目标。无论是排序技术,还是链接分析,或是用户研究等技术,最终都是为了使搜索结果更加准确,以增强用户体验。涉及到3个核心问题:1)用户真正的需求是什么;2)哪些信息是和用户需求真正相关的,搜索引擎本质上是一个匹配过程,即从海量数据里面找到能够匹配用户需求的内容。从关键词匹配到让机器真正理解信息所代表的含义是解决这个问题必须迈过的门槛;3)哪些信息是用户可以信赖的。
1.3搜索引擎的技术架构

2网络爬虫
通用搜索引擎的处理对象是互联网网页,目前网页数量以百亿计,所以搜索引擎首先面临的问题就是:如何能够设计出高效的下载系统,以将如此海量的网页数据传送到本地,在本地形成互联网网页的镜像备份。
网络爬虫即起此作用。从整体框架上已相对成熟,但随着互联网的不断发展,也面临着一些有挑战性的新问题。
2.1通用爬虫框架
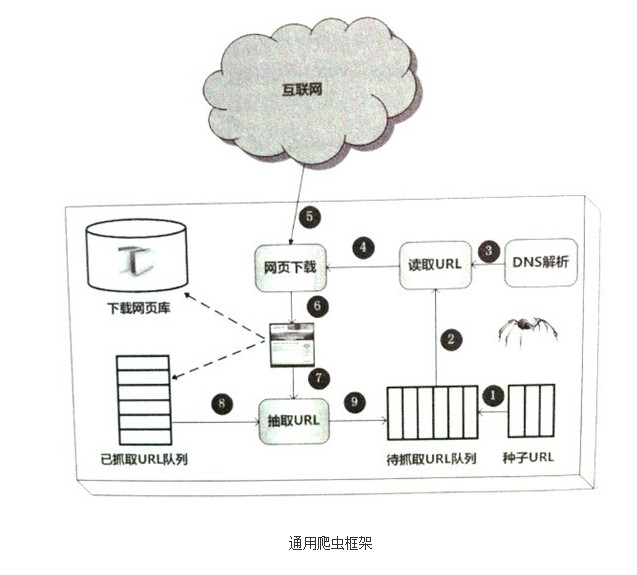
首先从互联网页面中精心选择一部分网页,以这些网页的链接地址作为种子URL,将这些种子URL放入待抓取URL队列中,爬虫从待抓取URL队列一次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。然后将其和网页相对路径名称交给网页下载器,网页下载器负责页面内容的下载。对于下载到本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的URL放入已抓取URL队列中,这个队列记载了爬虫系统已经下载过的网页URL,以避免网页的重复抓取。
2.2爬虫系统类型
批量型爬虫(Batch Crawler):有比较明确的抓取范围和目标,当爬虫达到这个设定的目标后,即停止抓取过程。至于具体目标可能各异,也许是设定抓取一定数量的网页,也许是设定抓取消耗的时间等。
增量型爬虫(Incremental Crawler):会保持持续不断的抓取,对于抓取的网页,要定期更新。通用的商业搜索引擎爬虫基本都属此类。
垂直型爬虫(Focused Crawler):关注特定主题内容或者属于特定行业的网页。一个最大的特点和难点就是:如何识别网页内容是否属于制定行业或者主题。
2.3爬虫质量的评价标准
抓取网页覆盖率:指的是爬虫抓取的网页数量占互联网所有网页数量的比例。暗网抓取系统。
抓取网页时新性:对于爬虫抓到本地的网页来说,很多网页可能发生变化,所以网页库中过期的素具越少,则网页的时新性越好。大型商业搜索引擎为了满足以上3个质量标准,Google至少包含两套不同目的的爬虫系统,一套称为Fresh Bot,主要考虑网页的时新性,对于内容更新频繁的网页,目前可以达到以秒计的更新周期;另外一套被称之为Deep Crawl Bot,主要针对其他跟新不是那么频繁的网页抓取,以天为更新周期。
抓取网页重要性
3网页去重
4网页反作弊
5索引、索引压缩
6云存储与云计算
7链接分析
8检索模型与搜索排序
9用户查询意图分析
10缓冲机制
11搜索引擎发展趋势