1.皮尔森相关系数(Pearson)评估两个连续变量之间的线性关系
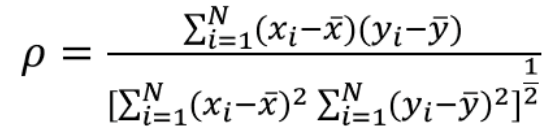
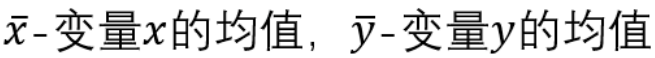
-1 ≤ p ≤ 1
p接近0代表无相关性
p接近1或-1代表强相关性
代码:
#相关系数显著性检验 import numpy as np import scipy.stats as stats import scipy x=np.array([10.35,6.24,3.18,8.46,3.21,7.65,4.32,8.66,9.12,10.31]) y=np.array([5.1,3.15,1.67,4.33,1.76,4.11,2.11,4.88,4.99,5.12]) correlation,pvalue = stats.stats.pearsonr(x,y) print("correlation:",correlation) #correlation: 0.9891763198690562 print("pvalue:",pvalue) #5.926875946481136e-08 x1=x-x.mean() y1=y-y.mean() y2=x1*y1 fenzi=y2.sum() #35.0235 x_sum=(x1*x1).sum() #68.4742 y_sum1=(y1*y1).sum() #18.30816 fenmu=np.power(x_sum*y_sum1,1/2) corr_pearson=fenzi/fenmu #根据上面可以编写函数 def corr_pearson(x,y): x=np.array(x) y=np.array(y) x1=x-x.mean() y1=y-y.mean() y2=x1*y1 fenzi=y2.sum() #35.0235 x_sum=(x1*x1).sum() #68.4742 y_sum1=(y1*y1).sum() #18.30816 fenmu=np.power(x_sum*y_sum1,1/2) return(fenzi/fenmu) x=[10.35,6.24,3.18,8.46,3.21,7.65,4.32,8.66,9.12,10.31] y=[5.1,3.15,1.67,4.33,1.76,4.11,2.11,4.88,4.99,5.12] corr_pearson(x,y)
添加一个scipy,numpy,pandas 计算皮尔斯系数的方法:
import scipy.stats as stats import numpy as np import pandas as pd a = [1.2, 1.5, 1.9] b = [2.2, 2.5, 3.1] print(stats.pearsonr(a, b)) ''' 使用scipy库来进行计算,返回两个值,第一个是相关系数,第二个是在不相关假设情况下的p值。 (0.9941916256019201, 0.0686487855020298) ''' print(np.corrcoef([a, b])) ''' 使用numpy库来计算相关系数,返回一个数组的形式,为第i行第j行的相关系数 [[1. 0.99419163] [0.99419163 1. ]] ''' df = pd.DataFrame() df['a'] = a df['b'] = b print(df.corr()) ''' 使用pandas库来进行计算,计算第i列和第j列(每一列都是一个Series)的相关系数。返回的结果为一个DataFrame。注:pandas是计算列的相关系数,numpy是计算行的相关系数。假如有一个df,那么如果用numpy来进行计算?使用的方法是 np.corrcoef(df.values.T),要进行转置一下。 a b a 1.000000 0.994192 b 0.994192 1.000000 '''
2.斯皮尔曼相关系数评估两个连续变量之间的单调关系。在单调关系中,变量趋于一起变化,但不一定以恒定速率变化
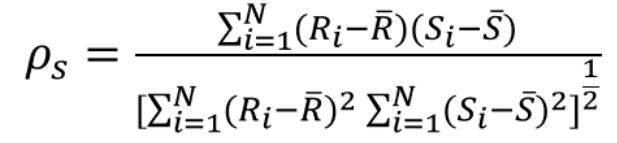

N是观测值的总数量
斯皮尔曼另一种表达公式:
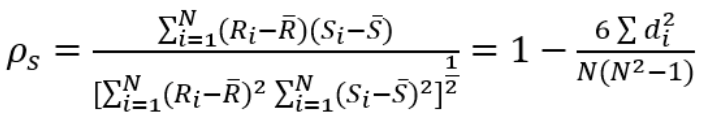
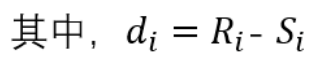
表示二列成对变量的等级差数
#spearman相关系数,方式一 x=[10.35,6.24,3.18,8.46,3.21,7.65,4.32,8.66,9.12,10.31] y=[5.1,3.15,1.67,4.33,1.76,4.11,2.11,4.88,4.99,5.12] correlation,pvalue = stats.spearmanr(x,y) print("correlation:",correlation) print("pvalue:",pvalue) #spearman相关系数,方式二 x = scipy.stats.stats.rankdata(x) y = scipy.stats.stats.rankdata(y) print(x,y) correlation,pvalue = scipy.stats.spearmanr(x,y) print("correlation:",correlation) print("pvalue:",pvalue)
详细过程:
也就是说,原来的数据(不经过排序),原来这两个变量就是有序的,则斯皮尔曼系数等于1或者-1
d其实就是两个变量对应的值的index的差
import pandas as pd import numpy as np #原始数据 X1=pd.Series([1, 2, 3, 4, 5, 6]) Y1=pd.Series([0.3, 0.9, 2.7, 2, 3.5, 5]) #处理数据删除Nan x1=X1.dropna() y1=Y1.dropna() n=x1.count() x1.index=np.arange(n) y1.index=np.arange(n) #分部计算 d=(x1.sort_values().index-y1.sort_values().index)**2 dd=d.to_series().sum() p=1-n*dd/(n*(n**2-1)) #s.corr()函数计算 r=x1.corr(y1,method='spearman') print(r,p) #0.942857142857143 0.9428571428571428
区别:
(1)Pearson和Spearman相关系数的范围可以从-1到+1。当Pearson相关系数为+1时,意味着,当一个变量增加时,另一个变量增加一致量。这形成了一种递增的直线。在这种情况下,Spearman相关系数也是+1。
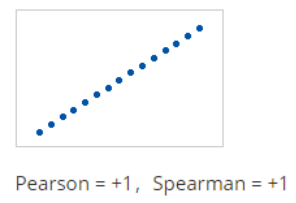
(2)如果关系是一个变量在另一个变量增加时增加,但数量不一致,则Pearson相关系数为正但小于+1。在这种情况下,斯皮尔曼系数仍然等于+1。
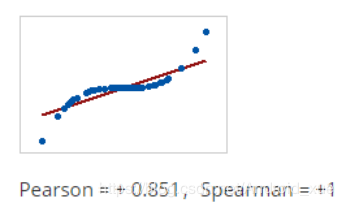
(3)当关系是随机的或不存在时,则两个相关系数几乎为零。
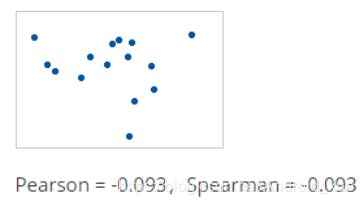
(4)如果关系递减的直线,那么两个相关系数都是-1。

(5)如果关系是一个变量在另一个变量增加时减少,但数量不一致,则Pearson相关系数为负但大于-1。在这种情况下,斯皮尔曼系数仍然等于-1
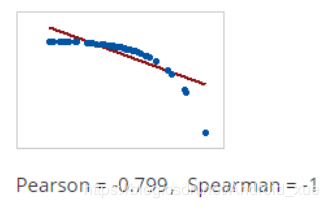
相关值-1或1意味着精确的线性关系,如圆的半径和圆周之间的关系。然而,相关值的实际价值在于量化不完美的关系。发现两个变量是相关的经常通知回归分析,该分析试图更多地描述这种类型的关系。
其他非线性关系
Pearson相关系数仅评估线性关系。Spearman相关系数仅评估单调关系。因此,即使相关系数为0,也可以存在有意义的关系。检查散点图以确定关系的形式。
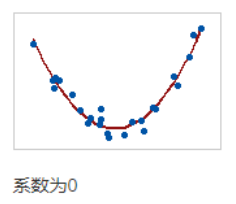
该图显示了非常强的关系。Pearson系数和Spearman系数均约为0。
结论
皮尔森评估的是两个变量的线性关系,而斯皮尔曼评估的两变量的单调关系。
因此,斯皮尔曼相关系数对于数据错误和极端值的反应不敏感。