一、分类指标
1.accuracy_score(y_true,y_pre):准确率
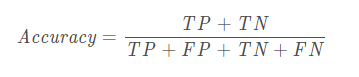
总的来说就是分类正确的样本占总样本个数的比例,数据越大越好,
但是有一个明显的缺陷,即是当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素
参数如下:
y_true : 一维数组,或标签指示符 / 稀疏矩阵,实际(正确的)标签.
y_pred : 一维数组,或标签指示符 / 稀疏矩阵,分类器返回的预测标签.
normalize : 布尔值, 可选的(默认为True). 如果为False,返回分类正确的样本数量,否则,返回正 确分类的得分.
sample_weight : 形状为[样本数量]的数组,可选. 样本权重.
返回值:
score : 浮点型
如果normalize为True,返回正确分类的得分(浮点型),否则返回分类正确的样本数量(整型).
当normalize为True时,最好的表现是score为1,当normalize为False时,最好的表现是score未样本数量.
#示例 import numpy as np from sklearn.metrics import accuracy_score y_pred = [0, 2, 1, 3] y_true = [0, 1, 2, 3] print(accuracy_score(y_true, y_pred)) # 0.5 print(accuracy_score(y_true, y_pred, normalize=False)) # 2 # 在具有二元标签指示符的多标签分类案例中 print(accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2)))) # 0.5
2.auc(x, y, reorder=False) : ROC曲线下的面积;较大的AUC代表了较好的performance
3.average_precision_score(y_true, y_score, average='macro', sample_weight=None):
根据预测得分计算平均精度(AP)

其中Pn和Rn是第n个阈值处的precision和recall。对于随机预测,AP是正样本的比例,
该值在 0 和 1 之间,并且越高越好
注意:此实现仅限于二进制分类任务或多标签分类任务
#官方示例 import numpy as np from sklearn.metrics import average_precision_score y_true = np.array([0, 0, 1, 1]) y_scores = np.array([0.1, 0.4, 0.35, 0.8]) average_precision_score(y_true, y_scores) #0.83...
4.brier_score_loss(y_true, y_prob, sample_weight=None, pos_label=None):
Brier 分数损失
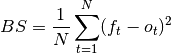
Brier 分数是一个特有的分数函数,用于衡量概率预测的准确性。它适用于预测必须将概率分配给一组相互排斥的离散结果的任务
该函数返回的是 实际结果与可能结果 的预测概率之间均方差的得分。 实际结果必须为1或0(真或假),而实际结果的预测概率可以是0到1之间的值。
Brier 分数损失也在0到1之间,分数越低(均方差越小),预测越准确。它可以被认为是对一组概率预测的 “校准” 的度量
其中:  是预测的总数,
是预测的总数,  是实际结果
是实际结果  的预测概率
的预测概率
#官方示例 import numpy as np from sklearn.metrics import brier_score_loss y_true = np.array([0, 1, 1, 0]) y_true_categorical = np.array(["spam", "ham", "ham", "spam"]) y_prob = np.array([0.1, 0.9, 0.8, 0.4]) y_pred = np.array([0, 1, 1, 0]) brier_score_loss(y_true, y_prob) #0.055 brier_score_loss(y_true, 1-y_prob, pos_label=0) #0.055 brier_score_loss(y_true_categorical, y_prob, pos_label="ham") #0.055 brier_score_loss(y_true, y_prob > 0.5) #0.0
5.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None):
通过计算混淆矩阵来评估分类的准确性 返回混淆矩阵
#官方代码 from sklearn.metrics import confusion_matrix y_true = [2, 0, 2, 2, 0, 1] y_pred = [0, 0, 2, 2, 0, 2] confusion_matrix(y_true, y_pred) #array([[2, 0, 0],[0, 0, 1],[1, 0, 2]]) y_true = ["cat", "ant", "cat", "cat", "ant", "bird"] y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"] confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"]) #array([[2, 0, 0], [0, 0, 1],[1, 0, 2]]) tn, fp, fn, tp = confusion_matrix([0, 1, 0, 1], [1, 1, 1, 0]).ravel() (tn, fp, fn, tp) #(0, 2, 1, 1)
返回的是TN(真的当成假的),FP(假的当成真的) ,FN(假的还是假的) TP (真的还是真的)
总的来说,T,F分别是真实值中的真假,P,N 分别是预测中的真假
关于类别顺序可由 labels参数控制调整,例如 labels=[2,1,0],则类别将以这个顺序自上向下排列。
默认数字类别是从小到大排列,英文类别是按首字母顺序排列
第一个例子这样理解:
| 0(真实) | 1(真实) | 2(真实) | |
| 0(预测) | 2 | 0 | 1 |
| 1(预测) | 0 | 0 | 0 |
| 2(预测) | 0 | 1 | 2 |
所以就有[[2,0,0],[0,0,1],[1,0,2]]
6.f1_score(y_true, y_pred, labels=None, pos_label=1, average='binary', sample_weight=None): F1值
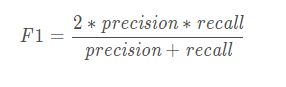
F1 score可以解释为精确率和召回率的加权平均值. F1 score的最好值为1,最差值为0. 精确率和召回率对F1 score的相对贡献是相等的
#示例 from sklearn.metrics import f1_score y_true = [0, 1, 2, 0, 1, 2] y_pred = [0, 2, 1, 0, 0, 1] print(f1_score(y_true, y_pred, average='macro')) # 0.26666666666666666 print(f1_score(y_true, y_pred, average='micro')) # 0.3333333333333333 print(f1_score(y_true, y_pred, average='weighted')) # 0.26666666666666666 print(f1_score(y_true, y_pred, average=None)) # [0.8 0. 0. ]
average : string,[None, ‘binary’(default), ‘micro’, ‘macro’, ‘samples’, ‘weighted’]
这里需要注意,如果是二分类问题则选择参数‘binary’;如果考虑类别的不平衡性,需要计算类别的加权平均,则使用‘weighted’;如果不考虑类别的不平衡性,计算宏平均,则使用‘macro’
对于类0:TP=1,FP=0,FN=1,precision=1,recall=1/2,F1-score=2/3,Weights=1/3
对于类1:TP=1,FP=2,FN=2,precision=1/3,recall=1/3,F1-score=1/3,Weights=1/2
对于类2:TP=0,FP=2,FN=1,precision=0,recall=0,F1-score=0,Weights=1/6
宏平均分数为:0.333;加权平均分数为:0.389
7.log_loss(y_true, y_pred, eps=1e-15, normalize=True, sample_weight=None, labels=None):
又被称为 logistic regression loss(logistic 回归损失)或者 cross-entropy loss(交叉熵损失) 定义在 probability estimates (概率估计)
#示例 from sklearn.metrics import log_loss y_true = [0, 0, 1, 1] y_pred = [[.9, .1], [.8, .2], [.3, .7], [.01, .99]] log_loss(y_true, y_pred) #0.1738
8.precision_score(y_true, y_pred, labels=None, pos_label=1, average='binary',) :查准率或者精确度
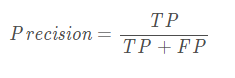
参数
y_true : 一维数组,或标签指示符 / 稀疏矩阵,实际(正确的)标签.
y_pred : 一维数组,或标签指示符 / 稀疏矩阵,分类器返回的预测标签.
labels : 列表,默认情况下,y_true和y_pred中的所有标签按照排序后的顺序使用.
pos_label : 字符串或整型,默认为1. 如果average = binary并且数据是二进制时需要被报告的类. 若果数据是多类的或者多标签的,这将被忽略;设置labels=[pos_label]和average != binary就只会报告设置的特定标签的分数.
average : 字符串,可选值为[None, ‘binary’ (默认), ‘micro’, ‘macro’, ‘samples’, ‘weighted’]. 多类或 者多标签目标需要这个参数. 如果为None,每个类别的分数将会返回. 否则,它决定了数据的平均值类型.
‘binary’: 仅报告由pos_label指定的类的结果. 这仅适用于目标(y_{true, pred})是二进制的情况.
‘micro’: 通过计算总的真正性、假负性和假正性来全局计算指标.
‘macro’: 为每个标签计算指标,找到它们未加权的均值. 它不考虑标签数量不平衡的情况.
‘weighted’: 为每个标签计算指标,并通过各类占比找到它们的加权均值(每个标签的正例数).它解决了’macro’的标签不平衡问题;它可以产生不在精确率和召回率之间的F-score.
‘samples’: 为每个实例计算指标,找到它们的均值(只在多标签分类的时候有意义,并且和函数accuracy_score不同).
sample_weight : 形状为[样本数量]的数组,可选参数. 样本权重.
返回值
precision : 浮点数(如果average不是None) 或浮点数数组, shape =[唯一标签的数量]
二分类中正类的精确率或者在多分类任务中每个类的精确率的加权平均.
#官方代码如下 from sklearn.metrics import precision_score y_true = [0, 1, 2, 0, 1, 2] y_pred = [0, 2, 1, 0, 0, 1] print(precision_score(y_true, y_pred, average='macro')) # 0.2222222222222222 print(precision_score(y_true, y_pred, average='micro')) # 0.3333333333333333 print(precision_score(y_true, y_pred, average='weighted')) # 0.2222222222222222 print(precision_score(y_true, y_pred, average=None)) # [0.66666667 0. 0. ]
9.recall_score(y_true, y_pred, labels=None, pos_label=1, average='binary', sample_weight=None):召回率
recall(召回率)=TP/(TP+FN)
召回率指实际为正的样本中被预测为正的样本所占实际为正的样本的比例
召回率最好的值是1,最差的值是0
#示例 from sklearn.metrics import recall_score y_true = [0, 1, 2, 0, 1, 2] y_pred = [0, 2, 1, 0, 0, 1] print(recall_score(y_true, y_pred, average='macro')) # 0.3333333333333333 print(recall_score(y_true, y_pred, average='micro')) # 0.3333333333333333 print(recall_score(y_true, y_pred, average='weighted')) # 0.3333333333333333 print(recall_score(y_true, y_pred, average=None)) # [1. 0. 0.]
10.roc_auc_score(y_true, y_score, average='macro', sample_weight=None):
计算ROC曲线下的面积就是AUC的值,值越大越好
#官方示例 import numpy as np from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1]) y_scores = np.array([0.1, 0.4, 0.35, 0.8]) roc_auc_score(y_true, y_scores) #0.75
11.roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True);
计算ROC曲线的横纵坐标值,TPR,FPR:
TPR = TP/(TP+FN) = recall(真正例率,敏感度) FPR = FP/(FP+TN)(假正例率,1-特异性)
#官方代码 import numpy as np from sklearn import metrics y = np.array([1, 1, 2, 2]) scores = np.array([0.1, 0.4, 0.35, 0.8]) fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2) fpr #array([0. , 0. , 0.5, 0.5, 1. ]) tpr #array([0. , 0.5, 0.5, 1. , 1. ]) thresholds #array([1.8 , 0.8 , 0.4 , 0.35, 0.1 ])
补充一下混淆矩阵如下:

二、回归指标
1.explained_variance_score(y_true, y_pred, sample_weight=None, multioutput='uniform_average'):回归方差(反应自变量与因变量之间的相关程度)
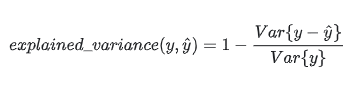
explained_variance_score:解释方差分,这个指标用来衡量我们模型对数据集波动的解释程度,如果取值为1时,模型就完美,越小效果就越差
# 例子 from sklearn.metrics import explained_variance_score y_true = [3, -0.5, 2, 7] y_pred = [2.5, 0.0, 2, 8] explained_variance_score(y_true, y_pred) #0.957 y_true = [[0.5, 1], [-1, 1], [7, -6]] y_pred = [[0, 2], [-1, 2], [8, -5]] explained_variance_score(y_true, y_pred, multioutput='uniform_average') #0.983
2.mean_absolute_error(y_true, y_pred, sample_weight=None, multioutput='uniform_average'):平均绝对误差
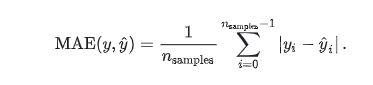
给定数据点的平均绝对误差,一般来说取值越小,模型的拟合效果就越好
#官方例子 from sklearn.metrics import mean_absolute_error y_true = [3, -0.5, 2, 7] y_pred = [2.5, 0.0, 2, 8] mean_absolute_error(y_true, y_pred) #0.5 y_true = [[0.5, 1], [-1, 1], [7, -6]] y_pred = [[0, 2], [-1, 2], [8, -5]] mean_absolute_error(y_true, y_pred) #0.75 mean_absolute_error(y_true, y_pred, multioutput='raw_values') #array([0.5, 1. ]) mean_absolute_error(y_true, y_pred, multioutput=[0.3, 0.7]) #0.85
参数解释:multioutput可选2种方式:
row_values:返回完整的错误集;
uniform_average:输出的误差均以相同的权重
3.mean_squared_error(y_true, y_pred, sample_weight=None, multioutput='uniform_average'):均方差
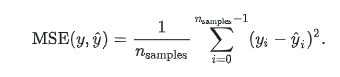
预测值和真实值的差的平方和的均值,数据越小越好
#官方示例 from sklearn.metrics import mean_squared_error y_true = [3, -0.5, 2, 7] y_pred = [2.5, 0.0, 2, 8] mean_squared_error(y_true, y_pred) #0.375 mean_squared_error(y_true, y_pred, squared=False) #0.612 y_true = [[0.5, 1],[-1, 1],[7, -6]] y_pred = [[0, 2],[-1, 2],[8, -5]] mean_squared_error(y_true, y_pred) #0.708 mean_squared_error(y_true, y_pred, multioutput='raw_values') #array([0.41666667, 1. ]) mean_squared_error(y_true, y_pred, multioutput=[0.3, 0.7]) #0.825
4.median_absolute_error(y_true, y_pred) 中位数绝对误差
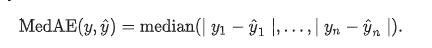
得到的值越小越好
from sklearn.metrics import median_absolute_error y_true = [3, -0.5, 2, 7] y_pred = [2.5, 0.0, 2, 8] median_absolute_error(y_true, y_pred) #0.5
y_true = [[0.5, 1], [-1, 1], [7, -6]] y_pred = [[0, 2], [-1, 2], [8, -5]] median_absolute_error(y_true, y_pred) #0.75
median_absolute_error(y_true, y_pred, multioutput='raw_values') #array([0.5, 1. ]) median_absolute_error(y_true, y_pred, multioutput=[0.3, 0.7]) #0.85
5.r2_score(y_true, y_pred, sample_weight=None, multioutput='uniform_average') :决定系数,R平方
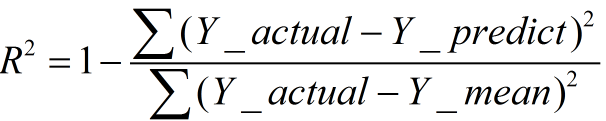
R方可以理解为因变量y中的变异性能能够被估计的多元回归方程解释的比例,它衡量各个自变量对因变量变动的解释程度,其取值在0与1之间,其值越接近1,则变量的解释程度就越高,其值越接近0,其解释程度就越弱。
一般来说,增加自变量的个数,回归平方和会增加,残差平方和会减少,所以R方会增大;反之,减少自变量的个数,回归平方和减少,残差平方和增加。
经验值:>0.4, 拟合效果好
缺点:数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差
#官方示例 from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7] y_pred = [2.5, 0.0, 2, 8] r2_score(y_true, y_pred) #0.948... y_true = [[0.5, 1], [-1, 1], [7, -6]] y_pred = [[0, 2], [-1, 2], [8, -5]] r2_score(y_true, y_pred,multioutput='variance_weighted') #0.938... y_true = [1, 2, 3] y_pred = [1, 2, 3] r2_score(y_true, y_pred) #1.0 y_true = [1, 2, 3] y_pred = [2, 2, 2] r2_score(y_true, y_pred) #0.0 y_true = [1, 2, 3] y_pred = [3, 2, 1] r2_score(y_true, y_pred) #-3.0
6.mean_squared_log_error(y_true, y_pred)
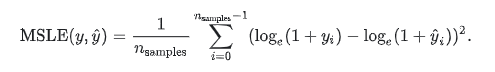
当目标实现指数增长时,例如人口数量、一种商品在几年时间内的平均销量等,这个指标最适合使用。请注意,这个指标惩罚的是一个被低估的估计大于被高估的估计