先导入基本的模块
#导入模块 import numpy as np import pandas as pd from scipy import stats import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline plt.rc("font",family="SimHei",size="12") #解决中文无法显示的问题
导入数据
#导入CSV数据 train=pd.read_csv('F://python//titanic_data.csv')
字段含义:
PassengerId:乘客编号
Survived:乘客是否存活
Pclass:乘客所在的船舱等级
Name:乘客姓名
Sex:乘客性别
Age:乘客年龄
SibSp:乘客的兄弟姐妹和配偶数量
Parch:乘客的父母与子女数量
Ticket:票的编号
Fare:票价
Cabin:座位号
Embarked:乘客登船码头
查查数据分布
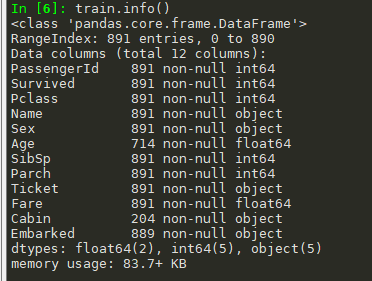
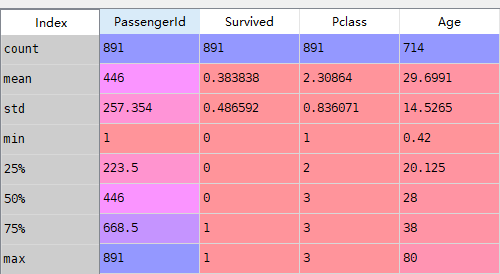
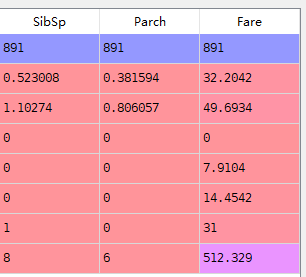
#使用info,describe train.info() train.describe()
查看缺失值
#null train.isnull().sum()

区别类别变量和连续变量
#连续变量和类别变量分开 num_features=train.select_dtypes(include=[np.number]) categ_features=train.select_dtypes(include=[np.object]) num_features=num_features.columns categ_features=categ_features.columns
类别变量分析(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'])主要分析性别和乘客登船码头
#类别变量的每个类别频数可视化 def count_plot(x, **kwargs): sns.countplot(x=x) x=plt.xticks(rotation=90) f = pd.melt(train, value_vars=['Sex','Embarked']) g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5) g = g.map(count_plot, "value")

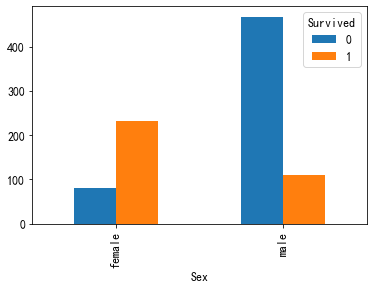
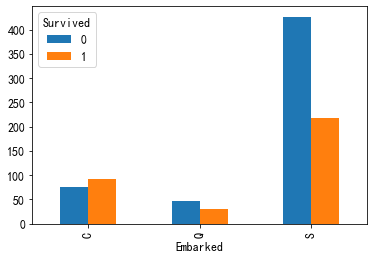
查看这二者和存活的关系如何
#画图 pd.crosstab(train["Sex"],train["Survived"]).plot(kind="bar") pd.crosstab(train['Embarked'],train["Survived"]).plot(kind="bar")
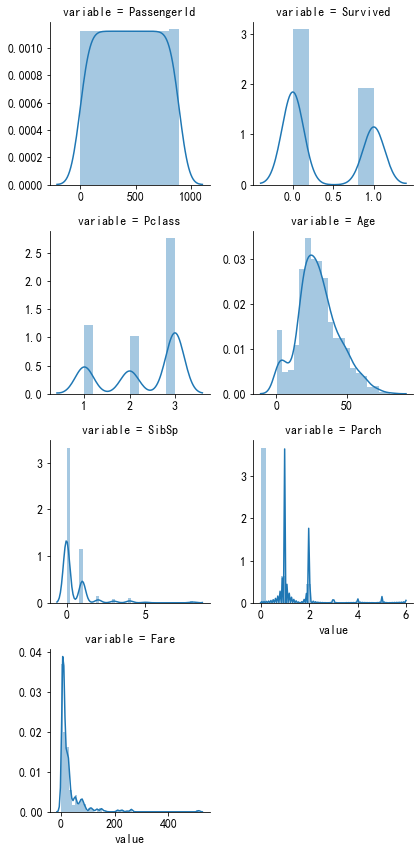
处理连续变量(['PassengerId', 'Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare'])
#每个数字特征得分布可视化 f = pd.melt(train, value_vars=num_features) g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False) g = g.map(sns.distplot, "value")
存活画图
#使用pandas的画图 train["Survived"].value_counts().plot(kind="bar")

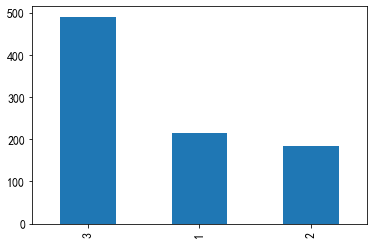
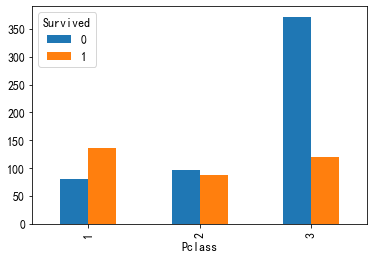
乘客所在的船舱等级
#乘客所在的船舱等级画图 train['Pclass'].value_counts().plot(kind="bar") #和存活做二维表画图 pd.crosstab(train['Pclass'],train["Survived"]).plot(kind="bar")
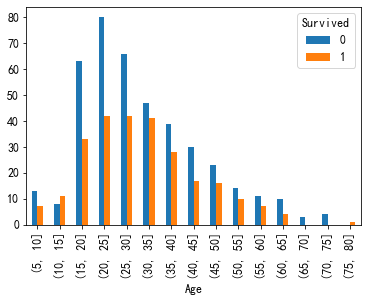
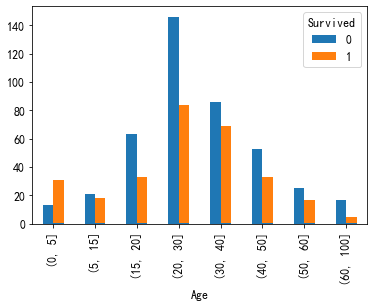
年龄处理
#画条形图 train["Age"].hist() #按照五岁一个区间去分 cut=[i*5 for i in range(1,20)] train.age=pd.cut(train.Age,cut) a=pd.crosstab(train.age,train.Survived) a.plot(kind="bar") a['rate']=a[1]/(a[1]+a[0]) a['rate'].plot(kind="bar")
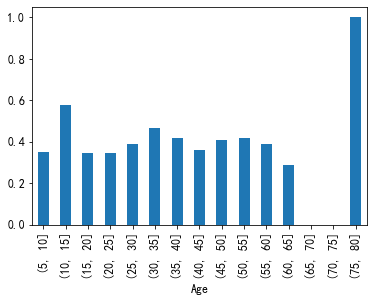
效果并不明显,再分一次
#重新分区间 cut=[0,5,15,20,30,40,50,60,100] train.age=pd.cut(train.Age,cut) a=pd.crosstab(train.age,train.Survived) a.plot(kind="bar") a['rate']=a[1]/(a[1]+a[0]) a['rate'].plot(kind="bar")

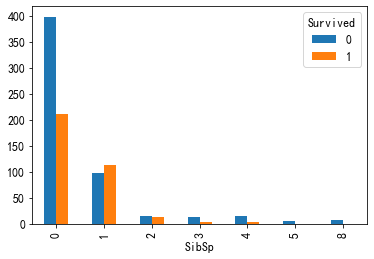
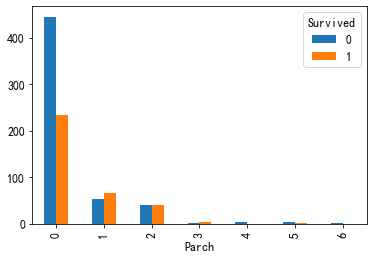
SibSp:乘客的兄弟姐妹和配偶数量
Parch:乘客的父母与子女数量
pd.crosstab(train["SibSp"],train["Survived"]).plot(kind="bar") pd.crosstab(train["Parch"],train["Survived"]).plot(kind="bar")
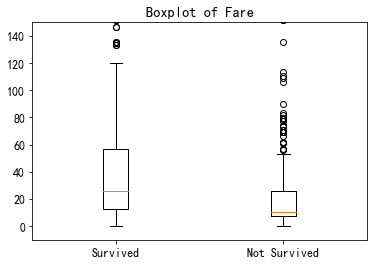
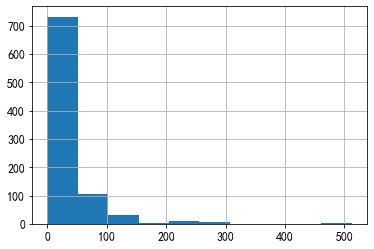
票价
#使用箱型图查看二者分布如何 fig,ay = plt.subplots() Fare1 = train.Fare[train.Survived == 1] Fare0 = train.Fare[train.Survived == 0] plt.boxplot((Fare1,Fare0),labels=('Survived','Not Survived')) ay.set_ylim([-10,150]) ay.set_title("Boxplot of Fare")
train["Fare"].hist()
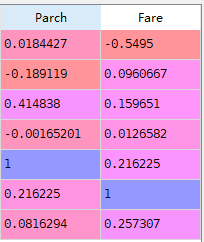
变量之间相关性分析
#corr corr=train.corr() corr["Survived"].sort_values()


特征构造
#缺失值处理 train['Age'].mean() #29.69911764705882 train['Age'].fillna(30,inplace=True) #删除 train['Cabin'].value_counts() train=train.drop(['Cabin'],axis=1) #众数填充 train['Embarked'].value_counts() train['Embarked'].fillna('S',inplace=True) #年龄分箱 train.age=pd.cut(train.Age,[0,5,15,20,35,50,60,100]) pd.crosstab(train.age,train.Survived).plot.bar() train.Parch[(train.Parch>0) & (train.Parch<=2)]=1 train.Parch[train.Parch>2]=2 train.SibSp[(train.SibSp>0) & (train.SibSp<=2)]=1 train.SibSp[train.SibSp>2]=2 dummy_Pclass = pd.get_dummies(train.Pclass, prefix='Pclass') dummy_Sex = pd.get_dummies(train.Sex, prefix='Sex') dummy_Embarked = pd.get_dummies(train.Embarked, prefix='Embarked') dummy_Parch = pd.get_dummies(train.Parch, prefix='Parch') dummy_SibSp = pd.get_dummies(train.SibSp, prefix='SibSp') dummy_Age = pd.get_dummies(train.age, prefix='Age') train_1=dummy_Pclass.join(dummy_Sex).join(dummy_Embarked).join(dummy_Parch).join(dummy_SibSp).join(dummy_Age) train_1['Fare']=train['Fare']
模型构造
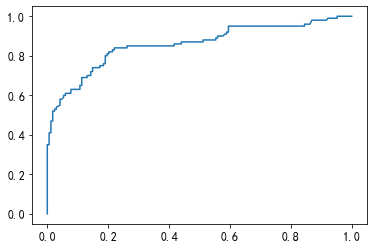
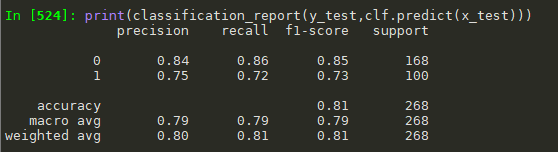
from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix, roc_curve,roc_auc_score,classification_report from sklearn.model_selection import train_test_split train_x=train_1 train_y=train['Survived'] x_train,x_test,y_train,y_test=train_test_split(train_x,train_y,test_size=0.3,random_state=0) #逻辑回归 clf = LogisticRegression() clf.fit(x_train,y_train) #用测试集进行检验 clf.predict(x_test) #混淆矩阵 confusion_matrix(y_test,clf.predict(x_test)) #array([[144, 24],[ 28, 72]], dtype=int64) #roc roc_auc_score(y_test,clf.predict_proba(x_test)[:,1]) #0.8578869047619048 #画图 fpr,tpr,thresholds = roc_curve(y_test,clf.predict_proba(x_test)[:,1]) plt.plot(fpr,tpr) #分类报告 print(classification_report(y_test,clf.predict(x_test)))