环境准备
flink-1.10.0-bin-scala_2.11.tgz(Flink 1.10)
Ubantu 18.04
scala 2.11.x
Jdk1.8+
IDEA/Eclipse开发工具
Flink 是一个分布式的流处理框架,它能够对有界和无界的数据流进行高效的处理。Flink 的核心是流处理,当然它也能支持批处理,Flink 将批处理看成是流处理的一种特殊情况,即数据流是有明确界限的。
这和 Spark Streaming 的思想是完全相反的,Spark Streaming 的核心是批处理,它将流处理看成是批处理的一种特殊情况, 即把数据流进行极小粒度的拆分,拆分为多个微批处理。
零、Flink架构
1、Flink层级
Flink 采用分层的架构设计,从而保证各层在功能和职责上的清晰。如下图所示,由上而下分别是 API & Libraries 层、Runtime 核心层以及物理部署层
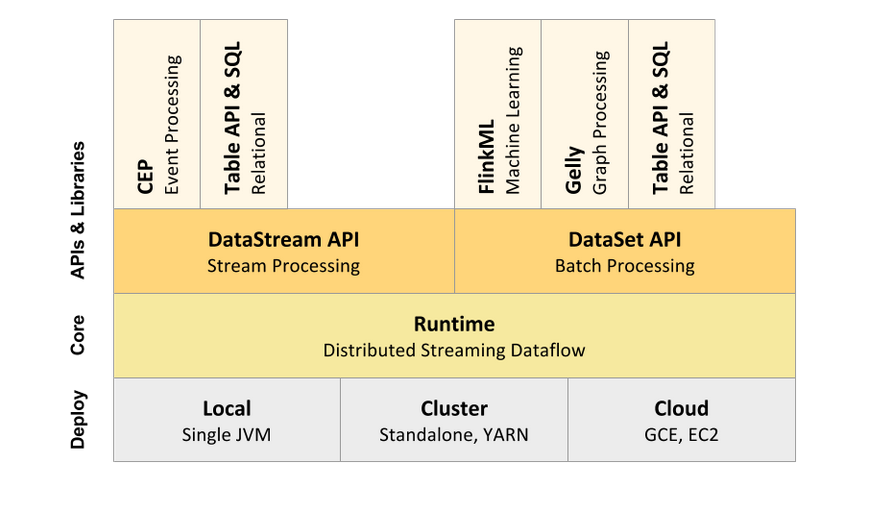
2、Api
API & Libraries 这一层,Flink 又进行了更为具体的划分。
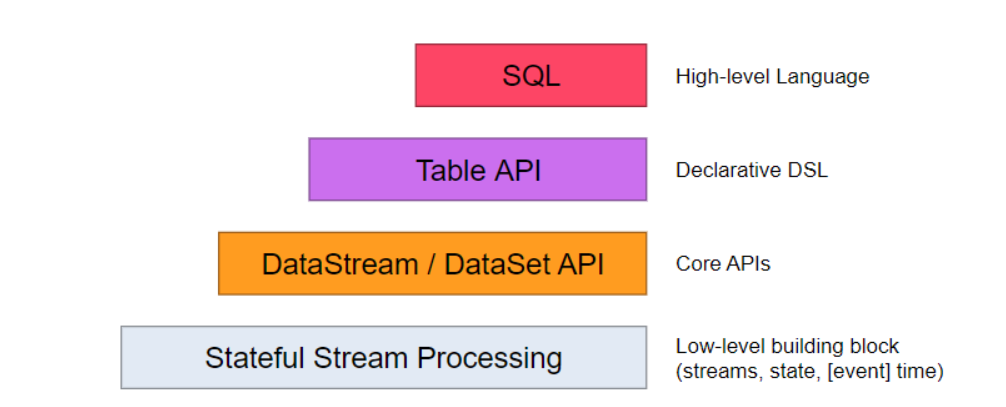
2.1 SQL & Table API
SQL & Table API 同时适用于批处理和流处理,这意味着你可以对有界数据流和无界数据流以相同的语义进行查询,并产生相同的结果。除了基本查询外, 它还支持自定义的标量函数,聚合函数以及表值函数,可以满足多样化的查询需求。
2.2 DataStream & DataSet API
DataStream & DataSet API 是 Flink 数据处理的核心 API,支持使用 Java 语言或 Scala 语言进行调用,提供了数据读取,数据转换和数据输出等一系列常用操作的封装。
2.3 Stateful Stream Processing
Stateful Stream Processing 是最低级别的抽象,它通过 Process Function 函数内嵌到 DataStream API 中。 Process Function 是 Flink 提供的最底层 API,具有最大的灵活性,允许开发者对于时间和状态进行细粒度的控制。
1、Flink开发环境
1、单机安装到Linux下
在Linux下解压后,进入目录:
bin conf examples lib LICENSE licenses log NOTICE opt plugins README.txt
bin目录下是相关命令,有部署、集群、执行等相关命令。
bash-java-utils.jar historyserver.sh pyflink-gateway-server.sh start-zookeeper-quorum.sh
config.sh jobmanager.sh pyflink-shell.sh stop-cluster.sh
find-flink-home.sh kubernetes-entry.sh sql-client.sh stop-zookeeper-quorum.sh
flink kubernetes-session.sh standalone-job.sh taskmanager.sh
flink.bat mesos-appmaster-job.sh start-cluster.bat yarn-session.sh
flink-console.sh mesos-appmaster.sh start-cluster.sh zookeeper.sh
flink-daemon.sh mesos-taskmanager.sh start-scala-shell.sh
conf目录下是配置文件。
flink-conf.yaml log4j.properties logback.xml slaves
log4j-cli.properties log4j-yarn-session.properties logback-yarn.xml sql-client-defaults.yaml
log4j-console.properties logback-console.xml masters zoo.cfg
将bin目录配置进环境变量。
使用start-scala-shell.sh local命令进入命令行,会跳出一个小松鼠,以及一些提示信息。
默认创建了执行器,打印了一些批流处理的案例。
>start-scala-shell.sh local
Batch - Use the 'benv' and 'btenv' variable
* val dataSet = benv.readTextFile("/path/to/data")
* dataSet.writeAsText("/path/to/output")
* benv.execute("My batch program")
*
* val batchTable = btenv.fromDataSet(dataSet)
* btenv.registerTable("tableName", batchTable)
* val result = btenv.sqlQuery("SELECT * FROM tableName").collect
HINT: You can use print() on a DataSet to print the contents or collect()
a sql query result back to the shell.
Streaming - Use the 'senv' and 'stenv' variable
* val dataStream = senv.fromElements(1, 2, 3, 4)
* dataStream.countWindowAll(2).sum(0).print()
*
* val streamTable = stenv.fromDataStream(dataStream, 'num)
* val resultTable = streamTable.select('num).where('num % 2 === 1 )
* resultTable.toAppendStream[Row].print()
* senv.execute("My streaming program")
HINT: You can only print a DataStream to the shell in local mode.
通过默认创建的批处理执行器,执行一个WordCount程序。
scala> benv.readTextFile("/usr/local/bigdata/file/wordCount.txt").flatMap(_.split("")).map((_,1)).groupBy(0).sum(1).print()
(hadoop,1)
(hive,2)
(java,1)
(scala,2)
(spark,4)
(sql,1)
2、IDEA下开发Flink
1、创建一个maven项目,加入scala sdk.
2、加入flink依赖(Java、scala)
同时加入了Java、Scala开发Flink的依赖。
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-core -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.10.0</version>
</dependency>
</dependencies>
IDEA开发环境搭建完成,在IDEA中编写批流处理的WordCount.
2、入门案例
使用Flink底层Api开发批、流两种方式的wordCount.
批处理读本机文件数据,流处理从socket中读数据。
1、批处理
Scala语言编写
import org.apache.flink.api.scala.{ DataSet, ExecutionEnvironment}
/**
* @author cgl
* @desc
* @date 2020/12/15 10:45
* @version 1.0
*/
object WordCount {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 从文件中读取数据
val inputPath = "dir/wordcount.txt"
val inputDS: DataSet[String] = env.readTextFile(inputPath)
//导入隐式转换
import org.apache.flink.api.scala._
// 分词之后,对单词进行groupby分组,然后用sum进行聚合
val wordCountDS: DataSet[(String, Int)] = inputDS.flatMap(_.split("\W+"))
.map(_.toUpperCase)
.map((_, 1)).groupBy(0).sum(1)
// 打印输出
wordCountDS.print()
/*
(SCALA,3)
(JAVA,2)
(PYTHON,1)
(HADOOP,3)
(SPARK,1)
(HBASE,1)
(FLINK,1)
*/
}
}
Java语言编写
导入包的时候,记得导入java包。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @author cgl
* @version 1.0
* @desc JavaWordCount
* @date 2020/12/21 14:20
*/
public class WordJava {
public static void main(String[] args) throws Exception {
//获得一个执行环境
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
String inputPath = "dir/wordcount.txt";
//读取文件
DataSource<String> textFile = environment.readTextFile(inputPath);
//操作数据,flatMap函数接收一个函数,在java中就是函数式接口
DataSet<Tuple2<String, Integer>> result = textFile.flatMap(new LineSplitter()).groupBy(0).sum(1);
//打印数据
result.print();
/*
(SCALA,3)
(JAVA,2)
(PYTHON,1)
(HADOOP,3)
(SPARK,1)
(HBASE,1)
(FLINK,1)
*/
}
}
//泛型,输入值和返回值
class LineSplitter implements FlatMapFunction<String, Tuple2<String,Integer>>{
//没有返回值,数据进入Collector中
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = s.split("\W+");
for (String s1 : split) {
collector.collect(new Tuple2<>(s1.toUpperCase(),1));
}
}
}
2、流处理
使用linux工具发送socket数据。
nc -lk 9999
Scala编写
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @author cgl
* @desc
* @date 2020/12/21 16:23
* @version 1.0
*/
object StreamWordCount {
def main(args: Array[String]): Unit = {
//获取环境
val senv = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
//从socket中获取流式数据
val dataStream: DataStream[String] = senv.socketTextStream("node1", 9999, '
')
//处理数据
val value = dataStream.flatMap(_.split("\W+")).map(_.toUpperCase).map((_, 1)).keyBy(0).sum(1)
value.print()
/*
11> (SPARK,1)
4> (SCALA,1)
8> (HADOOP,1)
12> (FLINK,1)
3> (JAVA,1)
11> (PYTHON,1)
4> (SCALA,2)
8> (HADOOP,2)
6> (HBASE,1)
3> (JAVA,2)
8> (HADOOP,3)
4> (SCALA,3)
*/
senv.execute("Streaming WordCount")
}
}
Java编写
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author cgl
* @version 1.0
* @desc
* @date 2020/12/22 10:39
*/
public class StreamWordJava {
public static void main(String[] args) throws Exception {
//获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//从socket中获取流式数据
DataStream<String> stream = env.socketTextStream("node1", 9999);
//处理数据
DataStream<Tuple2<String, Integer>> result = stream.flatMap(new LineSplitter()).keyBy(0).sum(1);
result.print();
/*
11> (SPARK,1)
4> (SCALA,1)
8> (HADOOP,1)
12> (FLINK,1)
3> (JAVA,1)
11> (PYTHON,1)
4> (SCALA,2)
8> (HADOOP,2)
6> (HBASE,1)
3> (JAVA,2)
8> (HADOOP,3)
4> (SCALA,3)
*/
//执行
env.execute("Streaming WordCount");
}
}