XML
1.XML简介
XML是Extend Markup Langue可扩展标签语言,标签由开发着自己定义
作用是:
1.描述带关系的数据(作为软件的配置文件):包含与被包含的关系
2.作为数据的载体,可以存储数据,小型的“数据库”
2.XML语法
xml文件移xml后缀结尾
xml文件需要使用xml解析器去解析。浏览器内置了xml解析器,可以用浏览器打开
2.1.标签
语法:由开始标签 标签内容 结束标签组成,内容可以为空如下:
<student>
rocco
</student>
注意
1.标签格式为
2.xml标签名称区分大小写
3.xml标签一定要配对出现,不能只出现一个
4.xml标签名不能使用空格
5.xml标签名不能以数字开头
6.在一个xml文档中,只能有一个根标签
2.2.属性
语法:
<student name="eric">
rocco
</student>
注意:
1.属性值必须用引号括起来,不能省略,单引号和双引号都可以,但不能混用。
2.一个标签内可以有多个属性,用空格隔开,但是不能出重固的属性名。
2.3.注释
语法:
<!--xml注释-->
2.4.文档声明
声明是标识xml文档的版本,一般是1.0,重要的是编码格式。这个格式是用来指明解析xml文档时使用哪一种格式。注意两种,一种是保存到的时候选择的编码格式,一种是打开时依据的编码格式,这个声明的是后一种
语法
<?xml version="1.0" encoding="UTF-8"?>
version:xml的版本号
encoding:解析xml文件时查询的码表
注意:
1.如果在ecplise工具中开发xml文件,保存xml文件时自动按照文档声明的encoding来保存文件。
2.如果用记事本工具修改xml文件,注意保存xml文件按照文档声明的encoding的码表来保
3.保存的时候编码要跟声明的一样
2.5.转义字符
在xml中内置了一些特殊字符,这些特殊字符不能直接被浏览器原样输出。如果希望把这些特殊字符按照原样输出到浏览器,需要对这些特殊字符进行转义。转义之后的字符就叫转义字符
2.6.CDDATA块
作用:可以让一些需要进行包含特殊字符的内容统一进行原样输出。
语法:
<![CDATA[内容]]>
2.7.处理指令
作用:用来指挥解析引擎如何解析xml文档内容
例如:
<?xml-stylesheet type="text/css" href="1.css"?>告诉xml解析该xml文档引用了那个css文件
处理指令必须以“<?”开头,“?>”结尾
xml声明语句就是一种常见的处理指令
3.XML解析
xml文件除了给开发者看,更多的情况使用程序读取xml文件的内容。读取xml文档的过程就是xml解析
3.1.XML解析方式
按照原理不同,分为两种解析方式
DOM解析
xml解析器在解析xml文档时,把xml文档的各个部分内容封装成对象,通过这些对象操作xml文档,这种做法叫做DOM解析(DOM编程)
Document树:
树只有一个根标签,树上的分之叫做节点(Node)
节点信息:节点名称,节点类型--->封装为Node
标签节点:节点名称--->封装为Element
属性节点:属性名称,属性值--->封装为Attribute
文本节点:文本内容--->封装为Text
当需要获取文档的信息的时候,根据封装的对象来获取。Document对象代表一个完整的xml文档
通过Document对象可以得到其下面的其他节点对象,通过节点对象访问xml文档的内容
DOM解析原理:
xml解析器一次性把整个xml文档加载进内存,然后在内存中构建一个Document的对象数,通过Document对象,得到树上的节点对象,通过节点对象访问(操作)到xml文档的内容
SAX解析
DOM解析是一次性把xml文档加载进内存,在内存中构造DOM树,这种方式对内存要求较高,不适合使用在大容量的xml文件中,因为容易导致内存溢出
SAX解析原理是加载一点,读取一点,处理一点。对内存的要求较低,用来处理大容量文件再合适不过了
3.2.XML解析的工具
常用基于DOM原来的解析工具:
1.JAXP(sun公司官网工具),很少用
2.JDOM工具(非官方)
3.Dom4J工具(非官方),用的较多,是SSH框架默认的工具
3.2.1.Dom4j的使用
使用步骤:
1.导入dom4j的核心包:IDEA为例:File-->Project Structure-->Dependencies-->选+号-->JARs or directories-->找到dom4j-1.6.1.jar-->点OK
2.编写java代码读取xml文件
3.2.2.Dom4j读取xml文件
结合案例,写了一个con.xml文件,源码为:
<?xml version="1.0" encoding="UTF-8"?>
<contactList>
<contact id="001" name="rocco">
<name>张三</name>
<age>20</age>
<phone>13267862354</phone>
<email>739185@qq.com</email>
<qq>678978980</qq>
</contact>
<contact id="002">
<name>lisi</name>
<age>22</age>
<phone>13267862354</phone>
<email>739185@qq.com</email>
<qq>678978980</qq>
</contact>
<abc></abc>
</contactList>
下面读取这个文档中的内容
节点:
Iterator Element.nodeIterator();//获取当前标签下的所有子节点(注意只是子节点,不包括孙节点)
/**
* 获取节点
*/
private static void TestNode() throws DocumentException {
//0.读取xml文档,返回Document对象
SAXReader reader = new SAXReader();
Document doc = reader.read(new File("demo/con.xml"));
//1.nodeIterator:得到当前节点下的所有子节点对象(不包含孙已下的节点)
Iterator its = doc.nodeIterator();
while (its.hasNext()){
Node node = (Node) its.next();
String name1 = node.getName();//取出节点名字
System.out.println(name1);//contactList
}
}
标签:
Element Document.getRootElement();//获取xml文档的根标签
Iterator<Element> Element.elementIterator("标签名");//指定名称的所有子标签
List<Element> Element.elements();//获取所有子标签
/**
* 获取标签
*/
private static void TestElement() throws DocumentException {
//1.读取xml文档,返回Document对象
SAXReader reader = new SAXReader();
Document doc = reader.read(new File("demo/con.xml"));
//2.得到根标签
Element rootelem = doc.getRootElement();
//得到标签的名称
String name = rootelem.getName();
System.out.println(name);//contactList
//3.得到当前标签下指定名称的第一个子标签
Element contactElem = rootelem.element("contact");
String contactName = contactElem.getName();
System.out.println(contactName);//contact
//4.得到当前标签指定名称下指定名称的所有子标签
Iterator<Element> it = rootelem.elementIterator("contact");
while (it.hasNext()) {//迭代器遍历
Element elem = it.next();
System.out.println(elem.getName());//contact contact
}
//5.得到当前标签下的所有子标签
List<Element> list = rootelem.elements();
//遍历List方法:1.传统for循环。2.增强for循环。3.迭代器
for (Element li : list) {
System.out.println(li.getName());//contact contact abc
}
//6.获取更深层次的name标签(方法只能一层层的获取)
Element nameElement = doc.getRootElement().element("contact").element("name");
System.out.println(nameElement.getName());//name
}
属性:
String Element.attributeValue("属性名");//获取指定名称的属性值
Attribute Element.attribute("属性名");//获取指定名称的属性对象
Attribute.getName();//获取属性名称
Attribute.getValue();//获取属性值
List<Attribute> Element.attributes(); //获取所有属性对象
Iterator<Attribute> Element.attibuteIterator(); //获取所有属性对象
/**
* 获取标签里面的属性
* @throws DocumentException
*/
private static void test4() throws DocumentException {
//0.读取xml文档,返回Document对象
SAXReader reader = new SAXReader();
Document doc = reader.read(new File("demo/con.xml"));
//获取属性:要先获取属性所在的标签对象,然后才能获取属性
//1.得到属性所在的标签对象(contact id=001)
Element contactElement = doc.getRootElement().element("contact");
//2.得到属性
//2.1得到指定名称的属性值属性的值
String idValue = contactElement.attributeValue("id");
System.out.println(idValue);//001
//2.2.得到指定属性名的属性对象
Attribute idAttr = contactElement.attribute("id");
//getName得到属性名 getValue得到属性值
System.out.println(idAttr.getName()+"="+idAttr.getValue());//id=001
//2.3得到所有属性的对象
List<Attribute> list = contactElement.attributes();
for (Attribute attr : list){
System.out.println(attr.getName()+"="+attr.getValue());//id=001 name=rocco
}
}
文本
Element.getText(); //获取当前标签的文本
Element.elementText("标签名") //获取当前标签的指定名称的子标签的文本内容
/**
* 获取文本内容
*/
private static void test5() throws DocumentException {
//0.读取xml文档,返回Document对象
SAXReader reader = new SAXReader();
Document doc = reader.read(new File("demo/con.xml"));
//想获取文本要先获取标签,再获取标签上的文本
Element nameElement = doc.getRootElement().element("contact").element("name");
//1.得到文本
String text = nameElement.getText();
System.out.println(text);//张三
//2.得到指定子标签的文本内容
String text2 = doc.getRootElement().element("contact").elementText("name");
System.out.println(text2);//张三
}
3.2.3.Dom4j修改xml文档
在java中修改xml文档的步骤是:
1.读取或者创建一个Document对象
2.修改Document对象
3.把修改后的Document对象写到xml文档
1.写内容到xml文档
XMLWriter writer = new XMLWriter(OutputStream, OutputForamt)
wirter.write(Document);
2.修改xml文档的API
增加:
DocumentHelper.createDocument() 增加文档
addElement("名称") 增加标签
addAttribute("名称",“值”) 增加属性
修改:
Attribute.setValue("值") 修改属性值
Element.addAtribute("同名的属性名","值") 修改同名的属性值
Element.setText("内容") 修改文本内容
删除:
Element.detach(); 删除标签
Attribute.detach(); 删除属性
private static void WriteXml() throws Exception{
//一、读取或者创建一个Document对象
//读取con.xml文件的内容
Document doc = new SAXReader().read(new File("demo/con.xml"));
//二、修改Document对象
/**
* 修改xml内容
* 增加:文档,标签,属性
* 修改:属性值,文本
* 删除:标签,属性
*/
/**
* 增加:文档,标签,属性
*/
//1.创建文档
Document doc1 = DocumentHelper.createDocument();
//2.增加标签
Element rootElem = doc1.addElement("contactList");
//2.1在contactList标签下面添加另外一个子标签
Element contactElem = rootElem.addElement("contact");
//2.2在contact标签下面添加另外一个子标签
contactElem.addElement("name");
//3.增加属性
//3.1在contactElem标签中添加一个属性,接收两个参数为别是属性名和属性值
contactElem.addAttribute("id", "001");
/**
* 修改:属性值,文本
* 属性值:1.得到标签对象,2.得到属性对象,3.修改属性值
*/
//修改属性方法1:
/*
//1.得到标签对象
Element contactElem1 = doc.getRootElement().element("contact");
//2.得到属性对象
Attribute idAttr = contactElem1.attribute("id");
//3.修改属性值
idAttr.setValue("003");
*/
//修改属性方法2:
//1.得到标签对象
Element contactElem2 = doc.getRootElement().element("contact");
//2.通过增加一个同名属性的方法,修改属性值
contactElem2.addAttribute("id","004");
/**
* 修改文本:1.得到标签对象,2.修改标签内容
*/
//1.得到标签对象
Element nameElem = doc.getRootElement().element("contact").element("name");
//2.修改标签内容
nameElem.setText("李四");
/**
* 删除:标签,属性
*/
//1.删除标签:1.得到标签对象,2.删除标签
Element ageElem = doc.getRootElement().element("contact").element("age");
//删除的两种方式,第一种是直接删除,第二种是通过福标签删除,推荐用第一种
ageElem.detach();
// ageElem.getParent().remove(ageElem);
//2.删除属性:1.得到属性,2.删除属性
//例如:删除第二个contact的属性
//2.1获得第二个contact标签
Element conElem3 = (Element)doc.getRootElement().elements().get(1);
//2.2.得到属性
Attribute idAtrr2 = conElem3.attribute("id");
//
idAtrr2.detach();
// idAtrr2.getParent().remove(idAtrr2);
//三、把修改后的Document对象写到xml文档
FileOutputStream out = new FileOutputStream("demo/www.xml");
//0.额外的知识
//指定写出的的格式
// OutputFormat format = OutputFormat.createCompactFormat();//以压缩紧凑格式写入,去除换行和空格
OutputFormat format = OutputFormat.createPrettyPrint();//以完美的排版写入
//指定生成的xml文档的编码,同时影响了xml文档的保存时的编码,以及xml的声明编码
//使用该方法可以避免解析时候的乱码问题
format.setEncoding("utf-8");
//1.创建写出对象
XMLWriter writer = new XMLWriter(out,format);//接收两个三个,一个是写出的对象,一个是以什么格式来写
//2.写出对象
writer.write(doc);
//3.关闭流
writer.close();
}
3.2.4.Xpath技术
当使用dom4j来查询比较深的层次结构的节点(标签,属性,文本)时,需要从根目录一个一个找过去,太麻烦了,所有有了Xpath技术
Xpath的作用就是用于快速获取所需的节点对象
Xpath技术的使用
1.导入:
Xpath的使用需要先导入Xpath包,导入时,选择jaxen-1.1-beta-6.jar
2.使用xpath方法
xpath只有两种方法
一种是只查询一个节点对象
Node selectSingleNode("Xpath表达式");
另一种是查询多个节点对象
List
selectNodes("Xpath表达式");
以上面的con.xml文档为例来操作
Element contactElem = (Element) doc.selectSingleNode("//contact[@id='002']");
xPath语法
这里列举一些部分常用的语法:
/ :表示从xml文档的根目录开始查找
// :不考虑路径,在整个文档中查找匹配的
* :表示匹配所有的元素
[] :表示某个特定的节点或者包含某个指定值的节点
@ :表示选择带有指定属性节点
and :表示条件的与关系,等价于&&
text() :表示选择文本内容
常用基于SAX原来的解析工具:
3.3.Sax解析工具
读取程序有两部分构成,一个是主程序,在main方法里面调用parse方法,给一个操作的文件,一个用来操作的类。另一个就是操作的类,类需要另外写,但是类中只需要写5个方法,分别是文档开始和结束,标签开始和结束,以及文本,如果需要对文件操作,就在这5个类里面操作
处理类DefaultHandler类的API:
void startDocument() : 在读到文档开始时调用
void endDocument() :在读到文档结束时调用
void startElement(String uri, String localName, String qName, Attributes attributes) :读到开始标签时调用
void endElement(String uri, String localName, String qName) :读到结束标签时调用
void characters(char[] ch, int start, int length) : 读到文本内容时调用
3.3.1.SAX解析图示:
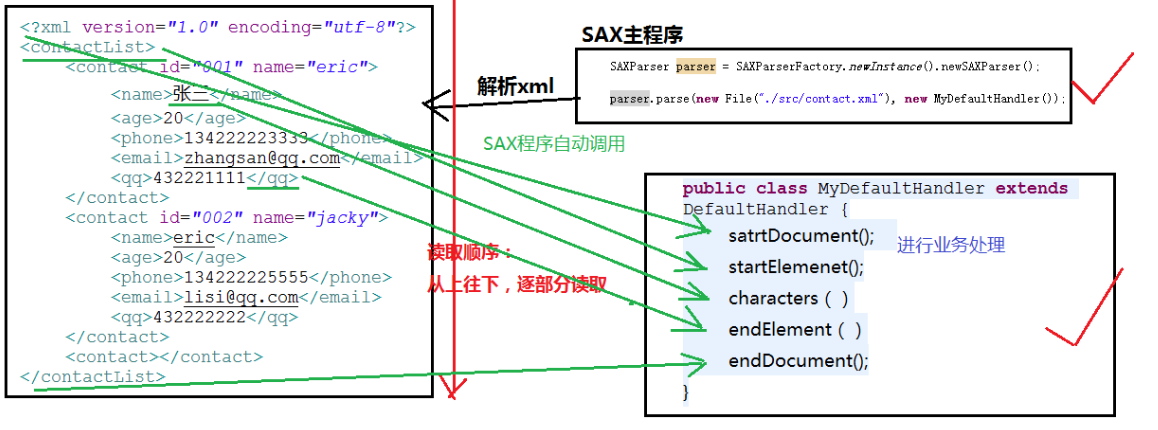
3.3.2.代码示例:
主程序:
/**
* 主程序
*/
public class SAXDemo {
public static void main(String[] args) throws Exception {
//1.创建SAXParser对象
SAXParser parser = SAXParserFactory.newInstance().newSAXParser();
//2.调用parse方法
//参数1:xml文档
//参数2:DefaultHandler的子类,是一个处理器,在这个类里面操作xml文档
parser.parse(new File("demo/con.xml"), new MyDefaultHandler());
}
操作类:
/**
* xml的操作类
*/
public class MyDefaultHandler extends DefaultHandler {
/**
* 开始文档时调用
* @throws SAXException
*/
@Override
public void startDocument() throws SAXException {
super.startDocument();
}
/**
* 开始标签时调用
* @param uri
* @param localName
* @param qName:表示开始标签的标签名
* @param attributes:表示开始标签内包含的属性列表
* @throws SAXException
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("MyDefaultHandler.startElement()-->"+qName);
}
/**
* 结束标签时调用
* @param uri
* @param localName
* @param qName:结束标签的名字
* @throws SAXException
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("MyDefaultHandler.endElement()-->"+qName);
}
/**
* 读到文本内容时调用
* @param ch:表示当前读完的所有文本内容
* @param start:表示当前文本内容的开始位置
* @param length:表示当前文本内容的长度
* @throws SAXException
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String content = new String(ch,start,length);
System.out.println("MyDefaultHandler.characters()-->"+content);
}
/**
* 结束文档调用
* @throws SAXException
*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
}
}
3.3.3.复制一个文档:
获取一个文档的内容,组合成一样的一个新文件
/**
* 读取con.xml文档,完整输出文档内容
*/
public class SAXDemo {
public static void main(String[] args) throws Exception {
//1.创建SAXParser对象
SAXParser parser = SAXParserFactory.newInstance().newSAXParser();
//2.赌气xml文档,调用parse方法
//参数1:xml文档
//参数2:DefaultHandler的子类,是一个处理器,在这个类里面操作xml文档
MyDefaultHandler handler = new MyDefaultHandler();
parser.parse(new File("demo/con.xml"), handler);
String content = handler.getContent();
System.out.println(content);
}
}
/**
* SAX处理器程序
*/
public class MyDefaultHandler extends DefaultHandler {
//存储xml文档信息
private StringBuffer sb = new StringBuffer();
//获取xml信息
public String getContent(){
return sb.toString();
}
/**
* 开始标签时调用
* @param uri
* @param localName
* @param qName:表示开始标签的标签名
* @param attributes:表示开始标签内包含的属性列表
* @throws SAXException
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
sb.append("<"+qName);
//判断是否有属性
if (attributes!=null){
for (int i = 0; i < attributes.getLength(); i++) {
//得到属性名
String attrName = attributes.getQName(i);
//得到属性值
String attrValue = attributes.getValue(i);
sb.append(" "+attrName+"=""+attrValue+""");
}
}
sb.append(">");
}
/**
* 读到文本内容时调用
* @param ch:表示当前读完的所有文本内容
* @param start:表示当前文本内容的开始位置
* @param length:表示当前文本内容的长度
* @throws SAXException
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String content = new String(ch,start,length);
sb.append(content);
}
/**
* 结束标签时调用
* @param uri
* @param localName
* @param qName:结束标签的名字
* @throws SAXException
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
sb.append("</"+qName+">");
}
}