触发Spark scheduler的入口是调用者代码中的action操作,如groupByKey,first,take,foreach等操作。这些action操作最终会调用SparkContext.runJob方法,进而调用DAGScheduler.runJob方法,从而被spark所调度使用。
用户在编写Spark程序时,每次调用transformation操作,都会生成一个新的rdd,rdd主要包含了对之前的rdd的依赖关系,新rdd的分区规则和分区个数、聚合方法等。Spark通过这种方法最终会得到一个包含多个rdd的依赖DAG图。这个DAG图为之后的stage划分打下了基础。
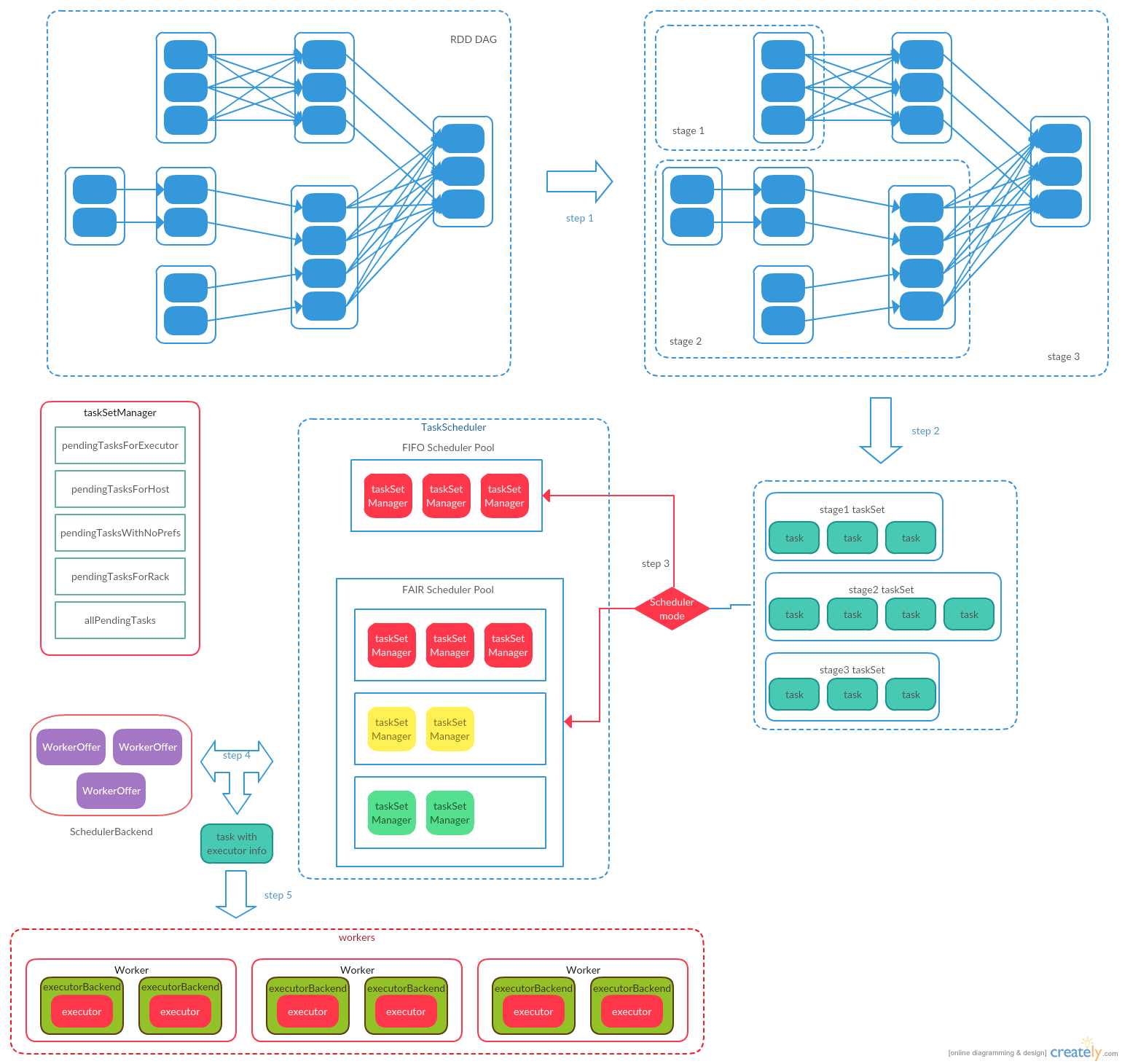
Spark有两个层级的调度器:高层级的调度器DAGScheduler和低层级的调度器TaskScheduler。其中DAGScheduler主要负责将提交的job(包括一系列的transformation和一个action操作)划分为多个阶段(stage)。DAGScheduler根据transformation操作是否是map-reduce操作将一个job划分为多个stage。在一个stage内部,可以包含多个transformation操作,这些transformation操作依赖的分区个数是常量的,数据在每个stage中是以pipeline的形式流转。stage和stage之间(类似map-reduce操作),由于分区规则发生改变,数据需要重新洗牌,下一个stage的操作必须等到上一个stage的所有操作完成后才能开始。上一个stage的每个节点首先将数据按照下一个stage第一个rdd的分区规则写入本地文件,并向driver汇报写入位置。下一个stage从driver获取到文件位置后,去对应的节点获取到所需分区的数据并保存到本地,然后开始下一个transformation操作。
DAGScheduler划分好stage后,会对stage中的每个分区(根据stage阶段的最后一个rdd确定分区数)生成一个任务(task)(也就是说在spark中是一个stage的一个分区会有一个任务,一个任务中可能会处理多个rdd,一个任务会被分配到一个executor上执行。下一个stage的任务会等待其依赖的stage的任务都执行完毕后,才会被调度到executor上执行),并调用TaskScheduler执行这些任务。TaskScheduler会根据task的分区,在集群中为task分配一个合适的executor执行(分配存在多种优先级:PROCESS_LOCAL同JVM,NODE_LOCAL同机器,RACK_LOCAL同机架,NO_PREF不需要指定优先级,ANY数据不再统一机架上)。为了获取每个任务优先执行的节点,DAGScheduler调用RDD中的getPreferredLocations方法,来获取首选的host的list。而getPreferredLocations方法在不同的RDD中有不同的实现。如对于源RDD来说(如hdfs,kafka),对应RDD分区的首选位置就是其存储数据的位置。对于ShuffledRDD来说,会调用MapOutputTracker.getPreferredLocationsForShuffle方法,根据每个节点保存分区数据的大小情况,获取首选的节点list。之后TaskScheduler会根据task的首选位置,尽量分配在同一机器的executor来运行task。TaskScheduler使用Backend(根据部署的不同,Backend有多种实现)这个后台线程来与executor通信,进行下发task,以及接收executor上报的task运行结果。
当task被下发到executor上之后,executor会最终调用task的runTask(ResultTask.runTask/ShuffleMapTask.runTask)方法来执行task。其中ResultTask.runTask直接调用传入的func来使用rdd.iterator遍历数据并执行任务。ShuffleMapTask.runTask使用rdd.iterator遍历数据,并将数据通过ShuffleManager所返回的ShuffleWriter将数据写入本地磁盘。由于task中的rdd为task中最后的rdd,所以在调用rdd.iterator时,会递归调用父rdd的iterator方法。最终会调用源rdd来读取数据(hdfs数据,kafka数据之类)或者调用ShuffleManager所返回的ShuffleReader从集群中读取map输出文件。rdd.iterator方法最终会将获取的数据(来自源rdd或shuffle map数据)保存到本地的BlockManager中,并返回在BlockManager中的iterator。然后会调用func方法(ResultTask)或ShuffleWriter.write方法(ShuffleMapTask)将iterator的数据输出。
由于Spark使用惰性求值方式(与典型的函数式编程特点类似),transformation操作只是构建了rdd的DAG图。只有在action操作时,才会真正提交任务到集群去计算。所以可以看做是使用transformation操作将数据进行一系列的包装转换后,最终使用action操作对数据进行计算。也是由于惰性求值的特性,所以在使用transformation生成新的rdd时,是没有数据计算的,action动作在stage之间使用的是pipeline的方式进行数据的转换。所以Spark在设计流程上是没有显示的保存一个中间rdd内容的功能的,数据只是在源rdd(如hdfs文件,kafka等)通过一系列的转换方法流向最终的输出rdd。所以如果需要保存中间rdd的结果,需要显示的调用cache或persist方法。
Spark程序的执行可以划分为四个阶段:
- build operator DAG:这个阶段主要根据代码中的transformation和action操作完成RDD的转换,并完成RDD的DAG的构建。
- split graph into stages of tasks:这个阶段主要完成finalStage的创建以及将1生成好的RDD的DAG划分成多个stage。最后生成task任务,并将stage和task提交到集群。
- launch tasks via cluster manager:这个阶段使用集群管理器为提交的task分配资源,将task下发到节点执行,并对失败任务进行重试。
- execute tasks:在节点执行任务,并将任务结果保存到Spark存储体系中,并向集群管理器上报任务执行情况。
流程图
CoarseGrained调度下,任务提交过程如下:
- RDD的action操作会最终提交到SparkContext中,由SparkContext调用runJob方法提交给DAGScheduler
- DAGScheduler会首先根据RDD的依赖关系将RDD划分为stages
- DAGScheduler会将每个stage划分为多个task(按照分区划分),对每个task给出首选的执行位置,然后调用TaskScheduler.submitTasks方法,提交到TaskScheduler执行。TaskScheduler中会将DAGScheduler提交的taskSet封装为TaskSetManager保存到taskSet缓存池中,然后调用SchedulerBackend.reviveOffers方法
- SchedulerBackend调用TaskScheduler.resourceOffers方法,获取TaskDescription列表(TaskDescription包含task信息和要被调度到的executor的信息),将任务分发到executor执行。TaskScheduler.resourceOffers方法首先从集群资源管理器获取到可用的executors,然后调用Pool.getSortedTaskSetQueue方法,将缓冲池中TaskSet根据调度算法排序。对每一个taskSet,遍历可执行的executor列表,根据taskSet中task的本地化级别将taskSet中的task分配给对应的executor
- ExecutorBackend收到来自SchedulerBackend下发的任务后,会调用Executor.launchTask方法来执行任务。Executor最终会调用Task.runTask方法实际执行任务,对于ResultTask类型的任务,直接调用任务的func函数计算并将结果返回给driver;对于ShuffleMapTask类型的任务,调用ShuffleWriter.write方法,将中间结果写入文件中,供下游的任务使用
DAGScheduler
DAGScheduler是面向stage调度的高层次实现。对于每一个job,都会根据RDD的DAG将其划分为多个stage,然后将一个stage按照分区划分为多个task,并以TaskSets的形式提交到TaskScheduler中,由TaskScheduler负责将这些任务调度到指定的executor上运行。只有在当前stage所依赖的stage都执行成功后,当前的stage中的任务才会被提交给TaskScheduler来执行。如果发现stage所依赖的stage数据不完整,则会重新将依赖stage的对应任务重新提交给TaskScheduler来执行。
DAGScheduler以shuffle操作作为stage的分割,stage内部的数据以管道形式流转,stage之间,下游stage必须等待上游stage成功执行后才能开始。Spark的transformation操作有两种类型:即窄依赖操作和宽依赖操作。其中窄依赖RDD操作如map,filter,其所依赖的分区数是常量的(一般就是一个),所以数据可以以管道的形式流转。这类的转换操作可以包含在相同的stage中。而宽依赖操作,如groupByKey,join等,因为要对数据进行重新分区(即shuffle操作),导致子RDD分区可能需要依赖父RDD的全部分区数据,导致子RDD的相关操作必须等到父RDD的操作完成并成功输出中间结果后才能执行。所以这类的shuffle操作是作为stage划分的依据。
此外,DAGScheduler会根据缓存的任务执行结果,决定当前任务的首选运行位置(尽量将任务分配到包含其所需要数据的节点执行),并把首选的位置信息传递给底层的TaskScheduler,由TaskScheduler负责将任务具体调度到哪个节点运行。DAGScheduler还会处理由于shuffle分区文件丢失引起的错误,如果发生此类错误,对应的stage会被重新提交。而stage中不是由于shuffle分区文件丢失的错误直接由TaskScheduler处理。TaskScheduler会在任务失败时进行重试,如果重试几次后仍然失败则直接拒绝整个stage。
submitJob
action操作在调用SparkContext.runJob之后,runJob最终会调用DAGScheduler的submitJob方法将job提交给DAGScheduler执行。submitJob处理流程如下:
- 根据RDD的分区数获取当前Job的最大分区数(maxPartitions),从而来保证不会在一个不存在的分区运行job
- 生成当前job的jobId
- 创建JobWaiter,用来响应job的运行结果
- 向eventProcessLoop(这里是DAGSchedulerEventProcessLoop)发送JobSumitted事件
- 返回JobWaiter
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
handleJobSubmitted
DAGSchedulerEventProcessLoop在收到JobSubmitted事件后,会调用handleJobSubmitted方法。handleJobSubmitted方法执行流程如下:
- 创建finalStage,生成job的stage划分。如果出现异常,则调用JobWaiter.jobFailed方法,并返回
- 创建ActiveJob,并更新jobIdToActiveJob,activeJobs,finalStage.activeJob
- 向listenerBus发送SparkListenerJobStart事件
- 提交finalStage
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// stage划分,并返回finalStage
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
// 得到当前job执行所需要的全部stageId,包括finalStage所依赖的stage,以及依赖stage的祖先stage
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
newResultStage
一个job可能会被划分为多个stage,其中最后一个stage被称为finalStage。stage和stage之间存在依赖关系。spark中存在两种类型的stage,即ResultStage和ShuffleMapStage,其中finalStage为ResultStage,其他的stage为ShuffleMapStage。具体的finalStage的生成和stage的划分由newResultStage来生成。newResultStage流程如下:
- 调用getParentStageAndId获取所有的父stage列表以及finalStage的id。
- 创建ResultStage
- 将stage注册到stageIdToStage中
- 调用updateJobIdStageIdMaps方法更新stage及其祖先stage与jobId的映射
/**
* 为指定的job创建一个ResultStage(finalStage)
*/
private def newResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
// 找到finalStage的父stage,并生成finalStage的实例
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
getParentStagesAndId
getParentStagesAndId主要是对getParentStages做了一层封装,增加了生成stageId的方法,并返回所有父stage的列表以及stage的id。
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
val parentStages = getParentStages(rdd, firstJobId)
val id = nextStageId.getAndIncrement()
(parentStages, id)
}
getParentStages
spark中的job可能会被划分为多个stage,stage的划分是从finalStage开始,从后向前根据ShuffleDependency划分stage。getParentStages用于获取/创建给定rdd的所有父stage,并将这些stage分配给firstJobId对应的job。执行流程如下:
- 首先调用getShuffleDependencies方法获取rdd所直接或间接依赖的shuffleDependency列表
- 对于列表中的每一个shuffleDependency调用getShuffleMapStage方法,创建/生成对应的stage(类型为ShuffleMapStage)
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
getShuffleDependencies
由于spark中stage通过shuffleDependency作为划分stage的原则,所以首先要确定stage的边界(即找到rdd的所有最近的shuffle依赖)。getShuffleDependencies返回的就是距离rdd最近的shuffle依赖的列表。具体流程如下:
- 创建parents来保存距离RDD最近的所有shuffleDependency,并将rdd加入waitingForVisit队列
- 获取waitingForVisit队列的第一个rdd,通过rdd的dependencies方法获取所有dependency
- 遍历每个dependency,如果dependency是shuffleDependency,则加入parents,如果不是,则通过dependency.rdd方法找到dependency对应的rdd,并加入waitingForVisit队列,供之后遍历。
- 返回parents
/**
* 返回给定RDD的最近的shuffle依赖
* 这个方法只会返回其直接或间接依赖的shuffle依赖,而不会返回shuffle依赖的shuffle依赖。
* 如C有一个在B上的shuffle依赖,B有一个shuffle依赖于A,调用rdd C
* 只会返回B<-- C上的依赖
*/
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
// 用来记录rdd shuffle依赖的rdd
// shuffle依赖的rdd不一定是传入rdd的直接父rdd,如果传入rdd对父rdd的依赖是narrowDependency,
// 则继续查找父rdd对其父rdd的依赖,如果是shuffleDependency,则也将对父父rdd的shuffleDependency加入parents
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
// 从finalRDD开始遍历
// 由于在调用transformation和action方法时,每次调用都会生成新的rdd,而新的rdd
// 的dependencies会根据调用的方法不同而将父rdd生成不同的dependencies(如join操作,其dependency就是shuffleDependency
// 而map操作,其dependency就是OneToOneDependency,即NarrowDependency)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
// 如果当前rdd的依赖是shuffleDependency,则将这个依赖加入parents
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
// 如果依赖是窄依赖,则将此rdd加入队列,从而遍历其父rdd的依赖
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
getShuffleMapStage
getShuffleMapStage方法用于获取或撞见stage并注册到shuffleToMapStage中。具体流程如下:
- 如果已经注册了shuffleDependency对应的stage,则直接返回stage
- 否则调用getAncestorShuffleDependencies方法获取shuffleDependency对应的rdd及其祖先所依赖的全部没有注册stage的shuffleDependency,获取或创建(调用newOrUsedShuffleStage方法)对应的ShuffleMapStage
- 为当前的shuffleDependency调用newOrUseedShuffleStage创建对应的stage,并向shuffleToMapStage注册
- 返回shuffleDependency对应的stage
/**
* 对传入的每个shuffleDependency生成对应的ShuffleMapStage
*/
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
// 获取每个shuffleDependency对应的ShuffleToMapStage
shuffleToMapStage.get(shuffleDep.shuffleId) match {
// 如果map中已经包含对应关系,则直接返回
case Some(stage) => stage
case None =>
// 首先先对当前shuffleDep,遍历其rdd及其祖先所依赖的全部shuffleDependency,找到还没有生成对应ShuffleMapStage的shuffleDependency
// 然后调用newOrUsedShuffleStage来生成对应的ShuffleMapStage
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
if (!shuffleToMapStage.contains(dep.shuffleId)) {
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
}
// 将当前shuffleDependency和shuffleMapStage的映射关系保存到map中
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
getAncestorShuffleDependencies
getAncestorShuffleDependencies方法用来找到RDD中直接或间接依赖的所有祖先ShuffleDependency中,还没有注册过stage的shuffleDependency。具体流程如下:
- 新建ancestors保存RDD祖先中所有没有注册过stage的shuffleDependency
- 将当前RDD加入waitingForVisit
- 从waitingForVisit获取第一个rdd,调用getShuffleDependencies方法获取到rdd所依赖的shuffleDependency
- 遍历每一个shuffleDependency,如果还没有注册过stage,则将shuffleDependency加入ancestors,并将shuffleDependency对应的rdd加入waitingForVisit
- 返回ancestors
/** 找到rdd祖先中还没有注册stage到ShuffleToMapStage的shuffleDependency */
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = {
val ancestors = new Stack[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
getShuffleDependencies(toVisit).foreach { shuffleDep =>
if (!shuffleToMapStage.contains(shuffleDep.shuffleId)) {
ancestors.push(shuffleDep)
waitingForVisit.push(shuffleDep.rdd)
} // Otherwise, the dependency and its ancestors have already been registered.
}
}
}
ancestors
}
newOrUsedStage
newOrUsedStage用来根据给定的jobId和shuffleDependency创建stage。具体流程如下:
- 首先调用newShuffleMapStage方法创建stage
- 如果mapOutputTracker中已经包含shuffleDependency的shuffleId,则直接将mapOutputTracker中保存的shuffle的mapStatus添加到stage中
- 否则直接将shuffleId以及分区数注册到mapOutputTracker中
- 返回stage
/**
* 对给定的rdd和firstJobId创建shuffleMapStage。如果对应当前shuffleId的stage已经存在,则shuffleId
* 已经被保存在MapOutputTracker中,所以有效的map输出数量和位置可以直接从MapOutputTracker中恢复
*/
private def newOrUsedShuffleStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length
val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
(0 until locs.length).foreach { i =>
if (locs(i) ne null) {
// locs(i) will be null if missing
stage.addOutputLoc(i, locs(i))
}
}
} else {
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
newShuffleMapStage
newShuffleMapStage方法真正创建ShuffleMapStage。具体流程如下:
- 调用而getParentStagesAndId获取所有父stage列表并生成当前stage的stageId
- 新建ShuffleMapStage
- 将stage注册到stageIdToStage,并调用updateJobIdStageIdMaps,更新jobId和stageId和stage的祖先stageId的映射关系
- 返回stage
private def newShuffleMapStage(
rdd: RDD[_],
numTasks: Int,
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int,
callSite: CallSite): ShuffleMapStage = {
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, firstJobId)
val stage: ShuffleMapStage = new ShuffleMapStage(id, rdd, numTasks, parentStages,
firstJobId, callSite, shuffleDep)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(firstJobId, stage)
stage
}
updateJobIdStageIdMaps
通过迭代调用内部的updateJobIdStageIdMapsList方法,最终将jobId添加到stage及其所有祖先stage的jobIds映射中。将jobId和stage及其所有祖先stage的stageId,更新到jobIdToStageIds中。
/**
* 当每次新建一个stage时,都将jobId更新到stage中,并更新jobId->stageId缓存。
* 同时要递归遍历stage所依赖的stage,将jobId更新到这些stage中,并更新jobId->stageId缓存
*/
private def updateJobIdStageIdMaps(jobId: Int, stage: Stage): Unit = {
@tailrec
def updateJobIdStageIdMapsList(stages: List[Stage]) {
if (stages.nonEmpty) {
val s = stages.head
s.jobIds += jobId
jobIdToStageIds.getOrElseUpdate(jobId, new HashSet[Int]()) += s.id
val parents: List[Stage] = getParentStages(s.rdd, jobId)
val parentsWithoutThisJobId = parents.filter { ! _.jobIds.contains(jobId) }
updateJobIdStageIdMapsList(parentsWithoutThisJobId ++ stages.tail)
}
}
updateJobIdStageIdMapsList(List(stage))
}
handleJobSubmitted方法在成功获取finalStage并划分好stage之后,就要调用submitStage方法提交finalStage。
submitStage
在提交finalStage之前,如果存在没有提交的祖先stage,则需要先提交所有没有提交的祖先stage。如果存在没有提交的祖先stage,都会先提交祖先stage,并将子stage放入waitingStages中。如果不存在没有提交的祖先stage,则提交stage中所有未提交的task。
private def submitStage(stage: Stage) {
// 首先判断是否有job需要执行当前的stage,如果有则返回最先请求的job
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 在正式提交当前stage之前,先查看是否其依赖的stage都提交成功
// 如果有依赖的stage没有成功提交的首先执行缺失的stage
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
getMissingParentStages
getMissingParentStages用来找到stage的所有不可用的祖先stage。遍历stage对应的rdd的所有依赖的shuffleDependency,如果shuffleDependency对应的stage已经输出中间结果的分区任务数量与分区数一致(即所有分区的任务都完成),则说明当前stage是可用的,反之则stage不可用并加入missing set中。最后返回missing set。
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
for (dep <- rdd.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
val mapStage = getShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
missing += mapStage
}
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
missing.toList
}
submitMissingTasks
DAGScheduler最终会调用submitMissingTasks生成stage的task并提交给TaskScheduler执行,调用这个方法时,会保证stage的祖先的stage任务都成功执行,输出的中间结果都可用。执行流程如下:
- 首先找到stage缺失的分区
- 为每个分区生成一个任务,并获取任务的首选执行位置(preferredLocations)。首选执行位置由任务所依赖的数据所在节点决定(如果是spark streaming的receiver模式,则由于数据都是由receiver获取的,所以首选执行位置会由streaming分配,即将集群上的executor均匀的分配给所有的任务)
- 序列化任务,将rdd,shuffleDep/func序列化并封装到任务中,以便在executor执行时,反序列化获取到任务的rdd和shuffleDep/func
- 为每个分区建立一个task,根据stage类型的不同会建立ShuffleMapTask/ResultTask类型的task,并将以上步骤获取的任务首选执行位置,序列化的任务传入Task
- 如果stage中存在要提交的任务,则将所有的任务包装为TaskSet并调用TaskScheduler.submitTasks来执行
- 如果stage中不存在要提交的任务,则将等待当前stage完成的子stage提交
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
stage.pendingPartitions.clear()
// 找到当前stage缺失的分区
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// 省略部分代码
// 获取每个任务的首选执行位置,map[partitionId -> locations]
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
val job = s.activeJob.get
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
//省略部分代码
}
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
var taskBinary: Broadcast[Array[Byte]] = null
try {
// 将rdd,shuffleDep/func序列化并封装到任务中,以便在executor上反序列化获取rdd及其依赖关系
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
//省略部分代码
}
val tasks: Seq[Task[_]] = try {
stage match {
// 为每个分区建立一个task
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties)
}
case stage: ResultStage =>
val job = stage.activeJob.get
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics)
}
}
} catch {
// 省略部分代码
}
if (tasks.size > 0) {
logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
stage.pendingPartitions ++= tasks.map(_.partitionId)
logDebug("New pending partitions: " + stage.pendingPartitions)
// 将stage中的任务提交给TaskScheduler执行
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
//省略部分代码
// 将等待当前stage完成的子stage重新提交
submitWaitingChildStages(stage)
}
}
TaskScheduler
TaskScheduler负责将DAGScheduler提交的每个stage的一系列任务提交到集群执行,并负责失败重试,最终将执行结果以事件的形式回传给DAGScheduler。TaskSchedulerImpl是TaskScheduler的实现类,通过不同类型的SchedulerBackend对不同类型的集群适配,并调度任务。TaskSchedulerImpl处理一些基本的逻辑,如决定job调度的顺序,唤醒并执行潜在的任务。
TaskSchedulerImpl内部维护了一个任务队列SchedulableBuilder,DAGScheduler提交的stage最终会被保存到SchedulableBuilder中,然后从队列中取出任务执行。SchedulableBuilder有两种实现,FIFOSchedulableBuilder和FairSchedulableBuilder,即是按照FIFO算法还是FAIR算法来从队列中取任务,通过spark.scheduler.mode来配置,默认为FIFO模式。
TaskSchedulerImpl内部有一个重要的组件SchedulerBackend。SchedulerBackend是与Spark运行环境(如mesos,yarn,standardalone等)相关联的类,负责与运行环境通信,申请硬件资源,负责master和slave的通信等。TaskSchedulerImpl最终会将提交上来的任务提交到SchedulerBackend,由SchedulerBackend最终将任务提交到executor上执行。
initialize
在调用TaskScheduler中其他方法之前,需要调用initialize来初始化TaSkScheduler。主要是初始化缓冲池,以及根据配置初始化调度队列。
def initialize(backend: SchedulerBackend) {
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
// 根据配置初始化不同类型的SchedulableBuilder
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported spark.scheduler.mode: $schedulingMode")
}
}
schedulableBuilder.buildPools()
}
start
Spark运行时,会启动DAGScheduler和TaskScheduler。在TaskScheduler.start方法中启动了SchedulerBackend,以及一个定时任务(speculationScheduler)来定时检查是否有任务运行缓慢,有的话需要增大任务运行的副本来加快任务的执行。
override def start() {
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}
def checkSpeculatableTasks() {
var shouldRevive = false
synchronized {
shouldRevive = rootPool.checkSpeculatableTasks(MIN_TIME_TO_SPECULATION)
}
if (shouldRevive) {
// 如果有任务执行时间过长,则再次提交taskSet,通过增大任务运行副本数来
// 加快任务执行
backend.reviveOffers()
}
}
submitTasks
submitTasks负责接收DAGScheduler提交的TaskSet。流程如下
- 根据TaskSet生成TaskSetManager
- 记录stage和TaskSet的对应关系到taskSetsByStageIdAndAttempt
- 将TaskSetManager添加到SchedulableBuilder中
- 调用SchedulerBackend.reviveOffers方法,来真正将TaskSetManager中的task提交到executor上执行
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
// 创建TaskSetManager
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
// 获取或创建stage对应的tasksets
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
// 将stage,stageAttemptId -> TaskSetManager的映射关系记录到缓存中
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
// 将TaskSetManager添加到schedulableBuilder中
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
// 定时扫描
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
// 委托给backend执行
backend.reviveOffers()
}
resourceOffers
resourceOffers由SchedulerBackend调用,用来将任务分配到executor上。集群master用这个方法来向slave分配资源。Spark循环将任务分配到从集群申请到的节点上,保证集群的负载均衡。执行流程如下:
- SchedulerBackend将其可以提供的运行资源封装为WorkerOffer传给resourceOffers
- 根据传入的每个WorkerOffer,更新各个缓存:executorIdToHost(executorId -> host),executorIdToTaskCount(executorId -> taskCount),executorsByHost(host -> executorIds),hostsByRack(host和机架的映射关系,默认无)
- 将传入的WorkerOffer顺序随机打乱,避免总将任务分配到相同的work上
- 从rootPool中获取排好序的TaskSet列表,遍历每个TaskSet,如果有新的host加入,则调用taskSet.executorAdded(),重新计算taskSet的locality level
- 遍历从rootPool获取的taskSet列表,对每个taskSet调用resourceOfferSingleTaskSet,用来实际将每个任务分配给对应的节点
def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
var newExecAvail = false
// 遍历每一个workOffer
for (o <- offers) {
// 标记executor与host的关系
executorIdToHost(o.executorId) = o.host
// 标记每个executor上任务的数量
executorIdToTaskCount.getOrElseUpdate(o.executorId, 0)
// 按照host对executor分组
if (!executorsByHost.contains(o.host)) {
executorsByHost(o.host) = new HashSet[String]()
executorAdded(o.executorId, o.host)
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
val shuffledOffers = Random.shuffle(offers)
// 为每个worker(executor)建立一个任务列表
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
// 获取当前排队中的TaskSet
val sortedTaskSets = rootPool.getSortedTaskSetQueue
// 遍历taskSet
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
var launchedTask = false
for (taskSet <- sortedTaskSets; maxLocality <- taskSet.myLocalityLevels) {
do {
launchedTask = resourceOfferSingleTaskSet(
taskSet, maxLocality, shuffledOffers, availableCpus, tasks)
} while (launchedTask)
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}
resourceOfferSingleTaskSet
resourceOfferSingleTaskSet用来将一个TaskSet中的所有task分配给合适的worker。执行流程如下:
- 遍历每一个WorkerOffer,如果当前的WorkerOffer有效的cpu大于一个任务需要的cpu数量,则尝试将任务分配给当前的WorkerOffer
- 对每一个WorkerOffer,调用taskSet.resourceOffer获取合适分配到当前WorkerOffer的任务,并更新对应的状态缓存(taskIdToTaskSetManager,taskIdToExecutorId,executorIdToTaskCount,executorsByHost),更新WorkerOffer可用的cpu数
private def resourceOfferSingleTaskSet(
taskSet: TaskSetManager,
maxLocality: TaskLocality,
shuffledOffers: Seq[WorkerOffer],
availableCpus: Array[Int],
tasks: Seq[ArrayBuffer[TaskDescription]]) : Boolean = {
var launchedTask = false
// 遍历每一个workerOffer
for (i <- 0 until shuffledOffers.size) {
val execId = shuffledOffers(i).executorId
val host = shuffledOffers(i).host
// 如果当前workOffer可用的cpu数量>每个任务要分配的cpu数量
if (availableCpus(i) >= CPUS_PER_TASK) {
try {
for (task <- taskSet.resourceOffer(execId, host, maxLocality)) {
tasks(i) += task
val tid = task.taskId
// 更新任务相关的状态
taskIdToTaskSetManager(tid) = taskSet
taskIdToExecutorId(tid) = execId
executorIdToTaskCount(execId) += 1
executorsByHost(host) += execId
// 将workerOffer的cpu分配给当前任务
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >= 0)
launchedTask = true
}
} catch {
case e: TaskNotSerializableException =>
logError(s"Resource offer failed, task set ${taskSet.name} was not serializable")
// Do not offer resources for this task, but don't throw an error to allow other
// task sets to be submitted.
return launchedTask
}
}
}
return launchedTask
}
SchedulerBackend
Spark后台资源调度系统接口。SchedulerBackend根据底层依赖的资源管理系统不同有不同的实现。当前支持的资源管理系统有本地模式,standardalone模式,yarn,mesos四种。
CoarseGrainedSchedulerBackend
CoarseGrainedSchedulerBackend是SchedulerBackend的一种实现,yarn集群使用的SchedulerBackend就是继承自CoarseGrainedSchedulerBackend。作为后台调度器,CoarseGrainedSchedulerBackend在Spark 运行期间会保持与executor之间的连接,避免了频繁的释放和申请与executor之间的连接。
makeOffers
TaskSchedulerImpl中调用的backend.reviveOffers()最终会调用CoarseGrainedSchedulerBackend中的makeOffers方法。makeOffers获取到可运行的executors,并将其包装为WorkerOffer,然后调用scheduler.resourceOffers方法将任务分配到每个executor上,并最终调用launchTasks提交任务。
private def makeOffers() {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
// 将可用的executor信息下发给slave
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toSeq
launchTasks(scheduler.resourceOffers(workOffers))
}
launchTasks
launchTasks主要用来将任务序列化后发送到executor上去执行。在发送任务之前,先判断序列化后的任务大小是否超过可发送大小的上限,超过的话直接拒绝任务,不下发到executor执行。
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = ser.serialize(task)
// 对于序列化后大于maxRpcMessageSize的任务,直接拒绝(不下发到executor执行)
if (serializedTask.limit >= maxRpcMessageSize) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logInfo(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
// 将每个任务发送到executor,对应接收方法在executor.CoarseGrainedExecutorBackend中
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
Schedulable
Spark job调度可以从两个方面来看:应用层面和应用里的Job层面。在应用层面来看,Spark底层可以选择不同的资源调度模式,如standardalone,Mesos,YARN。Spark支持应用层面的动态分配资源功能。这意味着分配给应用的资源在闲置一段时间后会被资源管理器收回;在应用资源不足时,也可以向资源管理器申请更多的资源。动态分配策略默认是关闭的,可以通过配置如下参数开启:
spark.dynamicAllocation.enabled = true
spark.shuffle.service.enabled = true
动态资源分配策略需要处理的问题是,由于资源是动态分配的,对于已经分配到executor上的资源(如shuffle map阶段,中间结果是写入executor所在机器本地磁盘;executor上也可能会缓存一部分数据),如果在应用运行过程中,发生了executor被回收,则保存在这个executor上的资源都不可用,这时需要在其他节点上重新计算生成数据。解决方法就是对于shuffle操作来说,通过配置spark.shuffle.service.enabled = true,使用external shuffle service将shuffle map的数据写入独立的外部存储中,数据不依赖executor节点,这样executor就可以动态分配。而对于缓存数据的executor,默认在应用运行过程中是不允许被集群回收的,可以通过spark.dynamicAllocation.cachedExecutorIdleTimeout来配置缓存数据的executor空闲多久后被回收(默认是不回收)。在未来的版本中,会使用类似于external shuffle service方式,单独使用独立executor的外部存储方式来保存这部分数据。
从Job层面看,如果一个应用中有多个Job(一个Spark action操作和其产生的一系列task为一个Job),如果这些Job是在不同的线程中提交的,则这些Job可以在集群上并行。而由于集群的资源是有限的,这就涉及到资源调度的问题。Spark中存在两种Job层面的资源调度策略:FIFO和FAIR(可以通过spark.scheduler.mode配置,默认是FIFO)。
FIFO调度,Spark优先会把资源都给第一个提交的Job使用,如果还有剩余的资源,则再提供给第二个Job使用。如果第一个Job使用了集群中的全部资源,则后面的Job需要排队。FAIR调度策略,Spark使用round robin策略来调度Job中的task,从而使短Job有较好的响应时间。Spark有一个root Scheduler Pool,FIFO调度策略直接将Job放入root Pool中。而FAIR调度策略,可以建立多个子pool,并加入root pool。将Job聚合后放入子pool中。每个子pool默认是可以均等的获取集群资源,也可以设置权重,改变子pool获取的集群资源的比例。在每个pool中的Job默认是以FIFO策略调度的,可以通过pool的xml配置文件指定每个子pool的调度策略。如果为每个用户建立一个子pool,则每个用户会均等的获取集群资源,而不管一个用户下有多少个Job。
可以通过spark.scheduler.allocation.file来配置调度策略,配置文件模板如下:
<?xml version="1.0"?>
<allocations>
<pool name="production">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>2</minShare>
</pool>
<pool name="test">
<schedulingMode>FIFO</schedulingMode>
<weight>2</weight>
<minShare>3</minShare>
</pool>
</allocations>
配置参数解释:
| 参数 | 解释 |
|---|---|
| schedulingMode | 可选FIFO和FAIR,用来指定调度策略 |
| weight | 设置每个pool的权重,weight=2的pool会获取到2倍的资源,默认是1 |
| minShare | 设置每个pool最小获取的资源,默认是0 |
Schedulable有两个实现类Pool和TaskSetManager。其中Pool是Spark的调度池,其中包含一个调度队列,用来保存子Pool或者TaskSetManager,从而实现诸如给每个User分配一个pool的功能。TaskSetManager作为Pool的叶子节点,可以看做是具体的调度任务,Spark最终会执行其中的TaskSet来提交任务。在FIFO模式下,只有一层Pool和Pool的叶子节点TaskSetManager。在FAIR模式下,最多可以有两层Pool,即一个RootPool和RootPool的子Pools,以及子Pool的叶子节点TaskSetManager。
Spark建立调度器流程:
- 调度器的建立是在TaskScheduler初始化时进行的,首先创建一个默认的Pool实例作为rootPool,其中poolName='',weight=0,minShare=0,schedulingMode由Spark配置参数spark.scheduler.mode指定
- 然后以rootPool为根节点构建pool tree。对于FIFO模式,只有rootPool一个节点。对于FAIR模式,读取fairscheduler.xml配置文件,解析每个子pool并加入rootPool的schedulableQueue队列,Spark当前只支持一级子pool。最后再建立一个名为default的子pool加入rootPool中(这个pool是用户在设置模式为FAIR,而又没指定taskSet提交的pool时,会将taskSet都提交到这个默认的pool)
- 在TaskScheduler.submitTasks中,为每个传入的taskSet建立新建TaskSetManager。对于FIFO模式,则直接将TaskSetManager加入rootPool的schedulableQueue队列;对于FAIR模式,如果用户配置了pool,则首先判断配置的pool是否存在(可能是在代码中指定的pool,而不是在fairscheduler.xml配置文件中),如果没有则建立pool并加入rootPool的队列中,如果用户没有配置pool,则将taskSet加入默认的子pool中(default pool)
Spark调度taskSet流程:
DAGScheduler提交的taskSet最终保存到pool中就返回了。TaskScheduler会从pool中将排好序的taskSet取出,并分发到具体的executor上执行。根据不同的调度策略,TaskScheduler使用不同排序策略。具体流程如下:
- 如果是FIFO调度策略,则直接按taskSet的priority排序(priority即taskSet的jobId),也就是说先提交的job会优先被调度
- 如果是FAIR调度策略,则按照FairSchedulingAlgorithm排序策略首先对rootPool中的子pool排序。然后遍历排好序的子pool,对子pool中的taskSet使用子pool声明的调度策略进行排序(即fairscheduler.xml或代码中配置的每个pool的schedulerMode)
- 将排好序的taskSet返回
FairSchedulingAlgorithm排序策略如下:
- 首先如果pool/taskSet中运行的task数量没有达到配置的最小,则优先执行这个pool/taskSet
- 如果运行的task数量达到了配置的最小数量,则比较minShareRatio=runningTasks.toDouble / math.max(minShare1, 1.0),较小的优先执行
- 如果minShareRatio相同,则比较taskToWeightRatio = runningTasks.toDouble / s1.weight.toDouble,较小的先执行(这个就可以保证weight越大的,获取到的集群资源越多)
- 如果taskToWeightRatio相同,则直接比较pool/taskSet的name,其中pool的name是用户指定的,而taskSet的name就是Spark内部设定的包含stageId的一个字符串,所以对于taskSet来说,stageId小的(即父stage)会先执行
由于FairSchedulingAlgorithm算法包含动态变化的变量runningTasks,所以运行task越多的pool的优先级会越低,在集群配置了多个pool时,保证集群资源不会被一个pool占满
Pool
Spark中调度池由Pool类实现。在Pool中包含一个调度队列,用来保存子Pool或者TaskSetManager。对于不同的调度策略(FIFO和FAIR)有不同的排序算法(FIFOSchedulingAlgorithm和FairSchedulingAlgorithm)
addSchedulable
向Pool中添加Schedulable类型的数据时(可以是Pool也可以是TaskSetManager),会将加入的Schedulable的父类指向当前实例,并将加入的Schedulable入当前实例的队列。
override def addSchedulable(schedulable: Schedulable) {
require(schedulable != null)
schedulableQueue.add(schedulable)
schedulableNameToSchedulable.put(schedulable.name, schedulable)
schedulable.parent = this
}
getSortedTaskSetQueue
Spark在获取调度队列中的元素时,会调用getSortedTaskSetQueue方法,会根据调度排序算法对调度队列排序后,再返回排好序的结果。
override def getSortedTaskSetQueue: ArrayBuffer[TaskSetManager] = {
var sortedTaskSetQueue = new ArrayBuffer[TaskSetManager]
val sortedSchedulableQueue =
schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
for (schedulable <- sortedSchedulableQueue) {
sortedTaskSetQueue ++= schedulable.getSortedTaskSetQueue
}
sortedTaskSetQueue
}
TaskSetManager
TaskSetManager是Schedulable的另一个实现类,主要用来管理一个TaskSet中的所有任务。这个类负责跟踪每个任务,在任务失败时负责重试(最大重试次数由maxTaskFailure指定)。TaskSetManager的主要接口是resourceOffer,用来询问其包含的TaskSet中的任务是否要在传入的节点上运行。TaskSetManager是通过本地化调度策略来找到可以在指定节点节点上运行的任务。
在实例化TaskSetManager时,会调用addPendingTask方法,根据TaskSet中每个任务的首选位置(preferredLocations)将任务分配到下列的任务列表中。
// 本地executor的task列表
private val pendingTasksForExecutor = new HashMap[String, ArrayBuffer[Int]]
// 本地节点的task列表
private val pendingTasksForHost = new HashMap[String, ArrayBuffer[Int]]
// 本地机架task列表
private val pendingTasksForRack = new HashMap[String, ArrayBuffer[Int]]
// 没有位置倾向的task列表
var pendingTasksWithNoPrefs = new ArrayBuffer[Int]
// TaskSet中所有task的列表
val allPendingTasks = new ArrayBuffer[Int]
| 本地化等级 | 说明 |
|---|---|
| PROCESS_LOCAL | 本地进程 |
| NODE_LOCAL | 本地节点 |
| NO_PREF | 没有喜好 |
| RACK_LOCAL | 本地机架 |
| ANY | 任何 |
本地化等级由上倒下依次减弱。对于NO_PREF,在分配任务时,任务会被优先分配到非本地化节点执行。
addPendingTask
根据任务首选位置的不同将任务划分到对应的本地化队列中。如果一个任务有多个首选位置,则根据首选位置的不同会将任务分配到不同的本地化队列中(即一个任务可以出现在多个本地化队列中)
private def addPendingTask(index: Int) {
for (loc <- tasks(index).preferredLocations) {
loc match {
case e: ExecutorCacheTaskLocation =>
pendingTasksForExecutor.getOrElseUpdate(e.executorId, new ArrayBuffer) += index
case e: HDFSCacheTaskLocation =>
// 针对HDFS类型的首选位置,如果在节点上存在有效的executor,则将任务放入本地executor队列
val exe = sched.getExecutorsAliveOnHost(loc.host)
exe match {
case Some(set) =>
for (e <- set) {
pendingTasksForExecutor.getOrElseUpdate(e, new ArrayBuffer) += index
}
logInfo(s"Pending task $index has a cached location at ${e.host} " +
", where there are executors " + set.mkString(","))
case None => logDebug(s"Pending task $index has a cached location at ${e.host} " +
", but there are no executors alive there.")
}
case _ =>
}
pendingTasksForHost.getOrElseUpdate(loc.host, new ArrayBuffer) += index
for (rack <- sched.getRackForHost(loc.host)) {
pendingTasksForRack.getOrElseUpdate(rack, new ArrayBuffer) += index
}
}
if (tasks(index).preferredLocations == Nil) {
pendingTasksWithNoPrefs += index
}
allPendingTasks += index // No point scanning this whole list to find the old task there
}
computeValidLocalityLevels
在初始化本地化等级task列表后,需要根据列表生成当前TaskSet的本地化等级(myLocalityLevels)。在computeValidLocalityLevels方法中,会根据上表的本地化等级,逐一判断当前TaskSet是否有任务需要在对应的本地化等级执行,并将需要的本地化等级加入myLocalityLevels队列。在myLocalityLevels队列中,本地化等级高的排在等级低的前面。
private def computeValidLocalityLevels(): Array[TaskLocality.TaskLocality] = {
import TaskLocality.{PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY}
val levels = new ArrayBuffer[TaskLocality.TaskLocality]
// 如果可以调度到executor的任务不为空 && 延迟调度时间不为0 && 等待调度到executor
// 包含当前schedule调度的executor
if (!pendingTasksForExecutor.isEmpty && getLocalityWait(PROCESS_LOCAL) != 0 &&
pendingTasksForExecutor.keySet.exists(sched.isExecutorAlive(_))) {
levels += PROCESS_LOCAL
}
if (!pendingTasksForHost.isEmpty && getLocalityWait(NODE_LOCAL) != 0 &&
pendingTasksForHost.keySet.exists(sched.hasExecutorsAliveOnHost(_))) {
levels += NODE_LOCAL
}
if (!pendingTasksWithNoPrefs.isEmpty) {
levels += NO_PREF
}
if (!pendingTasksForRack.isEmpty && getLocalityWait(RACK_LOCAL) != 0 &&
pendingTasksForRack.keySet.exists(sched.hasHostAliveOnRack(_))) {
levels += RACK_LOCAL
}
levels += ANY
logDebug("Valid locality levels for " + taskSet + ": " + levels.mkString(", "))
levels.toArray
}
getAllowedLocalityLevel
此方法用来获取当前的本地化等级。流程如下:
- 首先从前到后遍历myLocalityLevels,
- 如果对应本地化级别task队列中没有未完成或未调度的任务,则遍历myLocalityLevels的下一个等级
- 如果对应本地化级别task队列中有未完成且未调度的任务,并且当前本地化等级的任务的最后一次执行时间与当前时间的差值大于等于当前本地化等级的最大延迟等待时间,则遍历myLocalityLevels的下一个等级
- 否则直接返回当前的本地化等级
private def getAllowedLocalityLevel(curTime: Long): TaskLocality.TaskLocality = {
// 省略部分代码
while (currentLocalityIndex < myLocalityLevels.length - 1) {
val moreTasks = myLocalityLevels(currentLocalityIndex) match {
case TaskLocality.PROCESS_LOCAL => moreTasksToRunIn(pendingTasksForExecutor)
case TaskLocality.NODE_LOCAL => moreTasksToRunIn(pendingTasksForHost)
case TaskLocality.NO_PREF => pendingTasksWithNoPrefs.nonEmpty
case TaskLocality.RACK_LOCAL => moreTasksToRunIn(pendingTasksForRack)
}
if (!moreTasks) {
lastLaunchTime = curTime
logDebug(s"No tasks for locality level ${myLocalityLevels(currentLocalityIndex)}, " +
s"so moving to locality level ${myLocalityLevels(currentLocalityIndex + 1)}")
currentLocalityIndex += 1
} else if (curTime - lastLaunchTime >= localityWaits(currentLocalityIndex)) {
lastLaunchTime += localityWaits(currentLocalityIndex)
logDebug(s"Moving to ${myLocalityLevels(currentLocalityIndex + 1)} after waiting for " +
s"${localityWaits(currentLocalityIndex)}ms")
currentLocalityIndex += 1
} else {
return myLocalityLevels(currentLocalityIndex)
}
}
myLocalityLevels(currentLocalityIndex)
}
resourceOffer
在TaskSet所属的task中找到适合在传入的executorId和host上运行的task。执行流程如下:
- 首先调用getAllowedLocalityLevel,获取当前的本地化等级,从而遍历对应的本地化等级task列表,找到适合在executorId和host上运行的task
- 调用dequeueTask方法,根据当前的本地化等级,按照本地化等级从高到低,遍历大于等于当前本地化等级的本地化等级task列表,根据传入的executorId或host在task列表中寻找对应的task,如果找到则返回task。如果没有找到则查看下一个本地化等级的task队列
- 如果找到对应的task,则更新相应的缓存,序列化task等,最终生成TaskDescription并返回
def resourceOffer(
execId: String,
host: String,
maxLocality: TaskLocality.TaskLocality)
: Option[TaskDescription] =
{
if (!isZombie) {
val curTime = clock.getTimeMillis()
var allowedLocality = maxLocality
if (maxLocality != TaskLocality.NO_PREF) {
allowedLocality = getAllowedLocalityLevel(curTime)
if (allowedLocality > maxLocality) {
// We're not allowed to search for farther-away tasks
allowedLocality = maxLocality
}
}
// 将task从已经归好类的executor中取出
dequeueTask(execId, host, allowedLocality) match {
case Some((index, taskLocality, speculative)) =>
// 省略部分代码
// 最终生成TaskDescription并返回
return Some(new TaskDescription(taskId = taskId, attemptNumber = attemptNum, execId,
taskName, index, serializedTask))
case _ =>
}
}
None
}
dequeueTask
dequeueTask方法主要根据传入的execId和host找到大于maxLocality的最大本地化等级的task。
private def dequeueTask(execId: String, host: String, maxLocality: TaskLocality.Value)
: Option[(Int, TaskLocality.Value, Boolean)] =
{
for (index <- dequeueTaskFromList(execId, getPendingTasksForExecutor(execId))) {
return Some((index, TaskLocality.PROCESS_LOCAL, false))
}
if (TaskLocality.isAllowed(maxLocality, TaskLocality.NODE_LOCAL)) {
for (index <- dequeueTaskFromList(execId, getPendingTasksForHost(host))) {
return Some((index, TaskLocality.NODE_LOCAL, false))
}
}
if (TaskLocality.isAllowed(maxLocality, TaskLocality.NO_PREF)) {
// Look for noPref tasks after NODE_LOCAL for minimize cross-rack traffic
for (index <- dequeueTaskFromList(execId, pendingTasksWithNoPrefs)) {
return Some((index, TaskLocality.PROCESS_LOCAL, false))
}
}
if (TaskLocality.isAllowed(maxLocality, TaskLocality.RACK_LOCAL)) {
for {
rack <- sched.getRackForHost(host)
index <- dequeueTaskFromList(execId, getPendingTasksForRack(rack))
} {
return Some((index, TaskLocality.RACK_LOCAL, false))
}
}
if (TaskLocality.isAllowed(maxLocality, TaskLocality.ANY)) {
for (index <- dequeueTaskFromList(execId, allPendingTasks)) {
return Some((index, TaskLocality.ANY, false))
}
}
// find a speculative task if all others tasks have been scheduled
dequeueSpeculativeTask(execId, host, maxLocality).map {
case (taskIndex, allowedLocality) => (taskIndex, allowedLocality, true)}
}
CoarseGrainedExecutorBackend
在启动CoarseGrainedExecutorBackend前,会首选向driver注册当前节点的executor,如果driver拒绝当前节点的注册,则直接退出。CoarseGrainedSchedulerBackend.launchTasks方法最终会调用executorEndpoint向executor发送任务。发送的数据最终会由executor上的CoarseGrainedExecutorBackend.receive方法处理。receive方法针对不同类型的请求,调用不同的处理方法处理。对于LaunchTask请求(即driver下发的运行task的请求),receive会调用executor.launchTask方法来处理。
Executor
Spark executor,内部包含一个线程池来运行任务。Executor可以在Mesos,YARN,standalone集群上运行,使用一个RPC接口来与driver进行通信。CoarseGrainedExecutorBackend在收到CoarseGrainedSchedulerBackend发送来的任务后,会调用Executor.launchTask将任务发送给本机的Executor上执行。
launchTask
launchTask中会每次新建一个TaskRunner实例,用来封装任务,并将TaskRunner提交到线程池执行。
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
}
TaskRunner.run
TaskRunner.run方法用来具体执行任务。具体流程如下:
- 首先新建TaskMemoryManager实例,用来管理任务运行内存
- 反序列化任务,下载更新任务依赖的文件和jar包
- 调用任务的run方法真正执行任务
- 在方法返回前,生成任务运行结果并序列化,并向driver上报任务运行结果。如果序列化后的结果大于直接发送的上限,则将结果保存到本地的BlockManager中,只将BlockManager中任务运行结果的BlockId上报给driver;如果运行结果大小小于发送上限,则直接将结果发送给driver
- 最后从runningTasks中移出当前任务
override def run(): Unit = {
// 为当前任务建立TaskMemoryManager
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
// 省略部分代码
try {
//在executor上反序列化task
val (taskFiles, taskJars, taskProps, taskBytes) =
Task.deserializeWithDependencies(serializedTask)
Executor.taskDeserializationProps.set(taskProps)
// 更新依赖的文件或jar包
updateDependencies(taskFiles, taskJars)
// 将task的bytes反序列化为task实例
task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader)
task.localProperties = taskProps
task.setTaskMemoryManager(taskMemoryManager)
if (killed) {
throw new TaskKilledException
}
logDebug("Task " + taskId + "'s epoch is " + task.epoch)
env.mapOutputTracker.updateEpoch(task.epoch)
taskStart = System.currentTimeMillis()
var threwException = true
val value = try {
// 调用Task中的run方法实际执行
// 对于ShuffleMapTask,返回的是MapStatus
val res = task.run(
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {
// 省略部分代码
val accumUpdates = task.collectAccumulatorUpdates()
// 将task运行结果和task运行的各种指标封装为TaskResult
val directResult = new DirectTaskResult(valueBytes, accumUpdates)
// 将TaskResult序列化
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit
val serializedResult: ByteBuffer = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
// 如果结果大小大于最大结果大小,则直接抛弃详细信息,只返回taskId和结果大小
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
// 如果结果大小大于直接发送result的上限,则将结果保存到本地的blockManager中
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
// 如果结果大小没超过上限,则直接发送
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
// 将运行结果和监控指标上报给driver
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
// 省略部分代码
} finally {
runningTasks.remove(taskId)
}
}
Task
Task是Spark中真正运行在executor上的最小执行单位。Task有两个实现类:ResultTask和ShuffleMapTask。Spark的一个job包含一个或多个stage。job中最后一个stage(即final stage)包含多个ResultTask,而其他stage包含多个ShuffleMapTask(一般来说,Spark的stage的每个分区对应一个task)。ResultTask执行任务并将任务输出结果上报给driver。ShuffleMapTask执行任务并将任务结果根据分区策略输出到中间结果文件中,供下游的stage中的task使用(可以是ShuffleMapTask,也可以是ResultTask)
TaskRunner.run方法最终会调用Task.run方法执行任务。Task.run方法主要在真正调用子类的runTask方法之前,进行相应的初始化以及异常处理。
final def run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem): T = {
SparkEnv.get.blockManager.registerTask(taskAttemptId)
context = new TaskContextImpl(
stageId,
partitionId,
taskAttemptId,
attemptNumber,
taskMemoryManager,
localProperties,
metricsSystem,
metrics)
TaskContext.setTaskContext(context)
taskThread = Thread.currentThread()
if (_killed) {
kill(interruptThread = false)
}
try {
// 调用ResultTask/ShuffleMapTask真正执行
runTask(context)
} catch {
case e: Throwable =>
try {
context.markTaskFailed(e)
} catch {
case t: Throwable =>
e.addSuppressed(t)
}
throw e
} finally {
context.markTaskCompleted()
try {
Utils.tryLogNonFatalError {
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP)
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(MemoryMode.OFF_HEAP)
val memoryManager = SparkEnv.get.memoryManager
memoryManager.synchronized { memoryManager.notifyAll() }
}
} finally {
TaskContext.unset()
}
}
}
ResultTask
ResultTask是final stage生成的Task,用来将执行结果上报给driver应用(如collect操作,最终上报数据给调用者)。ResultTask的主要方法runTask执行流程如下:
- 首先初始化序列化器
- 使用序列化器反序列化任务,获得任务的rdd和具体的执行函数func(比如用户编码中编写的函数)
- 调用func,其中数据来自rdd.iterator方法
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
func(context, rdd.iterator(partition, context))
}
ShuffleMapTask
除了final stage的其他stage生成的Task都是ShuffleMapTask。ShuffleMapTask类似map-reduce task。ShuffleMapTask的输入可能来自原始的外部文件(如hdfs,kafka等),也可能来自父stage ShuffleMapTask输出的map文件。ShuffleMapTask最终会根据reduce的分区规则将数据输出到map文件中。ShuffleMapTask的主要方法runTask执行流程如下:
- 初始化序列化器
- 使用序列化器反序列化任务,获得任务的rdd和对其他rdd依赖dep
- 获取ShuffleManager,并根据dep.shuffleHandle获取到ShuffleManager writer
- 调用writer.writer方法,将rdd根据分区遍历的数据写入map文件中(ShuffleManager和ShuffleWriter相关请参考Spark shuffle详解)
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
// 获取shuffleManager writer
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
// 将rdd包含的rdd分区数据按照reduce分区规则写入本地磁盘
// rdd.iterator方法会调用BlockManager.getOrElseUpdate方法获取数据(如果本地没有对应块的数据,
// 则会从远端获取数据块)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}