spark shuffle模块与hadoop的map-reduce模块功能类似,都是为了完成数据的洗牌,即要为每个分区的数据改变分区规则,重新分配分区。常见在诸如groupByKey,reduceByKey,repartition,join等操作都会触发shuffle过程。Spark的stage也是按照是否存在shuffle来划分的。当出现shuffle时,下游动作必须等到上游任务完成后才能执行。
一个shuffle的操作可以分为两个阶段,即map阶段和reduce阶段。在map阶段,executor将其所管理的分区数据根据指定的分区规则重新分区,并将中间结果输出到本地文件中,并将输出结果信息上报给driver节点。在reduce阶段,executor首先从driver节点获取到当前shuffle阶段所需要的中间文件在集群上的位置,然后向保存中间文件的节点请求获取中间结果文件,在进行相关处理(如聚合,排序)将数据返回给调用者,供调用者使用。
Shuffle结构
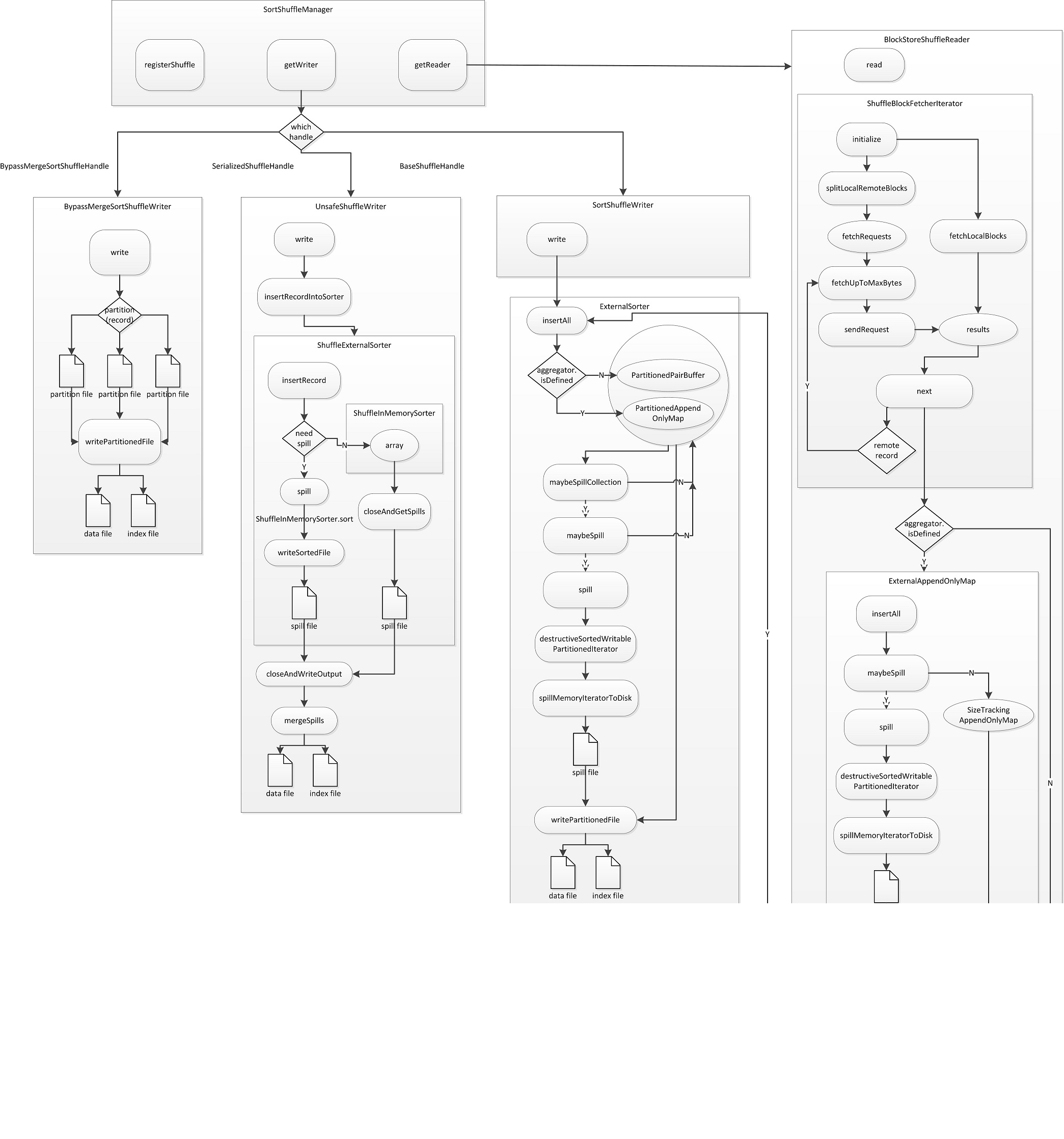
SortShuffleManager
在Spark 1.6.1中,SortShuffleManager是ShuffleManager的唯一子类,负责实现shuffle阶段的管理。主要包括getWriter,getReader,registerShuffle,unregisterShuffle等方法供map和reduce阶段使用。
在SortShuffleManager中,输入的记录会根据shuffle的分区规则将记录分配到对应的分区上,最终会将结果输出到一个map输出文件中,文件中的记录按照分区ID从小到大排序。每一个map输出文件对应一个分区索引文件,记录每个分区在文件中的偏移量。reduce任务会根据分区索引文件在map输出文件中找到需要分区的记录。当记录过多,不能在内存中装下时,会将内存中的记录临时刷新到磁盘上,这些临时文件最终会合成一个map输出文件。
registerShuffle
向SortShuffleManager注册一个shuffle,并获取对应的writer handler。
当前一共有三种类型的handler:BypassMergeSortShuffleHandle,SerializedShuffleHandle,BaseShuffleHandle,不同的handle在map阶段调用的writer不同,不同的writer在map时有不同的处理逻辑(如是否对每个分区中的记录进行聚合)
- BypassMergeSortShuffleHandle :不对shuffle后分区的记录进行聚合,对应writer BypassMergeSortShuffleWriter 只是简单的将输入记录输出到shuffle后对应的reduce分区文件中,最终将所有的分区文件合并成一个map输出文件。由于这个handle对应的writer会为每一个输入的分区建立一个临时文件,所以当输入分区很多时,会存在性能问题,所以使用BypassMergeSortShuffleHandle需要输入的分区数量小于 spark.shuffle.sort.bypassMergeThreshold 配置的大小(默认为200)。
- SerializedShuffleHandle:在不对输入记录进行反序列化的情况下,可以将记录按照shuffle后的reduce分区进行排序,并最终输出到一个map输出文件中。对应 UnsafeShuffleWriter。
- BaseShuffleHandle:如果需要对输入记录进行聚合,则使用这个方法将输入记录最终按照shuffle后的reduce分区id排序,每个分区中按照记录key的hash值进行排序。对应的writer为 SortShuffleWriter。
/**
* 向shuffleManager注册shuffle,并返回shuffle对应的handle
*/
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int, // shuffle map的数量(通常就是rdd partition的数量)
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
// 在没有指定在map阶段进行聚合且输入分区数小于bypassMergeThreshold(默认200)时,使用Bypass handle
if (SortShuffleWriter.shouldBypassMergeSort(SparkEnv.get.conf, dependency)) {
// 这里对在没指定map阶段聚合情况下,做了优化。如果partition数量大于bypassMergeThreshold,则
// 不能使用此方法。这个handle避免了在合并spill file时需要进行两次序列化/反序列化。
// 缺点是在同一时间需要打开多个文件,从而需要更多的文件缓存。
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
// 在输入的数据支持按分区id序列化重排 and 在map阶段不需要聚合
// 则使用此handle在map阶段直接对序列化数据进行操作
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
// 如果需要在map阶段进行聚合操作,使用非序列化数据进行map端聚合
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
}
getWriter
根据上文在向shuffleManager注册时返回给调用者的handle,来决定返回给调用者什么类型的writer来将输入记录输出到map输出文件中。
// 根据handle的不同返回不同的writer对象给当前的partition。被executor上的map任务调用
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int, // mapId即是partitionId
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
val env = SparkEnv.get
// 1.6.1版本支持的三种shuffleWriter
handle match {
// 直接使用序列化数据进行分区排序并输出到map文件
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
// 直接建立shuffle分区大小的临时输出文件,将输入记录直接写入对应的文件,并合并为一个map文件
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
// 当需要在map端对记录进行聚合操作时(相同的key记录进行合并),使用此方法
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}
getReader
executor上的reduce任务调用此方法来获取map输出的数据。实际是返回一个BlockStoreShuffleReader实例。
/**
* 获取reduce partition,这个方法被executor上的reduce task所调用
*/
override def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C] = {
new BlockStoreShuffleReader(
handle.asInstanceOf[BaseShuffleHandle[K, _, C]], startPartition, endPartition, context)
}
unregisterShuffle
// 删除shuffle数据,首先删除shuffleManager上的元数据(map数组)
// 再对每个partition删除磁盘上对应的data file和index file
override def unregisterShuffle(shuffleId: Int): Boolean = {
Option(numMapsForShuffle.remove(shuffleId)).foreach { numMaps =>
(0 until numMaps).foreach { mapId =>
shuffleBlockResolver.removeDataByMap(shuffleId, mapId)
}
}
true
}
ShuffleWriter
spark使用ShuffleWriter在map阶段将记录按照shuffle的分区输出到map文件中,供reduce阶段的任务来使用。ShuffleWriter在1.6.1版本中存在三个实现类:BypassMergeSortWriter(简单的建立shuffle分区数量个文件,将记录按shuffle后的reduce分区输出到对应的文件中,最后在合并成一个map文件),UnsafeShuffleWriter(直接将记录按照序列化的方式进行shuffle分区,并最终输出到map文件中),SortShuffleWriter(在map阶段对记录进行聚合,并最终输出到map文件中)。
ShuffleWriter抽象类有两个方法:
/** 将一系列的记录输出到map文件中 */
@throws[IOException]
def write(records: Iterator[Product2[K, V]]): Unit
/** 关闭当前writer,并返回map任务执行状态 */
def stop(success: Boolean): Option[MapStatus]
BypassMergeSortShuffleWriter
这个writer在写记录前,根据reduce分区数量,打开reduce分区数量个临时文件。根据reduce分区不同,将记录写入对应的临时文件中,然后将这些文件进行合并,输出到一个map文件中供reduce阶段使用。由于这个writer直接将记录写入对应的分区临时文件,所以记录不会在内存中缓存。如果shuffle后存在大量的reduce分区,则由于这个writer会为每一个reduce分区打开一个文件,所以在reduce分区众多时不会很高效。
这个writer只会在如下条件全部满足时才会被使用:
- 输入的rdd没有Ordering方法被指定
- 输入的rdd没有aggregator方法被指定
- 输入的rdd的分区数小于bypassMergeThreshold
write & writePartitionedFile
将输入的记录按照reduce分区进行排序并写入到输出的map文件中。
// 首先将记录写入对应reduce分区的临时文件中
public void write(Iterator<Product2<K, V>> records) throws IOException {
assert (partitionWriters == null);
if (!records.hasNext()) {
partitionLengths = new long[numPartitions];
shuffleBlockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, null);
mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths);
return;
}
final SerializerInstance serInstance = serializer.newInstance();
final long openStartTime = System.nanoTime();
partitionWriters = new DiskBlockObjectWriter[numPartitions];
// 对每一个reduce partition建立一个文件,所以如果partition多的话,同时会打开很多的文件
for (int i = 0; i < numPartitions; i++) {
final Tuple2<TempShuffleBlockId, File> tempShuffleBlockIdPlusFile =
blockManager.diskBlockManager().createTempShuffleBlock();
final File file = tempShuffleBlockIdPlusFile._2();
final BlockId blockId = tempShuffleBlockIdPlusFile._1();
partitionWriters[i] =
blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, writeMetrics);
}
writeMetrics.incWriteTime(System.nanoTime() - openStartTime);
// 将记录根据写入的partition写入到不同的临时文件中
while (records.hasNext()) {
final Product2<K, V> record = records.next();
final K key = record._1();
partitionWriters[partitioner.getPartition(key)].write(key, record._2());
}
for (DiskBlockObjectWriter writer : partitionWriters) {
writer.commitAndClose();
}
// 将所有的reduce分区临时文件内容按照分区id合并到一个文件
File output = shuffleBlockResolver.getDataFile(shuffleId, mapId);
File tmp = Utils.tempFileWith(output);
partitionLengths = writePartitionedFile(tmp);
shuffleBlockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, tmp);
mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths);
}
private long[] writePartitionedFile(File outputFile) throws IOException {
final long[] lengths = new long[numPartitions];
if (partitionWriters == null) {
return lengths;
}
final FileOutputStream out = new FileOutputStream(outputFile, true);
final long writeStartTime = System.nanoTime();
boolean threwException = true;
try {
// 按照reduce分区id从0到n遍历
for (int i = 0; i < numPartitions; i++) {
// 如果存在当前reduce分区的临时文件,则将文件中的内容都追加到outputFile中
// 从而实现在outputFile中,记录按照分区id进行排序
final File file = partitionWriters[i].fileSegment().file();
if (file.exists()) {
final FileInputStream in = new FileInputStream(file);
boolean copyThrewException = true;
try {
lengths[i] = Utils.copyStream(in, out, false, transferToEnabled);
copyThrewException = false;
} finally {
Closeables.close(in, copyThrewException);
}
if (!file.delete()) {
logger.error("Unable to delete file for partition {}", i);
}
}
}
threwException = false;
} finally {
Closeables.close(out, threwException);
writeMetrics.incWriteTime(System.nanoTime() - writeStartTime);
}
partitionWriters = null;
return lengths;
}
UnsafeShuffleWriter
UnsafeShuffleWriter包含一个排序类 ShuffleExternalSorter。UnsafeShuffleWriter都是使用这个类来插入数据。
write方法实际会调用 ShuffleExternalSorter 的 insertRecode 方法来插入记录。
write & closeAndWriteOutput
将输入的记录按照shuffle的给定的分区方法进行分区,然后按照分区的id进行排序并输出到map文件中。
@Override
public void write(scala.collection.Iterator<Product2<K, V>> records) throws IOException {
boolean success = false;
try {
// 将所有记录写入,最终会调用ShuffleExternalSorter中的insertRecord方法
while (records.hasNext()) {
insertRecordIntoSorter(records.next());
}
// 关闭writer,并将磁盘上的spill文件进行合并,输出到map文件中
closeAndWriteOutput();
success = true;
} finally {
// 省略代码
}
}
void closeAndWriteOutput() throws IOException {
assert(sorter != null);
updatePeakMemoryUsed();
serBuffer = null;
serOutputStream = null;
// 获取所有spilled的文件
final SpillInfo[] spills = sorter.closeAndGetSpills();
sorter = null;
final long[] partitionLengths;
// 获取最终输出的文件
final File output = shuffleBlockResolver.getDataFile(shuffleId, mapId);
// 创建最终输出文件的临时文件
final File tmp = Utils.tempFileWith(output);
try {
// 将spill文件合并到临时输出文件
partitionLengths = mergeSpills(spills, tmp);
} finally {
for (SpillInfo spill : spills) {
if (spill.file.exists() && ! spill.file.delete()) {
logger.error("Error while deleting spill file {}", spill.file.getPath());
}
}
}
// 将临时文件覆盖最终输出文件
shuffleBlockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, tmp);
mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths);
}
ShuffleExternalSorter
ShuffleExternalSorter用来将UnsafeShuffleWriter输入的记录保存并进行排序。输入的记录会首先被保存到内存的数据页中,当所有记录被插入或当前线程所使用的内存达到上限时,将内存页数据按照分区id进行排序后(使用ShuffleInMemorySorter方法),spill到磁盘中。
此sorter与SortShuffleWriter所使用的ExternalSorter不同,这个sorter不负责spill文件的合并,具体的合并操作由UnsafeShuffleWriter实现。UnsafeShuffleWriter支持直接对序列化的数据进行合并,从而避免了额外的序列化/反序列化操作。
这个类继承自MemoryConsumer,所以其所使用的内存来自execution memory,内存由TaskMemoryManager管理。当内存不足时,TaskMemoryManager会调用ShuffleExternalSorter的spill方法将记录刷新到磁盘上。
insertRecord
UnsafeShuffleWriter中的writer方法调用ShuffleExternalSorter中的insertRecord方法将数据写入。insertRecord实际调用ShuffleInMemorySorter中的insertRecord方法实际写入数据。
/**
* 将记录写入sorter中.
*/
public void insertRecord(Object recordBase, long recordOffset, int length, int partitionId)
throws IOException {
// 如果内存超过上限,则将内存中的记录spill到磁盘中
assert(inMemSorter != null);
if (inMemSorter.numRecords() > numElementsForSpillThreshold) {
spill();
}
growPointerArrayIfNecessary();
// Need 4 bytes to store the record length.
final int required = length + 4;
acquireNewPageIfNecessary(required);
assert(currentPage != null);
// 生成内存页地址
final Object base = currentPage.getBaseObject();
final long recordAddress = taskMemoryManager.encodePageNumberAndOffset(currentPage, pageCursor);
Platform.putInt(base, pageCursor, length);
pageCursor += 4;
Platform.copyMemory(recordBase, recordOffset, base, pageCursor, length);
pageCursor += length;
// 实际调用ShuffleInMemorySorter的insertRecord方法保存数据
inMemSorter.insertRecord(recordAddress, partitionId);
}
spill & writeSortedFile
当内存不足时,ShuffleExternalSorter会调用spill方法将内存中数据刷新到磁盘中。spill实际会调用writeSortedFile方法,首先将内存页中的数据按照reduce分区id进行排序(由ShuffleMemorySorter完成),然后输出到磁盘文件中。
/**
* 对内存中的记录进行排序并保存到文件中
*/
@Override
public long spill(long size, MemoryConsumer trigger) throws IOException {
// 省略代码
// 实际调用writeSorterFile进行spill操作
writeSortedFile(false);
final long spillSize = freeMemory();
inMemSorter.reset();
// 省略代码
// 返回实际释放的空间
return spillSize;
}
/**
* 对内存中的记录进行排序并将排好序的记录写入磁盘文件中。
*/
private void writeSortedFile(boolean isLastFile) throws IOException {
// 省略代码
// 获取内存中排好序的记录(根据shuffle后的partitionId进行排序)
// ShuffleInMemorySorter只在getSortedIterator方法被调用时,才会对内存中的数据进行排序
final ShuffleInMemorySorter.ShuffleSorterIterator sortedRecords =
inMemSorter.getSortedIterator();
// 获取写磁盘的writer
DiskBlockObjectWriter writer;
// 磁盘缓存
final byte[] writeBuffer = new byte[DISK_WRITE_BUFFER_SIZE];
// Because this output will be read during shuffle, its compression codec must be controlled by
// spark.shuffle.compress instead of spark.shuffle.spill.compress, so we need to use
// createTempShuffleBlock here; see SPARK-3426 for more details.
final Tuple2<TempShuffleBlockId, File> spilledFileInfo =
blockManager.diskBlockManager().createTempShuffleBlock();
final File file = spilledFileInfo._2();
final TempShuffleBlockId blockId = spilledFileInfo._1();
final SpillInfo spillInfo = new SpillInfo(numPartitions, file, blockId);
// 为了调用getDiskWriter而生成的序列化器实例,实际这个方法不会用到这个序列化器
final SerializerInstance ser = DummySerializerInstance.INSTANCE;
writer = blockManager.getDiskWriter(blockId, file, ser, fileBufferSizeBytes, writeMetricsToUse);
int currentPartition = -1;
// 将记录按照partition写入临时文件
while (sortedRecords.hasNext()) {
sortedRecords.loadNext();
final int partition = sortedRecords.packedRecordPointer.getPartitionId();
assert (partition >= currentPartition);
if (partition != currentPartition) {
// 如果已经遍历到下一个分区,则记录当前分区所包含的记录数
if (currentPartition != -1) {
writer.commitAndClose();
// 记录当前partition所包含的记录数
spillInfo.partitionLengths[currentPartition] = writer.fileSegment().length();
}
// 对每一个分区都会新建一个writer
currentPartition = partition;
writer =
blockManager.getDiskWriter(blockId, file, ser, fileBufferSizeBytes, writeMetricsToUse);
}
// 将内存中的记录实际写入磁盘
final long recordPointer = sortedRecords.packedRecordPointer.getRecordPointer();
final Object recordPage = taskMemoryManager.getPage(recordPointer);
final long recordOffsetInPage = taskMemoryManager.getOffsetInPage(recordPointer);
int dataRemaining = Platform.getInt(recordPage, recordOffsetInPage);
long recordReadPosition = recordOffsetInPage + 4; // skip over record length
while (dataRemaining > 0) {
final int toTransfer = Math.min(DISK_WRITE_BUFFER_SIZE, dataRemaining);
Platform.copyMemory(
recordPage, recordReadPosition, writeBuffer, Platform.BYTE_ARRAY_OFFSET, toTransfer);
writer.write(writeBuffer, 0, toTransfer);
recordReadPosition += toTransfer;
dataRemaining -= toTransfer;
}
writer.recordWritten();
}
if (writer != null) {
writer.commitAndClose();
// 记录最后一个分区所包含的记录数
if (currentPartition != -1) {
spillInfo.partitionLengths[currentPartition] = writer.fileSegment().length();
// 将当前spill的文件的每个分区对应的fileSegment信息保存到spills中
spills.add(spillInfo);
}
}
// 省略代码
}
}
ShuffleInMemorySorter
ShuffleInMemorySorter实际用来保存输入记录在内存页中的指针,并对输入的记录进行排序,支持基数排序和timsort排序两种排序方法,默认使用基数排序。
insertRecord
使用数组来保存输入记录以及其所在reduce分区id的指针(由PackedRecordPointer封装)。
public void insertRecord(long recordPointer, int partitionId) {
if (!hasSpaceForAnotherRecord()) {
throw new IllegalStateException("There is no space for new record");
}
array.set(pos, PackedRecordPointer.packPointer(recordPointer, partitionId));
pos++;
}
getSortedIterator
对内存中的数据进行排序,并返回iterator。
/**
* 返回排序后的iterator
*/
public ShuffleSorterIterator getSortedIterator() {
int offset = 0;
// 如果使用基数排序
if (useRadixSort) {
// 对数据排序
offset = RadixSort.sort(
array, pos,
PackedRecordPointer.PARTITION_ID_START_BYTE_INDEX,
PackedRecordPointer.PARTITION_ID_END_BYTE_INDEX, false, false);
} else { // 使用timsort排序
MemoryBlock unused = new MemoryBlock(
array.getBaseObject(),
array.getBaseOffset() + pos * 8L,
(array.size() - pos) * 8L);
LongArray buffer = new LongArray(unused);
Sorter<PackedRecordPointer, LongArray> sorter =
new Sorter<>(new ShuffleSortDataFormat(buffer));
// 对数据排序
sorter.sort(array, 0, pos, SORT_COMPARATOR);
}
return new ShuffleSorterIterator(pos, array, offset);
}
SortShuffleWriter
SortShuffleWriter与BypassMergeSortShuffleWriter和UnsafeShuffleWriter最大的不同在于他可以在map阶段对输入的记录按照key hashcode进行聚合以及对分配到每个reduce分区里的记录按照key hashcode进行排序。SortShuffleWriter具体的排序方法委托给 ExternalSorter 这个排序器来完成。
write
/** 将输入记录排序后输出到map文件中 */
override def write(records: Iterator[Product2[K, V]]): Unit = {
// 根据是否需要对map的输出进行排序,来构建externalSorter
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// 如果在map阶段不需要聚合排序,则与bypass和unsafe shuffleWriter一样,只对输入记录按照reduce分区排序,并输出到map文件中
// 实际的聚合排序在reduce阶段进行
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
// 将记录保存到内存中,并有sorter负责刷新到磁盘上
sorter.insertAll(records)
// 获取输出文件位置
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
// 构建临时文件
val tmp = Utils.tempFileWith(output)
// 生成ShuffleBlockId
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
// 将数据写入临时文件,返回每个partition对应的大小
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
// 生成索引文件并将临时文件重命名为最终文件
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
// 更新map状态
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
}
ExternalSorter
ExternalSorter实现对输入记录的排序,以及按照key hashcode对记录按照给定的聚合函数进行聚合,对reduce分区内的按照key hashcode进行排序,并最终将结果输出到一个map文件中。
ExternalSorter内部有两种缓存数据结构:PartitionedAppendOnlyMap和PartitionedPairBuffer。如果需要在map阶段进行聚合排序操作,则使用PartitionedAppendOnlyMap,否则则使用PartitionedPairBuffer。在记录输入过程中,会不断向缓存中写入数据,如果缓存达到内存上限,则要将缓存中的内容spill到磁盘中。当调用者(SortShuffleWriter)请求输出文件时,则将spill到磁盘上的所有文件和缓存中剩余的记录进行合并,并以一个map文件的形式输出。
ExternalSorter继承自Spillable类,而Spillable继承自MemoryConsumer,所以ExternalSorter所使用的内存也都来自execution memory,由TaskMemoryManager管理。
insertAll
将输入记录写入sorter内存中,如果内存不足则将内存中记录spill到磁盘上,并清空内存。
def insertAll(records: Iterator[Product2[K, V]]): Unit = {
val shouldCombine = aggregator.isDefined
// 如果需要在map端进行聚合,则使用PartitionedAppendOnlyMap作为缓存,将record根据key放入map中,将value按照给定的聚合函数进行聚合
if (shouldCombine) {
// 获取聚合函数
val mergeValue = aggregator.get.mergeValue
// 获取createCombiner函数
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
// 如果已经存在相同key记录,则使用聚合函数进行合并,否则使用createCombiner进行初始化赋值
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
// 遍历所有输入记录
while (records.hasNext) {
addElementsRead()
kv = records.next()
// 将记录插入map中
map.changeValue((getPartition(kv._1), kv._1), update)
// 判断是否需要进行spill操作
maybeSpillCollection(usingMap = true)
}
} else {
// 如果不需要合并,则直接将record放入PartitionedPairBuffer中
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
}
maybeSpillCollection
使用预估当前缓存(map/buffer)已使用大小方法,判断是否超过内存上限,如果超过则将缓存中数据spill到磁盘中,并重置缓存。
/**
* 预估当前map/buffer使用量是否超过设定的上限,如果超过则将map/buffer内容写入磁盘,清空map/buffer
*/
private def maybeSpillCollection(usingMap: Boolean): Unit = {
var estimatedSize = 0L
// 使用estimateSize方法预估当前map/buffer使用量
if (usingMap) {
estimatedSize = map.estimateSize()
// 如果超过内存上限,色调用maybeSpill方法将内存数据刷新到磁盘中,并生成新的map
if (maybeSpill(map, estimatedSize)) {
map = new PartitionedAppendOnlyMap[K, C]
}
} else {
estimatedSize = buffer.estimateSize()
// 如果超过内存上限,色调用maybeSpill方法将内存数据刷新到磁盘中,并生成新的buffer
if (maybeSpill(buffer, estimatedSize)) {
buffer = new PartitionedPairBuffer[K, C]
}
}
if (estimatedSize > _peakMemoryUsedBytes) {
_peakMemoryUsedBytes = estimatedSize
}
}
Spillable.maybeSpill
ExternalSorter实际调用父类Spillable的maybeSpill方法在预估到map/buffer中内存不足时,尝试进行spill操作。在真正进行spill之前,会先尝试向TaskMemoryManager申请内存,如果申请内存后的缓存大小大于预估的使用大小,则不需要进行spill,否则进行实际的spill操作
/**
* 将内存中的集合spill到磁盘中,在真正spill之前尝试获取更多的内存。
*/
protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
var shouldSpill = false
// 在将内存刷新到磁盘之前先尝试多分配一些内存
if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) {
val amountToRequest = 2 * currentMemory - myMemoryThreshold
// 这里通过MemoryConsumer来申请execution memory
val granted = acquireMemory(amountToRequest)
myMemoryThreshold += granted
// 判断是否真的需要spill
shouldSpill = currentMemory >= myMemoryThreshold
}
// 如果申请的内存还是不够,或者内存中保存的元素数量达到需要强制刷新的上限
// 才真正刷磁盘
shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold
// Actually spill
if (shouldSpill) {
_spillCount += 1
logSpillage(currentMemory)
spill(collection)
_elementsRead = 0
_memoryBytesSpilled += currentMemory
// 释放execution memory
releaseMemory()
}
shouldSpill
}
Spillable.spill
将内存中数据spill到磁盘中。这个方法只对堆内内存模式的execution memory进行spill操作。实际调用子类(ExternalSorter)的forceSpill来将内存数据刷新到磁盘中。返回释放的内存大小。
override def spill(size: Long, trigger: MemoryConsumer): Long = {
if (trigger != this && taskMemoryManager.getTungstenMemoryMode == MemoryMode.ON_HEAP) {
val isSpilled = forceSpill()
if (!isSpilled) {
0L
} else {
val freeMemory = myMemoryThreshold - initialMemoryThreshold
_memoryBytesSpilled += freeMemory
releaseMemory()
freeMemory
}
} else {
0L
}
}
spillMemoryIteratorToDisk
forceSpill会最终调用spillMemoryIteratorToDisk将内存中排好序/聚合好的数据刷新到磁盘上。map/buffer的iterator在返回前会对其中的元素进行排序。
/**
* 将内存数据输出到磁盘的临时文件
*/
private[this] def spillMemoryIteratorToDisk(inMemoryIterator: WritablePartitionedIterator)
: SpilledFile = {
// 创建临时文件
val (blockId, file) = diskBlockManager.createTempShuffleBlock()
// These variables are reset after each flush
var objectsWritten: Long = 0
var spillMetrics: ShuffleWriteMetrics = null
var writer: DiskBlockObjectWriter = null
// 获取临时文件的writer
def openWriter(): Unit = {
assert (writer == null && spillMetrics == null)
spillMetrics = new ShuffleWriteMetrics
writer = blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, spillMetrics)
}
openWriter()
// 记录每次flush磁盘的数据大小
val batchSizes = new ArrayBuffer[Long]
// How many elements we have in each partition
// 记录文件中每个分区记录的个数
val elementsPerPartition = new Array[Long](numPartitions)
// 将缓存中的内容刷新到磁盘上,并更新对应变量
def flush(): Unit = {
val w = writer
writer = null
w.commitAndClose()
_diskBytesSpilled += spillMetrics.bytesWritten
// 记录一次刷新多大的数据到磁盘
batchSizes.append(spillMetrics.bytesWritten)
spillMetrics = null
objectsWritten = 0
}
var success = false
try {
// 遍历内存中的数据
while (inMemoryIterator.hasNext) {
val partitionId = inMemoryIterator.nextPartition()
require(partitionId >= 0 && partitionId < numPartitions,
s"partition Id: ${partitionId} should be in the range [0, ${numPartitions})")
// 将记录写入writer缓存
inMemoryIterator.writeNext(writer)
// 记录每个分区有多少个记录
elementsPerPartition(partitionId) += 1
objectsWritten += 1
// 当writer缓存中的记录达到刷新上限时,一次将serializerBatchSize的记录刷新到磁盘上
if (objectsWritten == serializerBatchSize) {
flush()
openWriter()
}
}
if (objectsWritten > 0) {
flush()
} else if (writer != null) {
val w = writer
writer = null
w.revertPartialWritesAndClose()
}
success = true
} finally {
if (!success) {
// This code path only happens if an exception was thrown above before we set success;
// close our stuff and let the exception be thrown further
if (writer != null) {
writer.revertPartialWritesAndClose()
}
if (file.exists()) {
if (!file.delete()) {
logWarning(s"Error deleting ${file}")
}
}
}
}
SpilledFile(file, blockId, batchSizes.toArray, elementsPerPartition)
}
writePartitionedFile
此方法由SortShuffleWriter调用,来获取按照shuffle分区规则重新分区后的map输出文件。将spill到磁盘的所有临时文件和内存中的数据进行合并,并写入一个map输出文件,并返回每个分区在map输出文件中的偏移量数组。实际合并缓存和磁盘文件的操作由partitionedIterator实现。
/**
* 将ExternalSorter上的数据(包括spill到磁盘的数据和缓存中的数据)都写到磁盘中的一个文件中
*/
def writePartitionedFile(
blockId: BlockId,
outputFile: File): Array[Long] = {
val writeMetrics = context.taskMetrics().shuffleWriteMetrics
// 用来保存每个reduce分区在最终的outputFile中的偏移量
val lengths = new Array[Long](numPartitions)
// 如果在向externalSorter添加记录时,没有发生将内存数据刷到磁盘上,则spill=null
if (spills.isEmpty) {
val collection = if (aggregator.isDefined) map else buffer
// 根据排序比较器comparator对缓存中的数据进行排序并返回iterator
val it = collection.destructiveSortedWritablePartitionedIterator(comparator)
// 将partition数据写到一个文件中,通过lengths记录每个partition的大小
while (it.hasNext) {
// 对每个分区都新建一个writer
val writer = blockManager.getDiskWriter(
blockId, outputFile, serInstance, fileBufferSize, writeMetrics)
val partitionId = it.nextPartition()
// 遍历当前分区的内容并写入writer
while (it.hasNext && it.nextPartition() == partitionId) {
it.writeNext(writer)
}
writer.commitAndClose()
val segment = writer.fileSegment()
// 记录分区偏移量
lengths(partitionId) = segment.length
}
} else {
// 如果记录存在在磁盘和内存中,则需要进行合并
// 调用partitionedIterator对内存和磁盘中的数据进行合并,返回(分区id,数据)的iterator
for ((id, elements) <- this.partitionedIterator) {
if (elements.hasNext) {
// 为每一个分区新建writer
val writer = blockManager.getDiskWriter(
blockId, outputFile, serInstance, fileBufferSize, writeMetrics)
for (elem <- elements) {
writer.write(elem._1, elem._2)
}
writer.commitAndClose()
val segment = writer.fileSegment()
// 记录分区偏移量
lengths(id) = segment.length
}
}
}
// 监控指标更新
context.taskMetrics().incMemoryBytesSpilled(memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(peakMemoryUsedBytes)
// 返回每个分区在outputFile中的偏移量的数组
lengths
}
partitionedIterator & merge
mergeWithAggregation&mergeSort用来对map结果进行聚合/排序。对已经排好序/聚合好的多个文件取出每个文件中的第一个元素,使用堆排进行排序。当调用者遍历iterator时,对聚合来说,是首先拿到堆顶元素,并找到堆中key与对应元素相同的元素,进行聚合,并返回。同时从对应文件取出下一个元素填充到堆中。对于排序来说,则直接返回堆顶元素,并从元素所属文件中取出下一个元素填充到堆中。
/**
* 将内存和磁盘中的数据进行合并,并按照partition分组,按照请求的聚合方式聚合数据并返回。
*
* 如果数据都在内存中,则直接对内存中的数据进行排序(先按照分区id排序,如果需要对分区中的数据进行排序(即
* ordering.isDefined)则再按照指定的排序规则进行排序),然后将数据按照分区id进行分组,并返回。
* 如果数据部分在内存中,部分在磁盘中,则调用merge函数将磁盘中的数据和内存中的数据合并,并返回。
*/
def partitionedIterator: Iterator[(Int, Iterator[Product2[K, C]])] = {
val usingMap = aggregator.isDefined
val collection: WritablePartitionedPairCollection[K, C] = if (usingMap) map else buffer
// 数据只在内存中
if (spills.isEmpty) {
// 是否要对每个分区中的数据进行排序
if (!ordering.isDefined) {
// 将数据排序后按照分区id分组并返回
groupByPartition(destructiveIterator(collection.partitionedDestructiveSortedIterator(None)))
} else {
// 使用指定的key比较器对数据排序后按照分区id分组并返回
groupByPartition(destructiveIterator(
collection.partitionedDestructiveSortedIterator(Some(keyComparator))))
}
} else {
// 调用merge函数将磁盘和内存数据合并
merge(spills, destructiveIterator(
collection.partitionedDestructiveSortedIterator(comparator)))
}
}
private def merge(spills: Seq[SpilledFile], inMemory: Iterator[((Int, K), C)])
: Iterator[(Int, Iterator[Product2[K, C]])] = {
// 获取每个spill文件的reader
val readers = spills.map(new SpillReader(_))
// 获取内存中的数据(传入merge方法的内存数据是已经排好序的)
val inMemBuffered = inMemory.buffered
// 遍历每个reduce分区
(0 until numPartitions).iterator.map { p =>
// 获取内存中对应分区的数据
val inMemIterator = new IteratorForPartition(p, inMemBuffered)
// 将内存中数据和磁盘中对应分区的数据合并(reader使用NIO进行遍历,每次只读固定大小的数据到内存中)
val iterators = readers.map(_.readNextPartition()) ++ Seq(inMemIterator)
if (aggregator.isDefined) {
// 如果定义了聚合器,则按照聚合方法进行合并
(p, mergeWithAggregation(
iterators, aggregator.get.mergeCombiners, keyComparator, ordering.isDefined))
} else if (ordering.isDefined) {
// 否则如果定义了排序方法,则按照排序规则进行合并
(p, mergeSort(iterators, ordering.get))
} else {
// 如果没有定义聚合,排序方法,则直接按照分区id排序分组后返回
(p, iterators.iterator.flatten)
}
}
}
ExternalSorter缓存

PartitionedAppendOnlyMap
PartitionedAppendOnlyMap继承自SizeTrackingAppendOnlyMap,而SizeTrackingAppendOnlyMap继承自AppendOnlyMap。可以将PartitionedAppendOnlyMap看做是带预估map大小功能的AppendOnlyMap。用来向map中追加和键值对,更新(更新操作提供了两个函数update和changeValue,其中update直接用新值覆盖旧值,changeValue则使用传入的updateFunc来更新值)已存在的键的值。底层使用数组来保存键值对,偶数位保存键,奇数位保存值。此map使用二次探测方式处理键的hash值碰撞。
插入更新操作update
首先判断是否需要进行扩容,具体扩容操作由growTable方法完成。然后判断插入的键是否存在,如果存在则更新值,不存在则插入值。
/** Set the value for a key */
def update(key: K, value: V): Unit = {
assert(!destroyed, destructionMessage)
val k = key.asInstanceOf[AnyRef]
if (k.eq(null)) {
if (!haveNullValue) {
// 增加大小并判断是否需要扩容
incrementSize()
}
nullValue = value
haveNullValue = true
return
}
var pos = rehash(key.hashCode) & mask
var i = 1
while (true) {
val curKey = data(2 * pos)
// 插入/更新值
if (curKey.eq(null)) {
data(2 * pos) = k
data(2 * pos + 1) = value.asInstanceOf[AnyRef]
incrementSize() // Since we added a new key
return
} else if (k.eq(curKey) || k.equals(curKey)) {
data(2 * pos + 1) = value.asInstanceOf[AnyRef]
return
} else {
val delta = i
pos = (pos + delta) & mask
i += 1
}
}
}
扩容growTable
// 扩容map
protected def growTable() {
// 将数组容量扩充2倍
val newCapacity = capacity * 2
require(newCapacity <= MAXIMUM_CAPACITY, s"Can't contain more than ${growThreshold} elements")
// 新建数组
val newData = new Array[AnyRef](2 * newCapacity)
val newMask = newCapacity - 1
// 将老数组中的数据rehash后放入新数组,如果发生hash碰撞,则二次探测
var oldPos = 0
while (oldPos < capacity) {
if (!data(2 * oldPos).eq(null)) {
val key = data(2 * oldPos)
val value = data(2 * oldPos + 1)
var newPos = rehash(key.hashCode) & newMask
var i = 1
var keepGoing = true
while (keepGoing) {
val curKey = newData(2 * newPos)
if (curKey.eq(null)) {
newData(2 * newPos) = key
newData(2 * newPos + 1) = value
keepGoing = false
} else {
val delta = i
newPos = (newPos + delta) & newMask
i += 1
}
}
}
oldPos += 1
}
// 使用新数组替换老数组
data = newData
capacity = newCapacity
mask = newMask
growThreshold = (LOAD_FACTOR * newCapacity).toInt
}
遍历map
当ExternalSorter要获取map中的数据时,会调用此方法。这个方法首先会对数组进行压缩,去除为null的项。然后使用timsort对数组进行排序并返回iterator。调用这个函数的缺点是由于是直接对map底层的数组进行操作,会破坏map结构。
/**
* 返回排好序的map,这个方法不会使用额外的内存,缺点就是会改变map原来的key-value顺序
*/
def destructiveSortedIterator(keyComparator: Comparator[K]): Iterator[(K, V)] = {
destroyed = true
var keyIndex, newIndex = 0
// 去掉数组中key=null的项(数组压缩)
while (keyIndex < capacity) {
if (data(2 * keyIndex) != null) {
data(2 * newIndex) = data(2 * keyIndex)
data(2 * newIndex + 1) = data(2 * keyIndex + 1)
newIndex += 1
}
keyIndex += 1
}
assert(curSize == newIndex + (if (haveNullValue) 1 else 0))
// 使用timSort对数组进行排序
new Sorter(new KVArraySortDataFormat[K, AnyRef]).sort(data, 0, newIndex, keyComparator)
// 返回排好序的数组的iterator
new Iterator[(K, V)] {
var i = 0
var nullValueReady = haveNullValue
def hasNext: Boolean = (i < newIndex || nullValueReady)
def next(): (K, V) = {
if (nullValueReady) {
nullValueReady = false
(null.asInstanceOf[K], nullValue)
} else {
val item = (data(2 * i).asInstanceOf[K], data(2 * i + 1).asInstanceOf[V])
i += 1
item
}
}
}
}
PartitionedPairBuffer
继承自WritablePartitionedPairCollection。一个只追加键值对的数据结构,并记录保存在其中数据的预估大小。底层使用数组来保存数据,偶数位保存键,奇数位保存值。
插入操作insert
/** Add an element into the buffer */
def insert(partition: Int, key: K, value: V): Unit = {
if (curSize == capacity) {
// 如果数组大小达到容量上限,则进行扩容
growArray()
}
// 偶数位保存键,奇数位保存值
data(2 * curSize) = (partition, key.asInstanceOf[AnyRef])
data(2 * curSize + 1) = value.asInstanceOf[AnyRef]
curSize += 1
// 在每次插入后,判断是否需要重新采样,预估当前保存的数据大小
afterUpdate()
}
扩容操作 growArray
扩容操作只是简单的将容量扩大2倍,并重置采样结果
/** Double the size of the array because we've reached capacity */
private def growArray(): Unit = {
if (capacity >= MAXIMUM_CAPACITY) {
throw new IllegalStateException(s"Can't insert more than ${MAXIMUM_CAPACITY} elements")
}
val newCapacity =
if (capacity * 2 < 0 || capacity * 2 > MAXIMUM_CAPACITY) { // Overflow
MAXIMUM_CAPACITY
} else {
capacity * 2
}
val newArray = new Array[AnyRef](2 * newCapacity)
System.arraycopy(data, 0, newArray, 0, 2 * capacity)
data = newArray
capacity = newCapacity
resetSamples()
}
遍历元素partitionedDestructiveSortedIterator
此方法是对WritablePartitionedPairCollection中方法的具体实现,保证每次返回给调用者的iterator都是按照keyComparator进行了排序的有序结果。内部使用timsort进行排序。
/** Iterate through the data in a given order. For this class this is not really destructive. */
override def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)] = {
// buffer只是根据partition id对内存中保存的记录做了排序
val comparator = keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator)
new Sorter(new KVArraySortDataFormat[(Int, K), AnyRef]).sort(data, 0, curSize, comparator)
iterator
}
private def iterator(): Iterator[((Int, K), V)] = new Iterator[((Int, K), V)] {
var pos = 0
override def hasNext: Boolean = pos < curSize
override def next(): ((Int, K), V) = {
if (!hasNext) {
throw new NoSuchElementException
}
val pair = (data(2 * pos).asInstanceOf[(Int, K)], data(2 * pos + 1).asInstanceOf[V])
pos += 1
pair
}
}
SizeTracker
PartitionedAppendOnlyMap和PartitionedPairBuffer使用SizeTracker实现对自身保存数据大小的采样预估。主要包括采样(takeSample)和预估(estimateSize)两个方法。SizeTracker会维护一个计数器numUpdates来保存插入的记录次数。对每次插入的数据大小使用公式
$$ avgPerUpdateSize = (lastestSize - previousSize) / (lastestUpdateNum - previousUpdateNum)
$$
来计算,即平均每次插入的数据大小=当前缓存大小-上次采样时缓存大小/间隔的更新次数。
预估时使用公式:
$$ estimateSize = avgPerUpdateSize * (numUpdates - lastestUpdateNum) + lastestSize
$$
即当前缓存预估的大小=上次采样时的大小+采样后到现在预估增长的大小。
/**
* 重新采样,计算在两次采样之间每次更新平均扩大的bytes大小
*/
private def takeSample(): Unit = {
samples.enqueue(Sample(SizeEstimator.estimate(this), numUpdates))
// Only use the last two samples to extrapolate
if (samples.size > 2) {
samples.dequeue()
}
val bytesDelta = samples.toList.reverse match {
case latest :: previous :: tail =>
(latest.size - previous.size).toDouble / (latest.numUpdates - previous.numUpdates)
// If fewer than 2 samples, assume no change
case _ => 0
}
bytesPerUpdate = math.max(0, bytesDelta)
// 延长下次采样时间
nextSampleNum = math.ceil(numUpdates * SAMPLE_GROWTH_RATE).toLong
}
/**
* 估算当前大小。size = 最后一次采样时大小 + (当前updates-最后一次采样updates)* 平均采样每次更新大小
*/
def estimateSize(): Long = {
assert(samples.nonEmpty)
val extrapolatedDelta = bytesPerUpdate * (numUpdates - samples.last.numUpdates)
(samples.last.size + extrapolatedDelta).toLong
}
ShuffleReader (BlockStoreShuffleReader)
不同于shuffleWriter,ShuffleReader只有一个实现类即BlockStoreShuffleReader。当reduce任务需要获取map任务的输出时首先会向Driver请求得到保存有其需要的map文件的节点的地址信息。然后新建ShuffleBlockFetcherIterator实例去相应的节点获取map文件(对于非本地的节点则通过网络请求分批获取数据,对于本地节点则直接返回map文件在本地的物理存储位置)。在获取到iterator之后,会调用各种封装方法将原始的iterator封装为所需要的iterator(获取map数据是惰性的,这里只是对iterator进行各种包装变换,并没有真正去获取数据)。
如果rdd需要进行聚合,则会在reduce阶段对从map文件获取到的数据按key进行聚合(此处会真正调用ShuffleBlockFetcherIterator从远端和本地获取到所有的数据,并将数据写入缓存中,如果缓存不足则将数据按key排序后spill到磁盘上,返回聚合好的iterator。在真正遍历聚合好的iterator时,会使用堆排序方法首先将堆中key相同的结果进行聚合,然后将spill文件中后续数据放入堆中,并返回聚合好的数据)。
如果rdd需要按key排序,则在reduce阶段会对所有获取到的数据进行排序(此处会真正调用ShuffleBlockFetcherIterator从远端和本地获取到所有的数据,并将数据写入缓存中,如果缓存不足则将数据按partition&key排序后spill到磁盘上,返回排序好的iterator。在真正要遍历排好序的iterator时,会使用堆排序对每个spill文件的每个partition的第一个元素按key进行排序,依次返回堆顶的数据,并向堆中填充对应spill文件的partition中的下一个数据)。
也就是说,如果rdd需要进行聚合/排序,则在reduce阶段,需要首先从集群获取到所需要的全量数据,然后写入本地缓存中(缓存不够刷磁盘),然后才能进行聚合/排序,之后再返回给调用者处理好的iterator。即在需要聚合、排序时,都需要写磁盘(如果存在spill情况),都需要先将map的数据落盘,才能返回给调用者进行操作,在调用者对返回的iterator进行遍历时,才使用堆排对数据进行聚合/排序。如果rdd不需要进行排序/聚合,则直接将初始的iterator包装后返回给调用者,当调用者对返回的iterator遍历时,才真正从集群中获取数据,即边处理边fetch。
read
主要用来获取并返回需要的map数据经过处理后的iterator。首先通过新建ShuffleBlockFecherIterator实例得到可以从集群获取需要的map数据。如果当前rdd需要聚合,则调用聚合方法对iterator中的数据按key进行聚合,并返回iterator。如果当前rdd需要排序,则调用排序方法对iterator中的数据按key进行排序,并返回排好序的iterator。
// 读取当前reduce任务需要的键值对集合
override def read(): Iterator[Product2[K, C]] = {
// 获取数据块的遍历器
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024,
SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue))
// 根据配置的压缩方法包装流
val wrappedStreams = blockFetcherItr.map { case (blockId, inputStream) =>
serializerManager.wrapForCompression(blockId, inputStream)
}
val serializerInstance = dep.serializer.newInstance()
// 对每一个流创建一个key/value遍历器
val recordIter = wrappedStreams.flatMap { wrappedStream =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// 将流包装成带指标统计的流
val readMetrics = context.taskMetrics.createTempShuffleReadMetrics()
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// 将流包装为可中断的流
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
// 如果定义了聚合函数,则进行聚合
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
// 如果map阶段做了聚合,则使用agregator中的聚合方法对所有的map结果做一次聚合
if (dep.mapSideCombine) {
// We are reading values that are already combined
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// 如果map阶段没有聚合,则根据key对数据聚合
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
// 如果不需要聚合,则直接返回iterator
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// 如果定义了排序函数,则进行排序
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// 使用ExternalSorter对数据进行排序
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
// 将聚合好的iterator插入sorter缓存中,如果缓存达到上限则将缓存内容刷新到磁盘上
// 在刷新时,对缓存中的记录按照分区,key进行排序,并最终保存到磁盘spill文件中
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
// 调用sorter的iterator方法,读取记录,其中如果记录在缓存和spill文件中都存在,
// 由于每个spill文件都是有序的,则使用堆排的方法,返回按分区&key排好序的iterator
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
aggregatedIter
}
}
ShuffleBlockFetcherIterator
BlockStoreShuffleReader实际使用ShuffleBlockFecherIterator来从集群中获取map任务输出的中间结果。map的中间结果可能存在本地,也可能存在集群的其他节点上。对于本地的数据块,直接从本地的BlockManager获取,对于远端的数据块,通过BlockTransferService从网络获取。
对于远端数据块的获取,限制了其缓存大小。每次只能最多获取指定内存大小的数据,并保存在内存中。当数据真正被遍历后,才能继续从远端获取数据。对于本地的数据块获取,由于数据本来就存在本地,这里只是返回了一个对数据块所在位置的引用,不需要缓存。
initialize
初始化ShuffleBlockFetcherIterator。初始化时,会向远端节点发送请求获取数据,并保存到本地缓存中,等待调用者遍历iterator时使用。
private[this] def initialize(): Unit = {
context.addTaskCompletionListener(_ => cleanup())
// 将本地块和远端块分开,对于远端块返回请求
val remoteRequests = splitLocalRemoteBlocks()
// 将请求随机放入队列中
fetchRequests ++= Utils.randomize(remoteRequests)
assert ((0 == reqsInFlight) == (0 == bytesInFlight),
"expected reqsInFlight = 0 but found reqsInFlight = " + reqsInFlight +
", expected bytesInFlight = 0 but found bytesInFlight = " + bytesInFlight)
// 发送请求
fetchUpToMaxBytes()
val numFetches = remoteRequests.size - fetchRequests.size
logInfo("Started " + numFetches + " remote fetches in" + Utils.getUsedTimeMs(startTime))
// 获取本地数据块
fetchLocalBlocks()
logDebug("Got local blocks in " + Utils.getUsedTimeMs(startTime))
}
fetchUpToMaxBytes & sendRequest
从远端获取数据的方法。fetchUpToMaxBytes会判断当前是否有fetchRequest队列中是否存在想要获取远端数据的请求,并检查当前缓存是否足够。如果都满足,则调用sendRequest方法实际从远端获取数据。
private def fetchUpToMaxBytes(): Unit = {
// Send fetch requests up to maxBytesInFlight
// 如果请求队列不空,且使用内存大小小于maxBytesInFlight,则发送请求
while (fetchRequests.nonEmpty &&
(bytesInFlight == 0 ||
(reqsInFlight + 1 <= maxReqsInFlight &&
bytesInFlight + fetchRequests.front.size <= maxBytesInFlight))) {
sendRequest(fetchRequests.dequeue())
}
}
/**
* 向远端请求数据块,如果成功将数据则会调用BlockFetchingListener,将buf中的数据包装为
* SuccessFetchResult
*
* @param req
*/
private[this] def sendRequest(req: FetchRequest) {
logDebug("Sending request for %d blocks (%s) from %s".format(
req.blocks.size, Utils.bytesToString(req.size), req.address.hostPort))
bytesInFlight += req.size
reqsInFlight += 1
// so we can look up the size of each blockID
val sizeMap = req.blocks.map { case (blockId, size) => (blockId.toString, size) }.toMap
val remainingBlocks = new HashSet[String]() ++= sizeMap.keys
val blockIds = req.blocks.map(_._1.toString)
val address = req.address
// 使用ShuffleClient从远端获取数据。
shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,
new BlockFetchingListener {
override def onBlockFetchSuccess(blockId: String, buf: ManagedBuffer): Unit = {
// Only add the buffer to results queue if the iterator is not zombie,
// i.e. cleanup() has not been called yet.
ShuffleBlockFetcherIterator.this.synchronized {
if (!isZombie) {
// Increment the ref count because we need to pass this to a different thread.
// This needs to be released after use.
buf.retain()
remainingBlocks -= blockId
// 将数据放到results缓存中
results.put(new SuccessFetchResult(BlockId(blockId), address, sizeMap(blockId), buf,
remainingBlocks.isEmpty))
logDebug("remainingBlocks: " + remainingBlocks)
}
}
logTrace("Got remote block " + blockId + " after " + Utils.getUsedTimeMs(startTime))
}
override def onBlockFetchFailure(blockId: String, e: Throwable): Unit = {
logError(s"Failed to get block(s) from ${req.address.host}:${req.address.port}", e)
results.put(new FailureFetchResult(BlockId(blockId), address, e))
}
}
)
}
next
当调用者遍历ShuffleBlockFetcherIterator时,会调用next方法。这个方法会返回缓存的数据。如果获取的数据来自远端,则从远端再次获取数据并放入缓存。
/**
* 遍历block,如果当前遍历的block来自远端,则更新相关的值(bytesInFlight,reqsInFlight)
* 并调用fetchUpToMaxBytes来读取请求队列中的排队请求,继续从远端获取数据块。如果是本地
* 数据块,则不更新相关值。
*
* 最终返回blockId和对应的inputStream
*
*/
override def next(): (BlockId, InputStream) = {
numBlocksProcessed += 1
val startFetchWait = System.currentTimeMillis()
currentResult = results.take()
val result = currentResult
val stopFetchWait = System.currentTimeMillis()
shuffleMetrics.incFetchWaitTime(stopFetchWait - startFetchWait)
result match {
case SuccessFetchResult(_, address, size, buf, isNetworkReqDone) =>
if (address != blockManager.blockManagerId) {
shuffleMetrics.incRemoteBytesRead(buf.size)
shuffleMetrics.incRemoteBlocksFetched(1)
}
bytesInFlight -= size
if (isNetworkReqDone) {
reqsInFlight -= 1
logDebug("Number of requests in flight " + reqsInFlight)
}
case _ =>
}
// Send fetch requests up to maxBytesInFlight
fetchUpToMaxBytes()
result match {
case FailureFetchResult(blockId, address, e) =>
throwFetchFailedException(blockId, address, e)
case SuccessFetchResult(blockId, address, _, buf, _) =>
try {
(result.blockId, new BufferReleasingInputStream(buf.createInputStream(), this))
} catch {
case NonFatal(t) =>
throwFetchFailedException(blockId, address, t)
}
}
}