转载自 https://zhuanlan.zhihu.com/p/100419971
如何确定神经网络的层数和隐藏层神经元数量
一、导语
BP神经网络主要由输入层、隐藏层、输出层构成,输入和输出层的节点数是固定的,不论是回归还是分类任务,选择合适的层数以及隐藏层节点数,在很大程度上都会影响神经网络的性能。
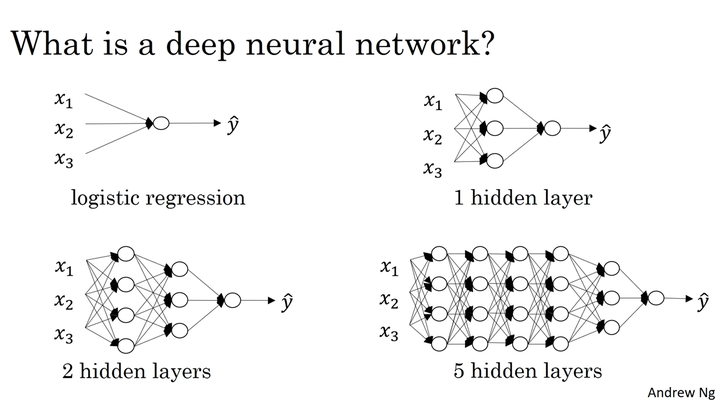 图源:吴恩达-深度学习
图源:吴恩达-深度学习
输入层和输出层的节点数量很容易得到。输入层的神经元数量等于待处理数据中输入变量的数量,输出层的神经元的数量等于与每个输入关联的输出的数量。但是真正的困难之处在于确定合适的隐藏层及其神经元的数量。
二、隐藏层的层数
如何确定隐藏层的层数是一个至关重要的问题。首先需要注意一点:
在神经网络中,当且仅当数据非线性分离时才需要隐藏层!
Since a single sufficiently large hidden layer is adequate for approximation of most functions, why would anyone ever use more? One reason hangs on the words “sufficiently large”. Although a single hidden layer is optimal for some functions, there are others for which a single-hidden-layer-solution is very inefficient compared to solutions with more layers.
——Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks, 1999
因此,对于一般简单的数据集,一两层隐藏层通常就足够了。但对于涉及时间序列或计算机视觉的复杂数据集,则需要额外增加层数。单层神经网络只能用于表示线性分离函数,也就是非常简单的问题,比如分类问题中的两个类可以用一条直线整齐地分开。
Specifically, the universal approximation theorem states that a feedforward network with a linear output layer and at least one hidden layer with any “squashing” activation function (such as the logistic sigmoid activation function) can approximate any Borel measurable function from one finite-dimensional space to another with any desired non-zero amount of error, provided that the network is given enough hidden units.
——Deep learning, 2016
概括来说就是多个隐藏层可以用于拟合非线性函数。
隐藏层的层数与神经网络的效果/用途,可以用如下表格概括:
 图源:
图源:
简要概括一下——
- 没有隐藏层:仅能够表示线性可分函数或决策
- 隐藏层数=1:可以拟合任何“包含从一个有限空间到另一个有限空间的连续映射”的函数
- 隐藏层数=2:搭配适当的激活函数可以表示任意精度的任意决策边界,并且可以拟合任何精度的任何平滑映射
- 隐藏层数>2:多出来的隐藏层可以学习复杂的描述(某种自动特征工程)
Empirically, greater depth does seem to result in better generalization for a wide variety of tasks. This suggests that using deep architectures does indeed express a useful prior over the space of functions the model learns.
——Deep learning, 2016
层数越深,理论上拟合函数的能力增强,效果按理说会更好,但是实际上更深的层数可能会带来过拟合的问题,同时也会增加训练难度,使模型难以收敛。因此我的经验是,在使用BP神经网络时,最好可以参照已有的表现优异的模型,如果实在没有,则根据上面的表格,从一两层开始尝试,尽量不要使用太多的层数。在CV、NLP等特殊领域,可以使用CNN、RNN、attention等特殊模型,不能不考虑实际而直接无脑堆砌多层神经网络。尝试迁移和微调已有的预训练模型,能取得事半功倍的效果。
 图源:beginners-ask-how-many-hidden-layers-neurons-to-use-in-artificial-neural-networks
图源:beginners-ask-how-many-hidden-layers-neurons-to-use-in-artificial-neural-networks
确定隐藏的神经元层的数量只是问题的一小部分。还需要确定这些隐藏层中的每一层包含多少个神经元。下面将介绍这个过程。
三、隐藏层中的神经元数量
在隐藏层中使用太少的神经元将导致欠拟合(underfitting)。相反,使用过多的神经元同样会导致一些问题。首先,隐藏层中的神经元过多可能会导致过拟合(overfitting)。当神经网络具有过多的节点(过多的信息处理能力)时,训练集中包含的有限信息量不足以训练隐藏层中的所有神经元,因此就会导致过拟合。即使训练数据包含的信息量足够,隐藏层中过多的神经元会增加训练时间,从而难以达到预期的效果。显然,选择一个合适的隐藏层神经元数量是至关重要的。
 图源:吴恩达-深度学习
图源:吴恩达-深度学习
通常,对所有隐藏层使用相同数量的神经元就足够了。对于某些数据集,拥有较大的第一层并在其后跟随较小的层将导致更好的性能,因为第一层可以学习很多低阶的特征,这些较低层的特征可以馈入后续层中,提取出较高阶特征。
需要注意的是,与在每一层中添加更多的神经元相比,添加层层数将获得更大的性能提升。因此,不要在一个隐藏层中加入过多的神经元。
对于如何确定神经元数量,有很多经验之谈。
stackoverflow上有大神给出了经验公式以供参考:
其中:是输入层神经元个数;
是输出层神经元个数;
是训练集的样本数;
α 是可以自取的任意值变量,通常范围可取 2-10。
还有另一种方法可供参考,神经元数量通常可以由一下几个原则大致确定:
- 隐藏神经元的数量应在输入层的大小和输出层的大小之间。
- 隐藏神经元的数量应为输入层大小的2/3加上输出层大小的2/3。
- 隐藏神经元的数量应小于输入层大小的两倍。
总而言之,隐藏层神经元是最佳数量需要自己通过不断试验获得,建议从一个较小数值比如1到5层和1到100个神经元开始,如果欠拟合然后慢慢添加更多的层和神经元,如果过拟合就减小层数和神经元。此外,在实际过程中还可以考虑引入Batch Normalization, Dropout, 正则化等降低过拟合的方法。
参考资料:
- LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning."nature521.7553 (2015): 436-444.
- Heaton Research: The Number of Hidden Layers
- Ahmed Gad, Beginners Ask “How Many Hidden Layers/Neurons to Use in Artificial Neural Networks?”
- Jason Brownlee, How to Configure the Number of Layers and Nodes in a Neural Network
- Lavanya Shukla, Designing Your Neural Networks