目录
hashtable
将一系列数放入容器中,将数除以内存的大小M,得到的余数挂在每个篮子下面。篮子的个数M一般取质数,当篮子所挂的链表长度大于篮子个数M时,就要rehashing,扩充篮子的数量(vector二倍扩充,不过扩充以后选取2*M附近的质数)
开链法
hashtable的桶子(buckets)与节点(nodes)
hash table表格内的元素为桶子(bucket),此名称的大约意义是:表格内的每个单元,涵盖的不只是个节点(元素),甚至可能是一桶节点。
haah table的图示
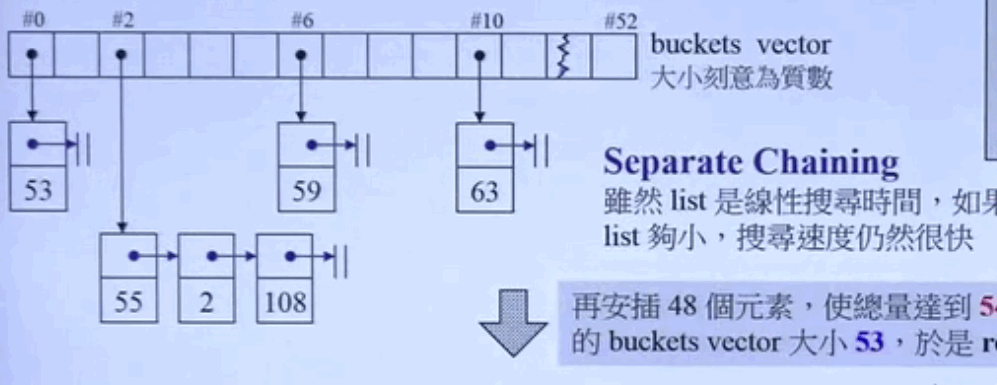
buckets vector大小为任意常数,虽然list是线性搜寻时间,如果list够小,搜寻速度仍然很快。
GC编译器将bucket的个数设置为53,当桶中元素的个数大于bucket的个数时,就需要对放置桶的vector进行扩容,我们可以使用hashtable iterators改变元素的data,但不能改变元素的key.
hashtable实现
- HashFcn : 是hash函数
- ExtractKey: 插入的元素是一包东西,可能是一个pair,必须要告诉如何取出这个key
- EqualKey: 如何对key进行判等
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey,
class Alloc = alloc>
class hashtable {
public:
typedef HashFcn hasher; //hash函数
typedef EqualKey key_equal; //判等函数
typedef size_t size_type;
private:
hasher hash; //大小为0,但是实际值为1
key_equal equals;//大小为0,但是实际值为1
ExtractKey get_key;//大小为0,但是实际值为1
typedef __hashtable_node<Value>node;
vector<node*, Alloc>buckets; // vector里有三个指针,大小为12
size_type num_elements;//4个字节
public:
size_type bucket_count() const { return bucket.size(); }
};
- hashtable总共大小是19个字节,调整为4的倍数,一共是20个字节。
hashtable的节点实现
其中node节点的设置如下:
template<class Value>
struct __hashtable_node {
__hashtable_node * next;
Value val;
};
除了需要保存数据本身之外,还需要一个指针去指向下一个元素。
hashtable的迭代器实现
struct __hashtable_iterator {
node* cur;
hashtable* ht;
};
hashfunction的设计
hashfunction的目的是:希望能够根据元素的值计算出一个hashcode,使得元素经过hash code映射之后,能够被随机的放置于hashtable中,越是够乱,越不容易产生碰撞。