概述
通过上一篇文章的分析,我们知道了pager模块在整个sqlite中所处的位置。它是sqlite的核心模块,充当了多种重要角色。作为一个事务管理器,它通过并发控制和故障恢复实现事务的ACID特性,负责事务的原子提交和回滚;作为一个页管理器,它处理从文件中读写数据页,并执行文件空间管理工作;作为日志管理器,它负责写日志记录到日志文件;作为锁管理器,它确保事务在访问数据页之前,一定先对数据文件上锁,实现并发控制。本质上来说,pager模块实现了存储的持久性和事务的原子性。从图1中我们可以看到pager模块主要由4个子模块组成:事务管理模块,锁管理模块,日志模块和缓存模块。而事务模块的实现依赖于其它3个子模块。因此pager模块最核心的功能实质是由缓存模块、日志管理器和锁管理器完成。Tree模块是pager模块的上游,Tree模块在访问数据文件前,需要创建一个pager对象,通过pager对象来操作文件。pager模块利用pager对象来跟踪文件锁相关的信息,日志状态,数据库状态等。对于同一个文件,一个进程可能有多个pager对象;这些对象之间都是相互独立的。对于共享缓存模式,每个数据文件只有一个pager对象,所有连接共享这个pager对象。
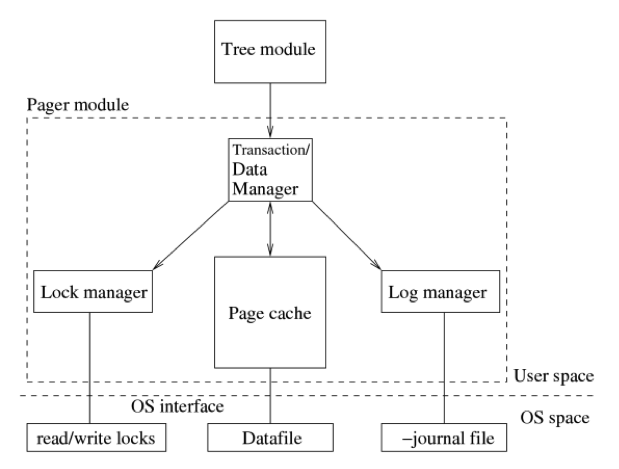
图1
缓存模块
这里谈到的缓存管理,实际上就是page cache模块。应用程序访问数据库文件时,pager模块会以块为单位进行缓存,每一个连接都有自己独有的pager模块,因此每个连接都有自己独有的缓存。
1.缓存锁状态
文件的页面缓存初始化时,pager模块处于NO_LOCK状态。BTREE模块第一次调用sqlite3PagerGet从数据文件中读取页面时,pager状态转换为SHARED_LOCK状态。当Tree模块调用sqlite3PagerUnref释放页面时,pager状态重新回到NO_LOCK状态。当ree模块第一次调用sqlite3PagerWrite访问页面时,pager状态变为RESERVED_LOCK状态。要注意的是,调用sqlite3PagerWrite访问的页面,一定是之前被读过的页面,pager状态是从SHARED_LOCK转换到RESERVED_LOCK状态。在向数据文件页写入之前,pager模块转换到EXECLUSIVE_LOCK状态,事务提交sqlite3BtreeCommitPhaseTwo或回滚sqlite3PagerRollback时,pager模块回到NO_LOCK状态。
2.缓存组织
如图2所示,缓存其实是由一个hash表和多个链表组成。Pager模块访问页面时,首先以页号为key,在hash表中查找,迅速确定所需的页面是否在缓存。建立hash表时,若出现多个页号映射在同一个桶,则通过链表链接起来。除了hash表,缓存组织还包括一个LRU链表和DIRTY链表,分别用于缓存替换和缓存刷脏。
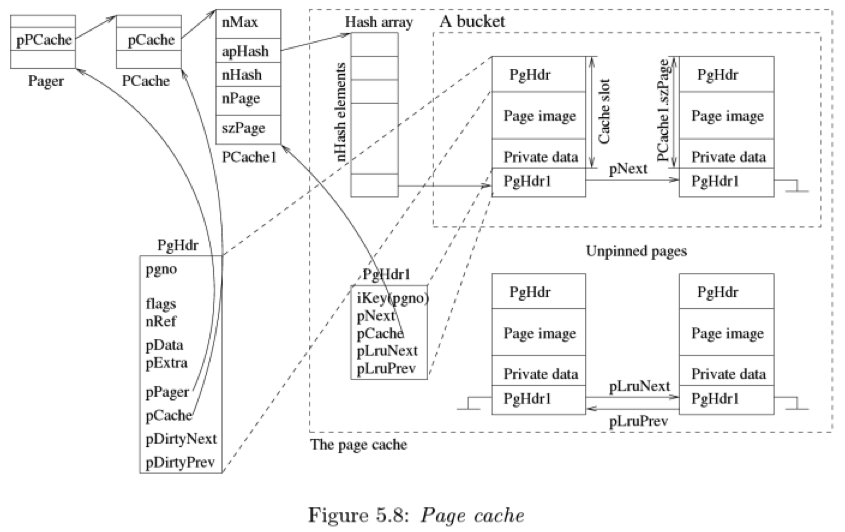
图2
3.缓存策略
sqlite并不像有些数据库有预取机制,可能是为了简单,也可能是因为sqlite主要用于端设备,本身缓存就比较少。因此,只有在上层模块需要指定的页时,才从文件中读取到缓存中。由于缓存是一定的,并且一般情况下小于数据库文件容量,所以一定会存在缓存替换的问题。sqlite采用LRU算法,基本上主流的关系型数据库都采用这种算法。LRU(least recent used),通过将过去一段时间页面的访问来预测未来页面的访问。意思就是,如果一个页面现在被访问,就可以认为这个页面很有可能会被再次访问;如果一个页面在过去一段时间内很久都没有被访问,则可以认为该页在未来一段时间内也不会被访问。那么当缓存池满时,则选择最近最少被访问的页面替换。如果选择被替换的页是脏页,在替换出缓存之前,需要将先将被替换的页写入数据文件(这时候脏页对应的old-page需要先刷入日志文件)。我们知道缓存中的脏页刷盘后才算真正写入文件,那么缓存中的脏页何时刷盘?sqlite不提供刷脏页接口,因此用户不能主动触发刷page(写datafile)操作,这个操作由pager模块在特定情况下触发。主要有两种情况:缓存的page数量已经超过了page_size;另外一种情况是,事务在提交过程中。
4.核心流程
读取一个page的过程(假设页号为P)
(1).在page cache中查找
通过页号,在hash表中搜索,定位到指定的桶,然后通过PgHdr1.pNext逐个比较是否是需要的页。如果找到,则将PgHdr.nRef加1,并将页面返回给上层调用模块。
(2).如果在page cache中没有找到,则获取一个空闲的slot,或者直接新建一个slot,只要不超过slot的阀值PCache1.nMax即可。
(3).如果没有可用的slot,则选择一个可以重用的slot(slot对应的页面需要释放,通过LRU算法)
(4).如果选择重用的slot对应的page是脏页,则将该页写入文件(对于wal,刷脏页前,先将脏页写入日志文件)
(5).加载page
如果页号P对应的偏移小于文件的大小,从文件读入page到slot,设置PgHdr.nRef为1,返回;如果页号P对应的偏移大于当前文件大小,则将slot中内容初始化为0,同样将PgHdr.nRef设置为1。
更新page的过程
这里假设page已经读取到内存中。Tree模块往page写入数据之前,需要调用sqlite3PagerWrite函数,使得一个page变为可写的状态,否则pager模块不知道这个page需要被修改。pager模块在数据文件上加一个reserved锁,并创建一个日志文件。如果加锁失败,则返回SQLITE_BUSY错误。它将page的原始信息拷贝到日志文件,如果日志文件中之前已经存在该page,则不进行拷贝动作,而只是将page标记为dirty。当page被写入文件后,dirty标记会被清除。
5.缓存一致性
从前面的讨论知道,每个连接都有一份自己的缓存。对于共享缓存模式而言,同一个进程的多个线程公用一份缓存。那么连接之间的缓存如何保证一致性?比如有Connection1和Connection2两个连接,Connection1首先从文件中读取了page_A并加入到了缓存;随后Connection2也从文件中读取Page_A,并进行了更新;那么当Connection1再次读取page_A时,Connection1如何知道自己缓存的page_A已经不是最新了,需要重新到DB文件中读取?
SQLite当然考虑到这个问题,在SQLite DB的文件控制头中存储了DB的版本信息。每当会话执行SQL时,会首先加共享锁,并读取DB数据的版本信息(4个字节)并缓存起来,如果发现这次读取的DB版本信息与之前缓存的DB数据版本信息有变(表示DB文件被修改了),则清理自身的缓存,清理缓存的接口是pager_reset。当会话再次请求已经发生变化的page时,会重新到DB文件中读取,保证读取到最新。至于DB的数据版本信息,每次事务提交时,会调用pager_write_changecounter进行更新,并持久化到DB文件头。
由于这种实现方式,导致更新频繁的系统,每次读都会清空缓存,导致大量的请求实际还是需要请求DB文件。SQLite提供的共享缓存模式,使得多个会话可以共享一份缓存,就不存在所谓的清理缓存了,从这个层面来看,共享缓存除了可以节省内存空间,还可以提高缓存的命中率,尤其是对于多会话的场景。
日志管理器
1.写日志策略
目前数据库日志主要用两种方式:第一种是WAL(Write Ahead Logging),另外一种是影子分页技术(Shadow paging)。sqlite分别实现了这两种日志方式来保证事务的ACID特性,可以通过参数journal_mode来控制日志模式,默认情况下采用影子分页技术。影子分页模式下,每个page只在日志文件中存一份,无论这个页被修改过多少次。日志文件中,只记录事务开始前page的原始信息,进行恢复时,只需要利用日志文件中的page进行覆盖即可。对于新生成的页,日志中不会记录,而是在日志头记录事务开始时数据文件page的数目,进行恢复时,只需要截断数据文件即可,不需要新页的数据,况且新页本来就没有任何数据。
2. Shadow paging
(1).将old-page写入日志文件,并fsync
(2).修改日志头,更新日志记录数,并fsync,这个值初始为0
(3).在数据文件上获取EXECLUSIVE lock,如果此时还有读事务,则报SQLITE_BUSY错误
(4).将dirty-page写入日志文件,并将这些cache标记为clean,表示可以重用如果是因为cache满了,导致需要写datafile操作,由于用户没有发起事务提交,因此pager模块也不会提交事务。
pager模块重复上述的1,2,3,4点,直到事务提交。为了避免事务提交前,其他事务读到脏数据,因此在进行刷脏页时,需要在文件上EXECLUSIVE lock,那么直到事务提交前,这个EXECLUSIVE lock都不会释放,导致这种情况下,所有其它读、写事务都被堵塞。因此,大事务会降低整体的并发性能。
锁管理器
sqlite的并发控制靠封锁实现,依据两阶段锁协议,保证事务的ACID。Sqlite的并发控制依赖于文件锁,通过锁文件的特定的区域,实现互斥。Sqlite主要包含4种锁,SHARED_LOCK(共享锁),(RESERVED_LOCK)保留锁,(PENDING_LOCK)未决锁和(EXCLUSIVE_LOCK)排它锁,其中共享锁与排它锁在文件的同一片区域。RESERVED_LOCK主要用于写写互斥,PENDING_LOCK则主要用于读写互斥,并有延缓互斥的作用。关于锁并发详细可以看sqlite封锁机制。

图3
关键接口
sqlite3PagerCommitPhaseOne //提交事务第一阶段:文件修改计数器增1,将日志文件刷入磁盘,将事务修改的脏页刷入磁盘。
sqlite3PagerCommitPhaseTwo //提交事务的第二阶段:删除日志文件,释放锁
sqlite3PagerRollback //回滚事务:回滚事务在数据文件的修改,将排它锁降级为共享锁,所有缓存页面还原到修改之前的状态,删除日志文件。
pcache1ResizeHash【扩展hash】 //最大缓存2000个page,LRU链表,插入队头,从队尾删除
setSharedCacheTableLock //table-lock接口
pagerLockDb //文件锁接口
walLockShared wal //文件共享读锁接口
walLockExclusive wal //文件排它锁接口
sqlite3PagerAcquire //获取某一页
readDbPage //读取page
pcache1FetchNoMutex //查找cache
pcache1FetchStage2 //添加cache
pcache1RemoveFromHash //移除cache
参考文档
SQlite Database System Design and Implementation