高并发服务端分布式系统设计概要(中)
上篇(链接)我们完成了在此分布式系统中,一个group的设计。那么接下来,我们设计系统的其他部分。如前文所述,我们的业务及其数据以group为单位,显然在此系统中将存在many many的groups(别告诉我你的网站总共有一个业务,像我们的“山推”,那业务是一堆一堆地),那么由谁来管理这些groups呢?由Web过来的请求,又将如何到达指定的group,并由该group处理它的请求呢?这就是我们要讨论的问题。
我们引入了一个新的角色——Global Master,顾名思义,它是管理全局的一个节点,它主要完成如下工作:(1)管理系统全局配置,发送全局控制信息;(2)监控各个group的工作状态,提供心跳服务,若发现宕机,通知该group发起分布式选举产生新的Group Master;(3)处理Client端首次到达的请求,找出负责处理该请求的group并将此group的信息(location)返回,则来自同一个前端请求源的该类业务请求自第二次起不需要再向Global Master查询group信息(缓存机制);(4)保持和Global Slave的强一致性同步,保持自身健康状态并向全局的“心跳”服务验证自身的状态。
现在我们结合图来逐条解释上述工作,显然,这个系统的完整轮廓已经初现。
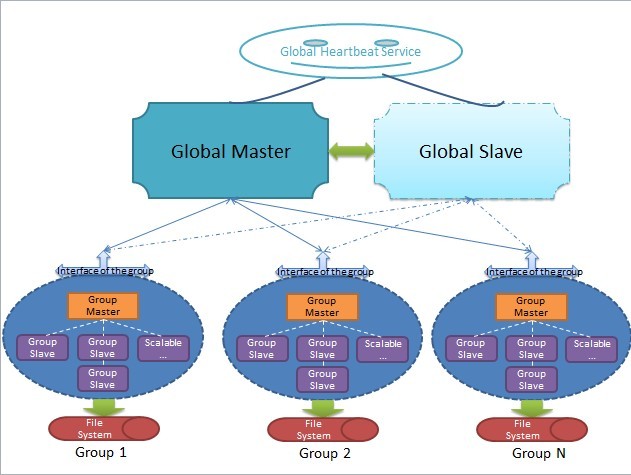
首先要明确,不管我们的系统如何“分布式”,总之会有至少一个最主要的节点,术语可称为primary node,如图所示,我们的系统中,这个节点叫Global Master,也许读过GFS + Bigtable论文的同学知道,在GFS + Bigtable里,这样的节点叫Config Master,虽然名称不一样,但所做的事情却差不多。这个主要的Global Master可认为是系统状态健康的标志之一,只要它在正常工作,那么基本可以保证整个系统的状态是基本正常的(什么?group或其他结点会不正常不工作?前面已经说过,group内会通过“分布式选举”来保证自己组内的正常工作状态,不要告诉我group内所有机器都挂掉了,那个概率我想要忽略它),假如Global Master不正常了,挂掉了,怎么办?显然,图中的Global Slave就派上用场了,在我们设计的这个“山推”系统中,至少有一个Global Slave,和Global Master保持“强一致性”的完全同步,当然,如果有不止一个Global Slave,它们也都和Global Master保持强一致性完全同步,这样有个好处,假如Global Master挂掉,不用停写服务,不用进行分布式选举,更不会读服务,随便找一个Global Slave顶替Global Master工作即可。这就是强一致性最大的好处。那么有的同学就会问,为什么我们之前的group,不能这么搞,非要搞什么最终一致性,搞什么分布式选举(Paxos协议属于既难理解又难实现的坑爹一族)呢?我告诉你,还是压力,压力。我们的系统是面向日均千万级PV以上的网站(“山推”嘛,推特是亿级PV,我们千万级也不过分吧),但系统的压力主要在哪呢?细心的同学就会发现,系统的压力并不在Global Master,更不会在Global Slave,因为他们根本不提供数据的读写服务!是的,系统的压力正是在各个group,所以group的设计才是最关键的。同时,细心的同学也发现了,由于Global Master存放的是各个group的信息和状态,而不是用户存取的数据,所以它更新较少,也不能认为读>>写,这是不成立的,所以,Global Slave和Global Master保持强一致性完全同步,正是最好的选择。所以我们的系统,一台Global Master和一台Global Slave,暂时可以满足需求了。
好,我们继续。现在已经了解Global Master的大概用途,那么,一个来自Client端的请求,如何到达真正的业务group去呢?在这里,Global Master将提供“首次查询”服务,即,新请求首次请求指定的group时,通过Global Master获得相应的group的信息,以后,Client将使用该信息直接尝试访问对应的group并提交请求,如果group信息已过期或是不正确,group将拒绝处理该请求并让Client重新向Global Master请求新的group信息。显然,我们的系统要求Client端缓存group的信息,避免多次重复地向Global Master查询group信息。这里其实又挖了许多烂坑等着我们去跳,首先,这样的工作模式满足基本的Ddos攻击条件,这得通过其他安全性措施来解决,避免group总是收到不正确的Client请求而拒绝为其服务;其次,当出现大量“首次”访问时,Global Master尽管只提供查询group信息的读服务,仍有可能不堪重负而挂掉,所以,这里仍有很大的优化空间,比较容易想到的就是采用DNS负载均衡,因为Global Master和其Global Slave保持完全同步,所以DNS负载均衡可以有效地解决“首次”查询时Global Master的压力问题;再者,这个工作模式要求Client端缓存由Global Master查询得到的group的信息,万一Client不缓存怎么办?呵呵,不用担心,Client端的API也是由我们设计的,之后才面向Web前端。
之后要说的,就是图中的“Global Heartbeat”,这又是个什么东西呢?可认为这是一个管理Global Master和Global Slave的节点,Global Master和各个Global Slave都不停向Global Heartbeat竞争成为Global Master,如果Global Master正常工作,定期更新其状态并延期其获得的锁,否则由Global Slave替换之,原理和group内的“心跳”一样,但不同的是,此处Global Master和Global Slave是强一致性的完全同步,不需要分布式选举。有同学可能又要问了,假如Global Heartbeat挂掉了呢?我只能告诉你,这个很不常见,因为它没有任何压力,而且挂掉了必须人工干预才能修复。在GFS + Bigtable里,这个Global Heartbeat叫做Lock Service。
中篇就写到这里吧。下篇(链接)将给出完整的系统设计并完结。