深度模型简化_存储压缩和计算加速
文献来源:李皈颖. 深度模型简化:存储压缩和计算加速[D].中国科学技术大学,2018.
摘要:深度模型——泛指各类采用了深度神经网络(Deep Neural Network)的模型,它们往往包含庞大的参数数量和复杂的计算流程,这使得这些模型在计算和存储方面需要消耗大量的资源。故而很多包含深度模型的应用无法布置到资源受限的硬件平台上——计算和存储资源较少且不易扩充的硬件环境(例如:无人机),此时就需要对深度模型进行简化。深度模型简化的目的,是在保持模型精度(具体应用设置的评价指标)的前提下,针对性地加快模型计算速度或是压缩模型存储大小。据此,本文分别针对深度模型的加速和深度模型的压缩进行了相应的研宄。
一、 主要工作
针对深度模型的简化问题,本文研宄了在不同任务和不同类型深度模型上的简化方法。本文研宄的思路是从共性到个性,既首先研宄不限于模型或是任务的方法,然后再针对具体的模型或是任务研宄专门的方法。同时,本文将深度模型的简化划分为压缩和加速两个部分,本文将首先研宄压缩,然后研宄加速。
- 首先,本文探究了如何对深度模型中重要组成部分——深度神经网络进行存储开销的简化.
- 其次,针对神经机器翻译任务,本文研究了在这种特定问题下的深度神经网络模型的存储开销简化问题。
- 最后,针对图像中物体检测任务使用的深度模型,本文研宄了其中非神经网络部分的简化方法。
二、背景知识
2.1 深度模型介绍
- 人工神经网络
- 深度神经网络
- 深度卷积网络
- 基于物体检测的R-CNN
- 基于机器翻译的深度模型
2.2 深度神经网络简化
- 工程性加速
- 参数约减
- 裁剪
- 离散化。缩小数值的取值数量,缩小数值的数值精度或是综合这两者。
- 高维模型降维。用低复杂度的模型去近似原始的高复杂度模型。
三、基于优化的深度模型压缩
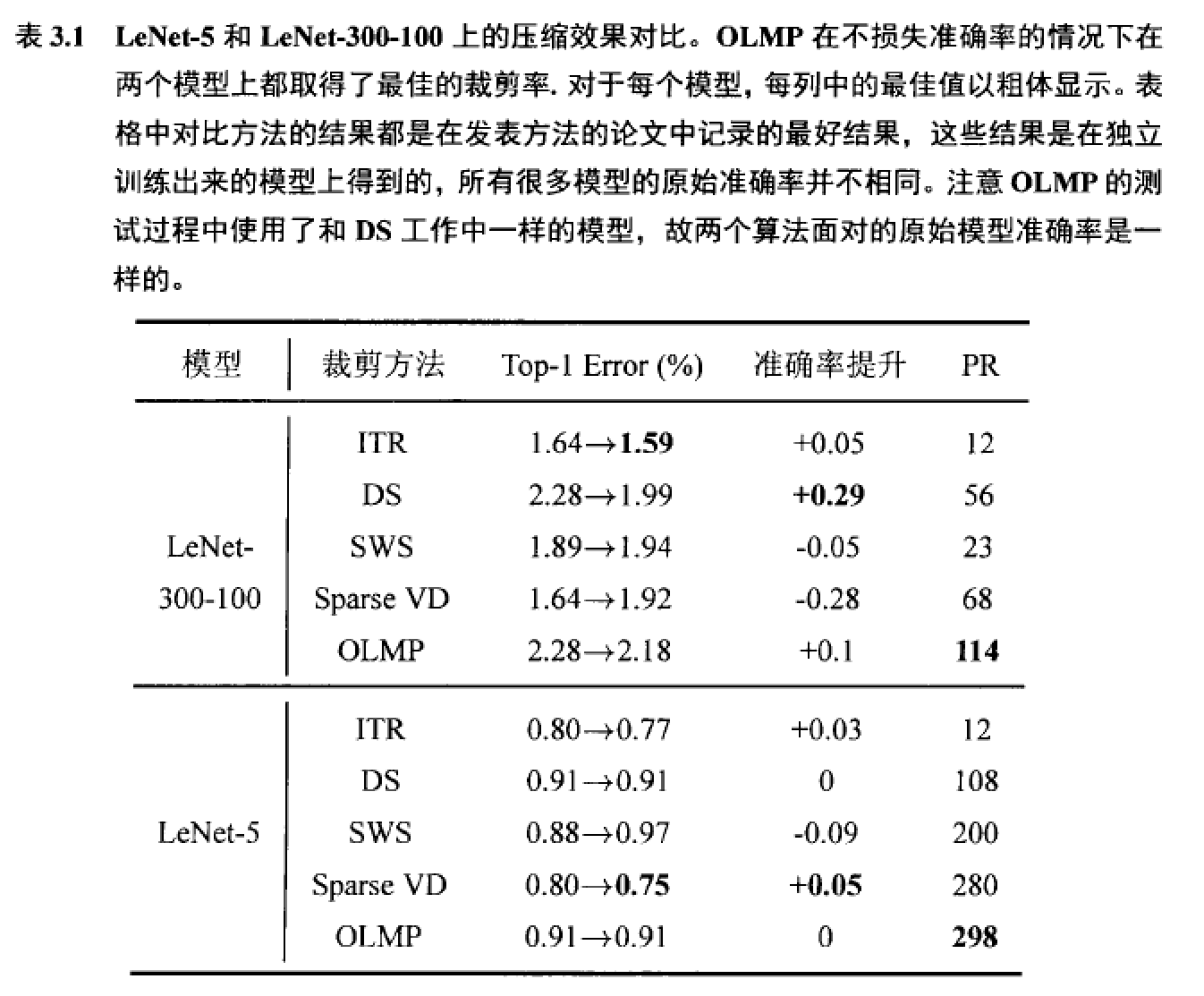
裁剪算法是神经网络参数约减时常用的算法。而在裁剪算法中,逐层依重要度对连接进行裁剪(Layer-wise Magnitude-based Pruning,简称LMP)是一类重要的裁剪算法。LMP算法常用于深度神经网络的压缩过程中,但是调整LMP算法中每层阈值的取值是一项艰巨的任务,因为所有层的阈值取值组合的取值空间是随层数指数变化的;而对每个阈值取值组合,评估它的优劣又需要花费高昂的计算代价。作者提出了一个基于优化算法来自动调节LMP中阈值的方法,该方法被称为Optimization based Layer-wise Magnitude-based Pruning(OLMP)个方法的思想,是将阈值调整问题转换为约束优化问题(即最小化裁剪后模型的大小,同时约束裁剪后的模型精度不低于某个给定的容忍度值),然后使用强有力的非梯度优化算法(负相关搜索NCS)来求解这个优化问题。
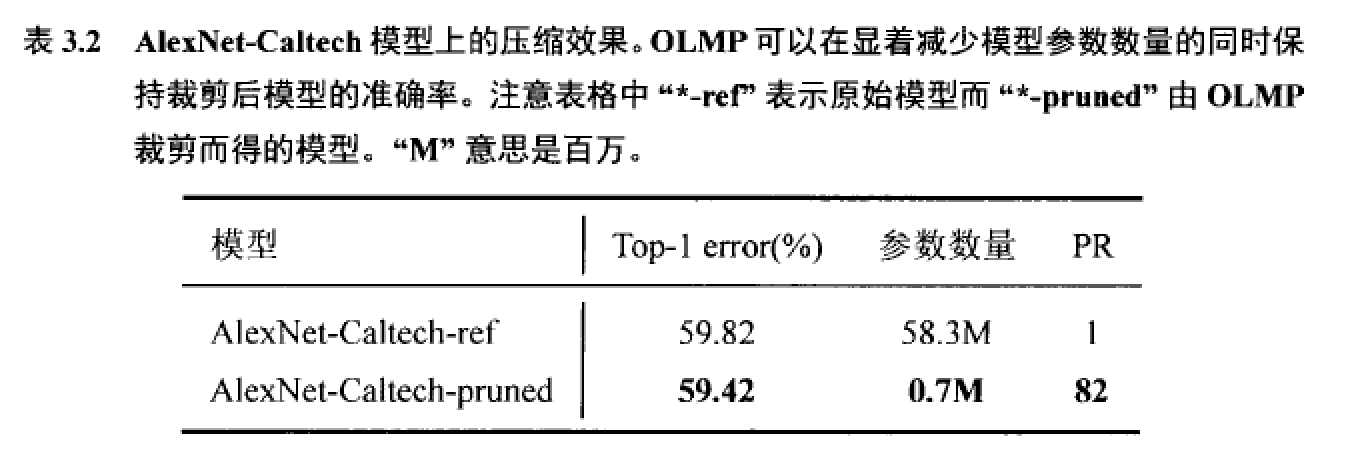
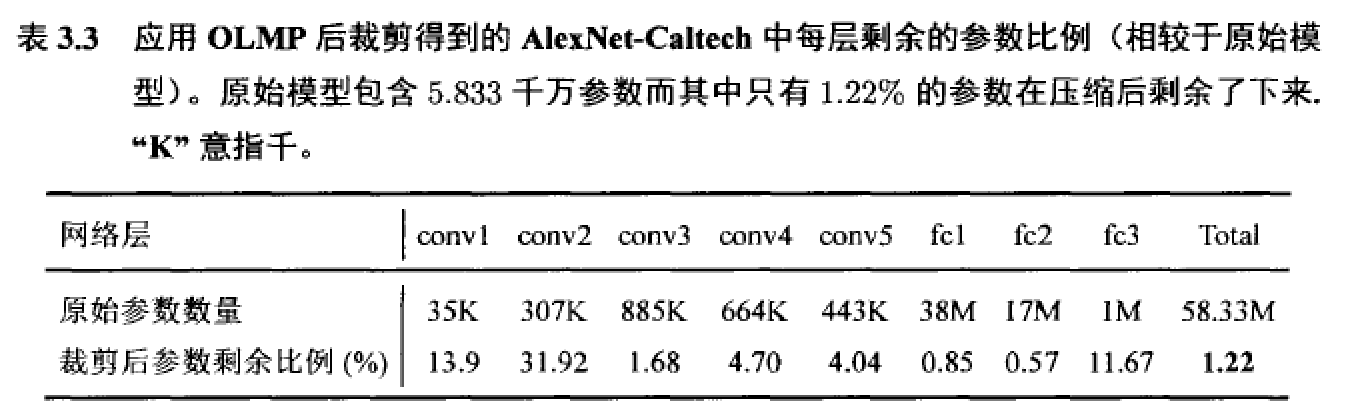
作者首先,第一个实验将OLMP应用于LeNet-5和LeNet-300-100上,并将结果与一些最先进的连接裁剪方法在这两个模型上的结果进行比较。LeNet-5和LeNet-300-100是两个常用于评测裁剪算法性能的神经网络模型。然后,OLMP被用于压缩一个真正的深度神经网络,即名为AlexNet-Caltech的结构类似AlexNet的模型。最后一个实验研宄了在不采用迭代式压缩流程的情况下OLMP的性能。
四、针对机器翻译深度模型的压缩研究
依连接重要性进行裁剪(Magnitude-based Pruning,简称MP)是深度神经网络压缩中一类常用的算法。MP通过裁剪网络中权值绝对值低于给定阈值的连接来简化神经网络。一个广泛使用的MP算法变体是逐层依重要度对连接进行裁剪(LMP)。LMP在很多情况下比MP的压缩结果更好,因为MP不考虑DNN的结构特点,这可能导致关键连接被删去。
除了MP类的压缩算法外,还有研究工作采用其他方法来压缩NMT模型。比如说知识蒸馈的技术(knowledge distillation)以一个训练好的NMT(神经机器翻译)模型为基础来训练产生一个更小的NMT模型。工作以一个训练好的NMT模型为起始模型,通过添加正则项的重训练过程来产生一个更稀疏的模型。作者以三个经典的NMT模型:Luong-Net, RNNSearch和Transformer为基础研究了不同连接分组对裁剪结果的影响。Luong-Net和RNNSearch是使用循环神经网络(Recurrent Neural Network,简称RNN)构建的两个经典NMT模型。而Transformer是一个近期被提出的,前馈式NMT模型。它不包含反馈神经连接,但是拥有更为复杂的注意力机制(attention mechanism)
- Time-wise连接分组策略
- Residual-wise连接分组策略
- 分层分组策略
五、针对物体检测深度模型的加速研究
通常有两种加速分类的方法:令CNN本身的计算更快或者令CNN加载RoI的速度更快。其中一种通过简化CNN的计算流程极大地降低CNN本身的计算开销;而fast R-CNN通过在全连接层上进行trancated SVD分解来达到加速分类的目的。对R-CNN中RoI加载过程进行简化的工作中,Pyramid Pooling Network(简称SPPnet )和fast R-CNN是其中最著名的两个方法。SPPnet为传统的CNN模型引入了一个称为spatial pyramid pooling layer的新结构,其位于卷积层和全连接的层之间,它将特征图上由RoI映射而来的大小不一的长方形块变为固定大小的向量,并将这些向量连接起来作为全连接层的输入。注意此时CNN输入的图片为原始图片,不再是RoI。通过新的spatial pyramid pooling layer SPPnet将RoI的加载从图像输入层转移到了CNN的最后卷积层上。因为RoI之间有大量的重叠,如此转移RoI的载入,可以有效地消去因为RoI重叠而带来的卷积层冗余计算,从而加速R-CNN 。SPPnet显然比R-CNN快许多,因为R-CNN需要对每个RoI执行卷积操作,而SPPnet只需要对整个图像执行一次卷积。Faster R-CNN是基于SPPnet的,SPPnet主要是加速R-CNN模型在测试时的速度,而fast R-CNN则通过引入spatial pyramid pooling layer来加速模型的训练过程。它在传统的深度CNN中最后的卷积层和全连接层之间插入一个新的RoI层。RoI层本质上是一个简单的spatial pyramid pooling layer,它将特征图和RoI的位置信息作为输入。对于每个RoI,fast R-CNN具有两个输出:一是RoI在所有类别上的置信度,这是通过一个softmax结果来预测的;另一个是RoI为不同类别时,其应该移动的偏移量,这个预测出的偏移量可以使得RoI更好的定位物体。
(R^2) -CNN的主要贡献是一个新的RoI生成方法,该方法直接从CNN生成的卷积特征中导出RoI。在应用R-CNN时RoI的生成过程是计算瓶颈之一,因为需要生成大量的RoI来定位物体的位置。(R^2)-CNN通过使用CNN生成的特征并基于一些简单原则通过以下四步生成ROI。
- 生成Integrate Feature Map
- 生成Feature Level
- 生成RoI
- Local Search
六、总结
- 提出OLMP模型。该方法将阂值调节问题转化为了一个带约束的单目标优化问题,然后使用强有力的非梯度优化算法来求解这个优化问题,从而得到一组能找到的最优裁剪阂值,并进而得到一个裁剪模型。
- 针对神经机器翻译(NMT)中采用的深度神经网络,研究了如何针对其特点对其进行简化。首次提出了数种连接分组策略(以往只有分层分组策略),并研究了不同分组策略对不同连接结构模型的裁剪效果影响。
- 提出了(R^2)-CNN方法,来快速生成Rols