之前的两篇文章介绍了如何从0开始到搭建好带有JDK的Ubuntu的过程,本来这篇文章是打算介绍搭建伪分布式集群的。但是后来想想反正伪分布式和完全分布式差不多,所幸直接介绍完全分布式了。
如果你想自己搭建伪分布式玩的话,参考:在VMware下安装Ubuntu并部署Hadoop1.2.1分布式环境 - CSDN博客
这一篇主要参考这篇文章:Hadoop2.6.0安装 - 集群(搭建的过程中没截图,大家可以到原博客看)
一、所需的环境和软件:(以下是我们的环境,仅供参考)
1. 操作系统:Windows 10 64位
2. 内存:4G以上(4G 可以搭建,不过虚拟机的运行可能会比较慢,这种情况可以考虑双系统)
3. VMware Workstation 12:VMware-workstation-full-12.5.7-5813279.exe
4. VMware Tools:通过VMware来安装
5. Ubuntu12.04:ubuntu-14.04.5-desktop-amd64.iso,ubuntu-16.04.3-desktop-amd64.iso(团队中两种系统都有人成功,不过高版本的比较顺利)
6. SSH:通过linux命令来安装
7. JDK1.8:jdk-8u11-linux-x64.tar.gz
8. Hadoop2.6.0:hadoop-2.6.0.tar.gz
二、集群的搭建(以三台机器为例子,一台master(主机),两台Slave(从机),在虚拟机的设置中将网络适配改为桥接)
1.为了使得机器间能够互相连通,我们需要修改/etc/hosts文件。
首先我们要知道每一台机器的IP地址:通过 ifconfig 来查看
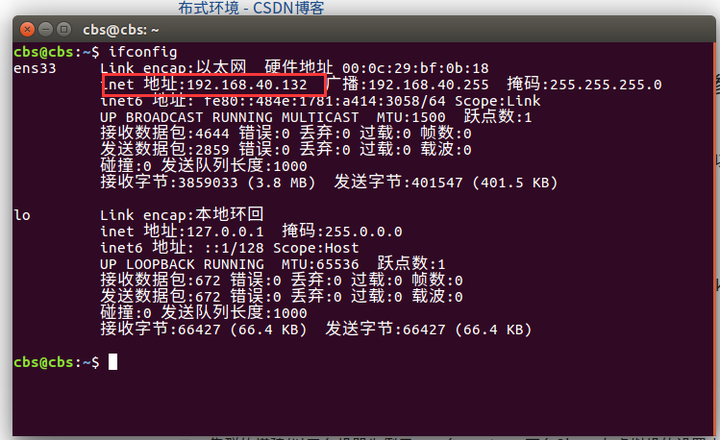
使用ping命令来测试能不能连通其他的机器
ping IP
使用 Ctrl+c来停止
知道了每台主机的IP之后就可以去修改hosts文件了(每一台主机做同样的配置),sudo gedit /etc/hosts
修改成下面的样子
192.168.31.61 Master
192.168.31.29 Slave1
192.168.31.34 Slave2
修改完之后就可以用ping Slave1来测试能否链接。
2、配置SSH登录
配置SSH是为了使得每台机器之间能够通过SSH实现无密码登录
安装ssh:
apt-get install ssh
安装好后生成ssh公钥。
$cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost,生成.ssh目录
$rm ./id_rsa* # 删除之前生成的公匙(如果有)
$ssh-keygen -t rsa # 一直按回车就可以
$cat ./id_rsa.pub >> ./authorized_keys #将公钥加入授权
将Master 上生成的公钥传到各个Slave节点
$scp ~/.ssh/id_rsa.pub hadoop@Slave0:/home/hadoop/
$scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
这里的hadoop是指用户名,如果你集群中的机器名字不一样,就直接改成相应的用户名就行了。
Master将公钥传输到各个节点后,Slave 要将公钥加入授权,这样Master 就能通过ssh免密码登录各台机器了。
$cd ~/.ssh
$cat /home/hadoop/id_rsa.pub >> ./authorized_keys #将Master的公钥加入授权,/home/hadoop/换成自己的目录
每一台Slave机器都完成上述工作后,Master可以使用ssh登录各台主机了。
$ssh Slave1 #登录Slave1,成功的话是不需要密码的,然后$前面的提示信息会变成你登录的那台主机的信息
$ exit #退出登录
注意:如果你的从机用户名和hosts文件里面的Slave1不一样的话,直接ssh Slave1可能会登陆不了。所以这时可以改成:ssh 用户名@Slave1
如果没什么问题的话,就表明ssh操作就是成功了
3、集群xml文件的配置
将Hadoop解压所有机器统一放到同一个目录下。(节点启动是master通过ssh登陆到每一台从机然后在相同的目录启动Hadoop)
配置文件必须要配置的有5个,还有一个可能要配置。
必要的是: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
先说hadoop-env.sh这个文件,为什么是可能呢?因为如果每一台机子的JDK路径不同的话需要在文件中加入JDK路径:
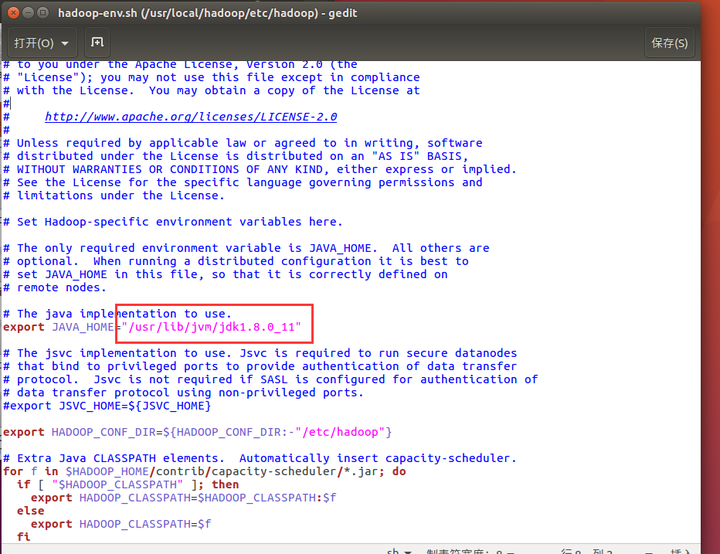
红框部分:你的JDK路径。
slaves文件:
将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。;例如直接将 Slave1 和 Slave2 都加入其中。
core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml文件:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
dfs.replication是hdfs数据块的复制份数一般默认为3,但是这里只有两台机器,所以改为2.
mapred-site.xml 文件(默认文件名为 mapred-site.xml.template,需要将文件名改成mapred-site.xml),然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
ok配置完成
4、对从机的每一台主机做同样的配置
把/usr/local/hadoop文件夹拷贝到每一台从机上面可以用U盘或者远程拷贝
$cd /usr/local
$sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
$sudo rm -r ./hadoop/logs/* # 删除日志文件
$tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
$cd ~
$scp ./hadoop.master.tar.gz Slave0:/home/hadoop
copy结束后,在Slave1和Slave2节点上直接将copy过来的目录解压即可(Master节点需要和Slave节点有相同的配置)。
$sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
$sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
3 $sudo chown -R hadoop /usr/local/hadoop
5、启动Hadoop集群(在Master上启动):
$cd /usr/local/hadoop #你的Hadoop文件夹
$hdfs namenode -format #格式化namenode
$start-dfs.sh #启动hdfs
$start-yarn.sh #启动yarn框架
$mr-jobhistory-daemon.sh start historyserver
然后用JPS查看每个节点的守护进程:
Master节点
 楼主没截图,图片取自原参考博客
楼主没截图,图片取自原参考博客
Slave1
 楼主没截图,图片取自原参考博客
楼主没截图,图片取自原参考博客
Slave2
楼主没截图,图片取自原参考博客
这时可以上web页面查看节点状态
1. 访问 http://localhost:50070 可以查看Hadoop集群的节点数、NameNode及整个分布式系统的状态等(live node是存活几点个数,不为0则成功)。
2. 访问 http://localhost:50030 可以查看JobTracker的运行状态,如Job运行的速度、Map个数、Reduce个数等。
3.访问 http://localhost:8088 可以查看节点状态等
6、停止集群
$stop-yarn.sh
$stop-dfs.sh
$mr-jobhistory-daemon.sh stop historyserver
*备注:遇到问题查看日志文件一个很好的选择
坑:
9000端口:jps显示有datenode,但是livenode为0。9000端口真的是一个很诡异的问题,一度在这里卡了很久。查过很多方法,最后大致是这么解决的:
卸载防火墙:
sudo apt-get remove iptable
/etc/hosts文件做如下改动
127.0.0.1 localhost
127.0.1.1 localhost.localdomain localhost
0.0.0.0 Master
还有的是这样:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.20.77.172 hadoop-master
10.20.77.173 hadoop-slave1
10.20.77.174 hadoop-slave2
10.20.77.175 hadoop-slave3
网上各种版本,我也依旧不是很确定,大家试着吧。
datenode未启动:
将所有机器的hadoop下的tmp文件夹内的东西删掉就好