软工实践第三次作业-结对项目1
简要目录:
- Step1 · 结对信息
成员信息
项目简介
- Step2 · 项目信息
设计说明
原型模型
- Step3 · 结对过程
困难解决
PSP表格
学习进度条
结对照片
- Step4 · 心得总结
蔡宇航
陈柏涛
- Step5 · 附件 PDF
结对信息:
成员信息:
蔡宇航,031602501
陈柏涛,031602502
项目简介:
本项目原型实现对顶会论文的搜索与分析。
基本功能有:
- 每日推荐:根据用户收藏和热门程度推荐相关论文。
- 论文列表:可根据一定条件进行论文检索。
- 流行趋势:对当前热门研究方向和热词等的统计分析,展示直观分析图。
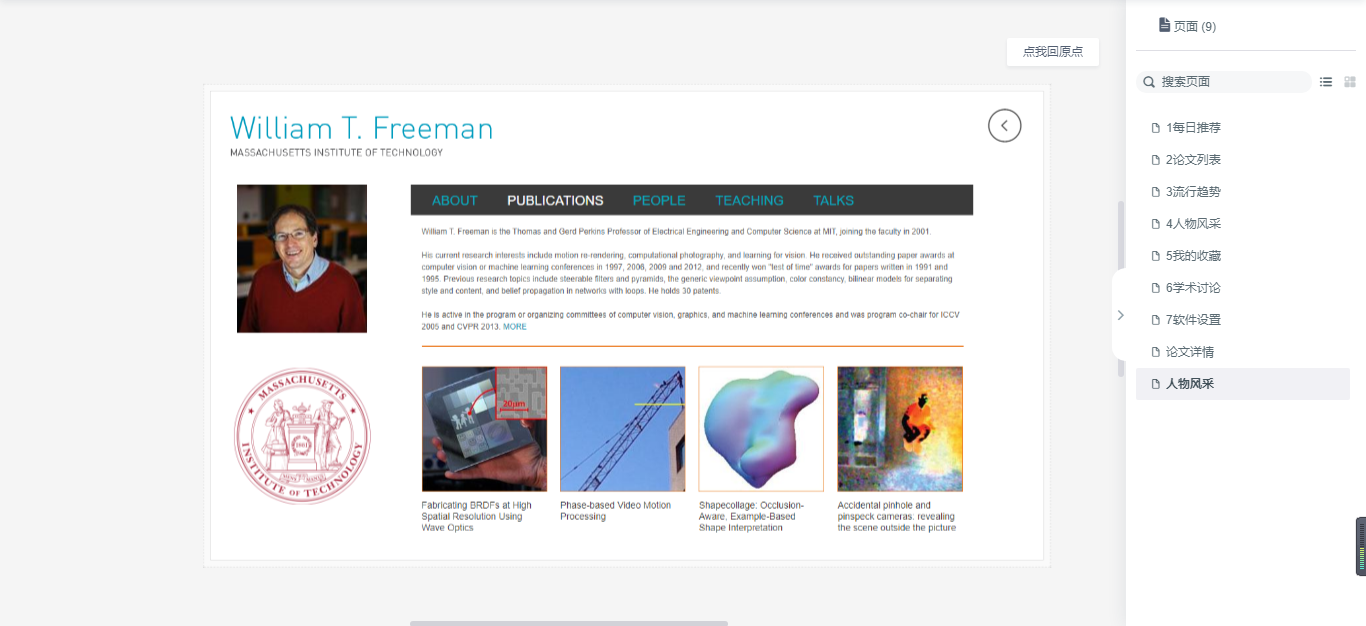
- 人物风采:展示顶会发言的风采人物简介。
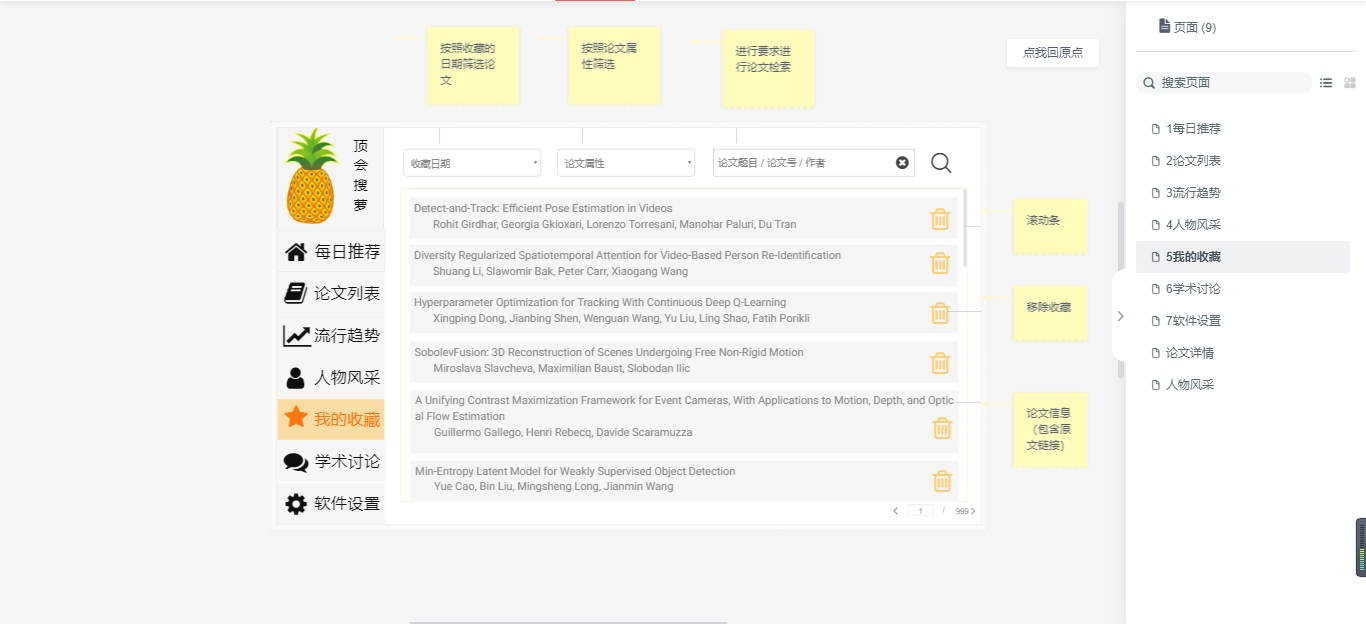
- 我的收藏:对用户收藏的论文进行按条件检索、移除收藏等操作。
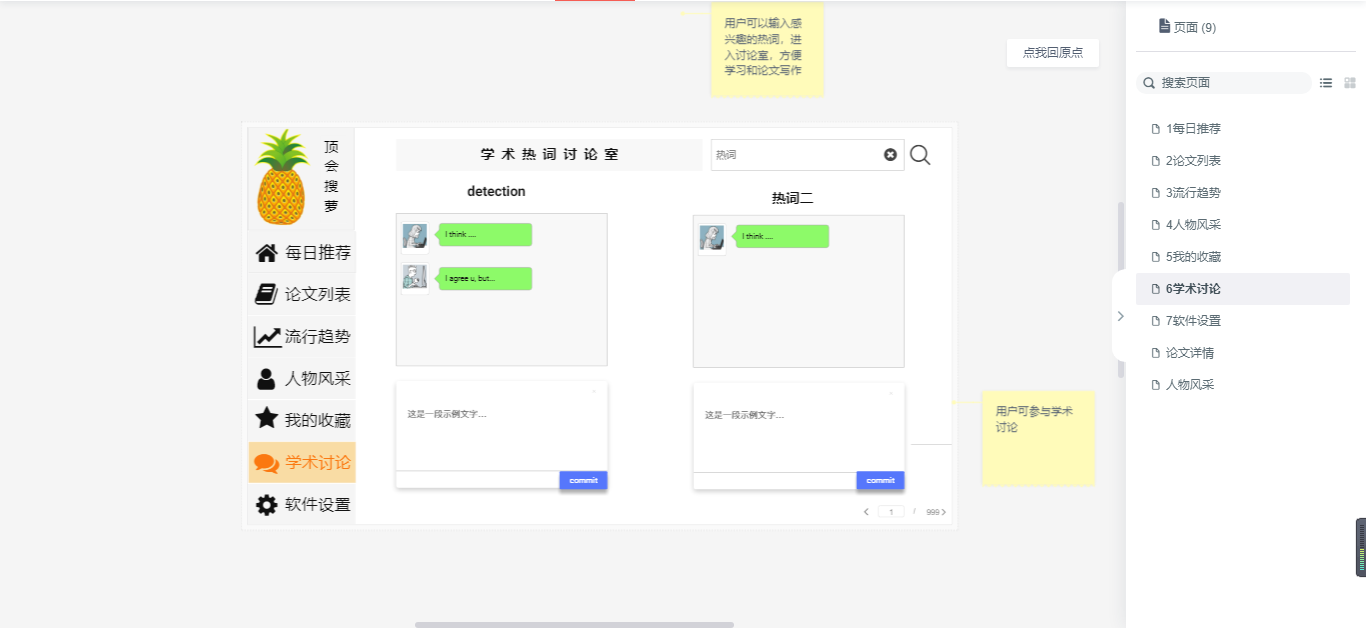
- 学术讨论:根据热词开辟的学术讨论室。
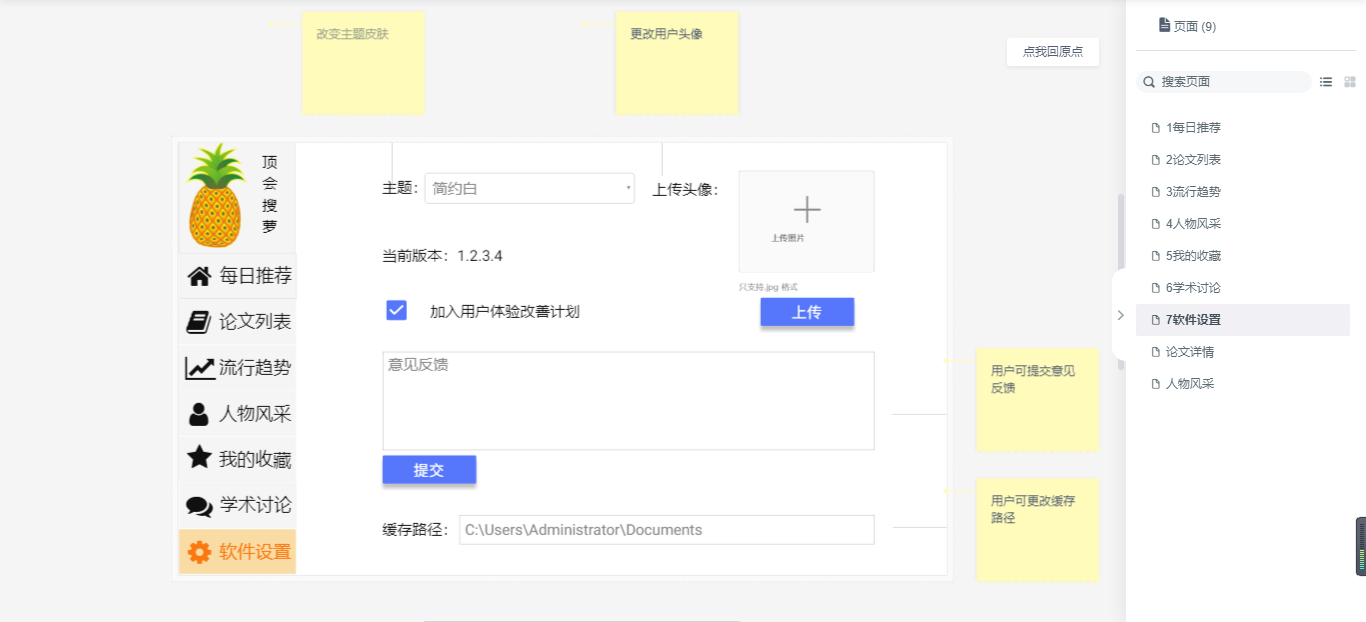
- 软件设置:更改软件的基本设置。
项目信息:
原型产品功能大致如下图(顶会搜萝的“萝”不是错别字,是故意设计的)

设计说明:
采用NABCD模型按部就班分析:
N (Need,需求)
根据题目用户小樱同学的问题和需求,总结如下:
用户的需求有:
1.需要有针对性的优质的论文推荐(热词分析,相关论文等)
2.需要有高效的查找工具(可以按一定条件对论文进行查找)
3.需要可视化的数据展示(如热词图谱之类)
4.需要了解各个国家学校的热门研究领域(如每个国家录用文章的分析、每个学校录用文章的分析、哪个学校哪方面的研究方向比较强等)
5.需要归纳整理优质论文
6.需要一个可以和志同道合的人进行学术交流的平台
用户存在的痛点有:
1.专业论文来源分散,论文查询不便
2.论文量庞大导致检索不方便,查询效率低
3.热点不断变化,不知道当前热点,导致对将来的研究方向无所适从
4.国际前沿人物多,对每个研究方向的领军人物不大了解
5.感兴趣的优质论文整理繁琐
6.想提升专业修养却缺乏学术交流的平台
A (Approach,做法)
解决方案的预期规划如下:
做法一:集合多个顶会网站论文
- 采用web端集合多个网站的论文来源,实现一个方便进行论文收集、整理的工具。
- 细化搜索功能,可以进行更有针对性的检索。
做法二:热点分析与相关推荐
- 根据当前热词和用户收藏进行相关推荐。还根据爬取的数据分析出当前研究热点并向用户进行数据可视化展示。
- 收集顶会发言者及相关领域大牛的研究方向和主要成就等信息,向用户展示。
做法三:论文收藏与管理
- 提供收藏整理工具,方便进行批量管理。
做法四:学术热词在线讨论
- 提供按照关键词分类的讨论区,方便用户进行更有针对性的交流。
B (Benefit,好处)
好处一:安装轻便
- 使用Web端实现,不需专门安装软件。具有良好的跨平台性,更好地兼容不同的机器。此外,还具有开发成本低、时间短,易于推广等优点。
好处二:搜索便捷
- 提供了更具有针对性的论文检索工具,进一步细化检索功能,可以更大程度地满足用户对于论文搜索的需要。
好处三:了解领域前沿热点与人物
- 对收集到的大数据进行可视化展示,用户可以更直观的获取到相关信息。
好处四:个性化论文收藏
- 论文收藏整理工具方便了用户对于感兴趣论文的批量管理。
好处五:在线讨论,提升专业修养
- 搜索热词,加入讨论,受益匪浅
好处六:相关论文推荐
- 每日推荐,不错过热点研究领域的优质论文。
C (Competitors,竞争)
相比于大多数市面产品,我们的产品
-
优势
- Web端实现的方式相较于App降低了开发成本,缩短了开发周期,可以更快地开发出产品,抢占市场。同时,用户迁移成本低,采用Web端实现有利于推广,可以更好地吸引新用户。版本更新时,用户不必重新下载,优化用户体验。
- 界面简洁,操作简单,方便上手,适用于各种对论文有需求的人群。
- 运行到浏览器上,不需要安装额外软件,控制版本容易。
- 拥有特色功能吸引有需求无法得到满足的用户
-
劣势
- 采用Web端实现,相较于App,首次加载更加耗时,对于流量的消耗也较大。
- 只能使用有限的移动设备能力,无法使用更多移动设备的独特功能
- 只能联网使用。
- web端导致推送功能受到一定限制
D (Delivery,推广)
- 可以与各专业教师、各实验室合作,以二维码、链接形式分享推广
- 与校方社团学习部联系开展活动推广产品
- 通过邀请新用户注册给予一定奖励形式推广
- 优质论文的分享(即可顺带推广)
原型模型:
软件名为:顶会搜萝
产品的取名灵感来自我们宿舍的吉祥物:菠萝
模型运行链接:点击打开
扫描二维码打开(建议用苹果机开,安卓显示不全)

模型截图:
1每日推荐

2论文列表
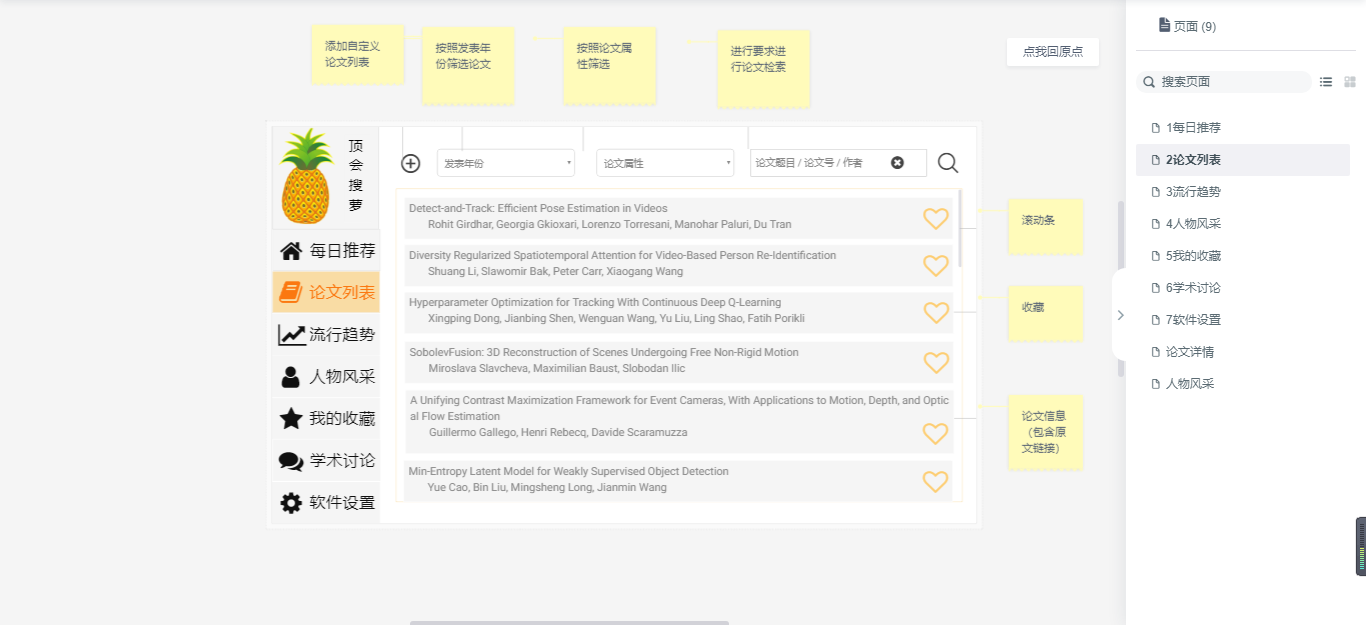
3流行趋势
4人物风采

5我的收藏
6学术讨论
7软件设置
论文详情页(点击标题跳转到源页面)

人物详情页
设计工具:
MockingBot 墨刀
结对过程:
困难解决:
- 对使用什么原型设计工具感到迷茫。试用过多种原型模型设计工具,最后通过翻阅多篇学长学姐留下的博客,最终决定使用MockingBot。
- 不知道需求分析要怎么做。不知道如何有条理地说服用户使用我们的产品。学习构建之法,认真学习软件需求的类型、利益相关者、获取用户需求的常用方法和步骤,最后按部就班分析自己设计的原型产品。
- 界面风格,功能布局的分歧,在讨论后,用草图画下双方讨论后的界面布局,对基本功能的实现和亮点创新功能的添加进行多次讨论并记录下来,防止遗忘利于更好协作制作。
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 4730 | - |
| · Analysis | · 需求分析 (包括学习新技术) | 1200 | 400 |
| · Design Spec | · 生成设计文档 | 60 | - |
| · Design Review | · 设计复审 | 60 | - |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 90 | - |
| · Design | · 具体设计 | 120 | - |
| · Coding | · 具体编码 | 2000 | - |
| · Code Review | · 代码复审 | 200 | - |
| · Test | · 测试(自我测试,修改代码,提交修改) | 1000 | - |
| Reporting | 报告 | 240 | |
| · Test Repor | · 测试报告 | 120 | - |
| · Size Measurement | · 计算工作量 | 60 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | |
| · | 合计 | 5000 |
学习进度条:
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 200 | 200 | 6 | 6 | 学习PyQt5的基本使用 |
| 2 | |||||
| 3 | |||||
| 4 |
结对照片:


心得总结:
蔡宇航
- 结对心得:
本次作业是软工实践的第一次多人合作的作业,合作的过程是这次实践作业最有收获的。
- 首先分工明确对于实现目标是很重要的。有了明确的分工之后,一开始我们尝试了去直接设计原型模型,设计的过程多次改动结果效率低下,最后决定一起讨论下基本功能的实现和创新功能的添加,然后画下各个界面功能布局的草图,再分工实现原型模型。
- 其次团队协作规范是很重要的,在原型模型的设计过程中,我和队友规定了自己制作的界面需要打上标注。标注后协作起来方便,通过标注也能更好结合用户需求痛点分析自己的模型是否满足用户需求,解决用户痛点。
- 最后,在讨论的过程中发表自己的独到看法,也听取队友的建议,在两个人的共同努力下实现原型模型的设计。讨论过程中的思想碰撞,一定程度避免了设计的片面,同时也使设计出来的产品更加人性化,利于使用。
对于这次原型模型设计:
- 阅读构建之法学习了很多需求分析的框架,NABCD模型也是第一次接触,学习到了很多,对于用户需求的分析,用户痛点的分析,针对这些给出做法分析好处,比较市场中产品和自己设计产品之间的优劣,最后思考推广的方法,按部就班,整个逻辑体系更加紧密,设计过程就更加流畅合理。
- 接触了各种各样的原型模型的设计工具(虽然最后选择了墨刀),对于原型设计的理解也更深刻了,学习到了很多。
- 对于针对用户需求和痛点的产品设计,不断地构思,包括怎样的界面布局更好看,参考了一些市面上的优质软件的布局,也学习到了很多。
陈柏涛
-
结对心得:
-
这次任务不同于以往单纯的只要打代码的任务,而是要对客户的需求做出分析,从中提取出客户真正的需求,为后面的开发指明方向。做需求分析虽然费时费力,但是它的确可以在一定程度上减轻后期开发的工作量。磨刀不误砍柴工或许就是这样吧。
-
我学会了需求分析的方法,尤其是NABCD模型的使用。不仅要站在客户的角度分析问题,指明客户真正的痛点,有针对性地做出解决方案,还要从软件开发者的角度,从技术上验证开发的可行性与成本,还要站在竞争对手的角度考虑问题,分析各种产品的利弊,提出新的点子,让自己的产品脱颖而出。
-
三个臭皮匠顶个诸葛亮。需求分析不是一个人的事,而是要与团队成员共同讨论。每个人都有截然不同的成长经历,对同一个问题往往有不同的看法。积极与队友交流讨论,在思想的碰撞中产生创意的火花。
-
对于顶会论文研究热点的确有迫切需求,但当前市面上还没有相关的较为成熟的软件。将来有时间(或许是假期)会拉上队友一起将之实现。