前言:前面学习了表锁的相关知识,本篇主要介绍行锁的相关知识。行锁偏向InnoDB存储引擎,开销大,加锁慢,会出现死锁,锁定粒度小,发生锁冲突的概率低,但并发度高。
0.准备
#1.创建相关测试表tb_innodb_lock,注意数据库引擎为InnoDB。
CREATE TABLE test_innodb_lock (
a INT (11),
b VARCHAR (20)
) ENGINE INNODB DEFAULT charset = utf8;
insert into test_innodb_lock values (1,'a');
insert into test_innodb_lock values (2,'b');
insert into test_innodb_lock values (3,'c');
insert into test_innodb_lock values (4,'d');
insert into test_innodb_lock values (5,'e');
#2.创建索引。
create index idx_lock_a on test_innodb_lock(a); create index idx_lock_b on test_innodb_lock(b);
1.行锁定基本演示
#1.打开A、B另个会话,并关闭数据库的自动提交。
set autocommit=0;
#2.在A会话中做更新操作。
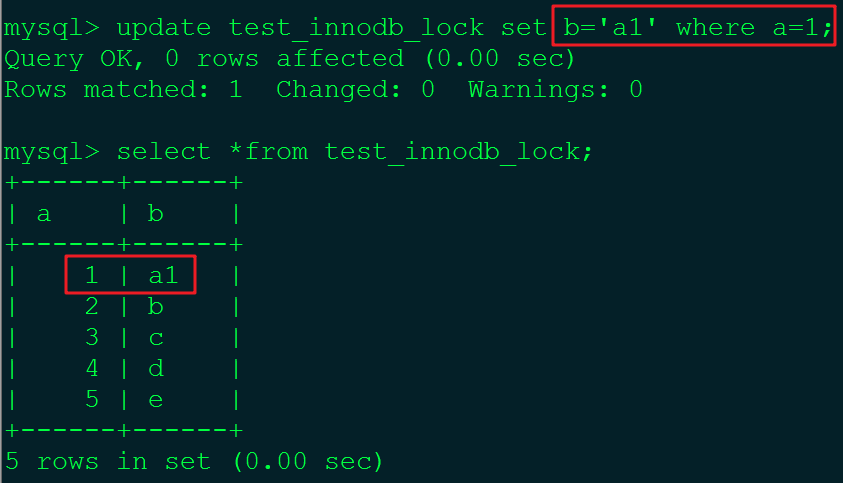
从查询结果可知:在A会话中更新数据成功。
#3.在B会话中做查询操作。
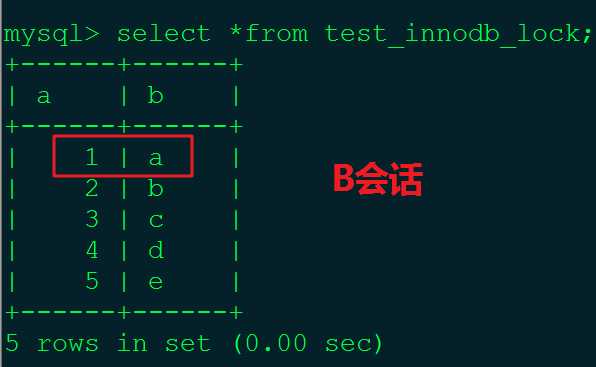
分析:
B会话中并没有读取到A会话中更新后的值。(读己知所写:自己更改的数据自己知道,但是如果未提交,其他人是不知道的。)
#4.在A会话中执行commit命令,然后在B会话中再次查询。
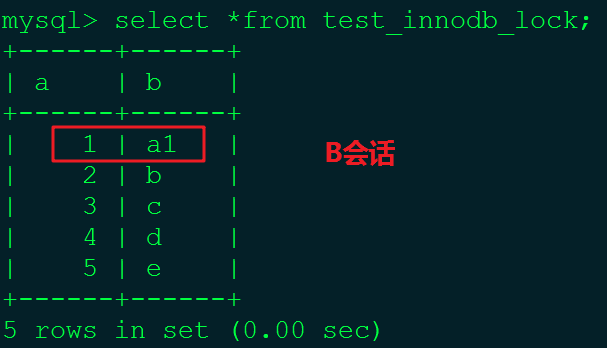
#5.在A会话中做更新操作,然后在B会话中也做更新操作。


这时在A会话中commit操作,可看到B会话中发生了更新操作。

分析:
因为我们操作的同一行数据,而由于InnoDB为行锁,在A会话未提交时,B会话只有阻塞等待。如果操作不同行,则不会出现阻塞情况。
2.索引失效导致行锁升级为表锁
#1.在A会话中执行如下更新语句。

#2.在B会话中执行如下更新语句。

分析:
首先将表中的数据更新为b=1000,2000,3000,4000,5000。
在A会话中操作的第一行数据,但是where中使用了b=1000,发生了自动转换导致索引失效,从而使锁的级别从行锁升级为表锁,因此B会话中操作第五行数据出现阻塞的情况。
3.间隙锁的危害
#1.间隙锁定义:
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁,对于键值在条件范围内但不存在的记录,叫作“间隙(GAP)”。
InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁。(Next-Key锁)
#2.间隙锁危害:
因为在Query执行过程中通过范围查找的话,会锁定整个范围内的所有索引键值,即使这个索引不存在。间隙锁有一个比较致命的弱点,就是当锁定一个范围键值后,即使某些不存在的键值也会被无辜的锁定,而造成在锁定的时候无法插入锁定值范围内的任何数据。在某些场景下这个可能会对性能造成很大的危害。
#3.间隙锁演示。
要演示间隙锁,我们需要对test_innodb_lock中的数据进行修改,修改后的数据如下:
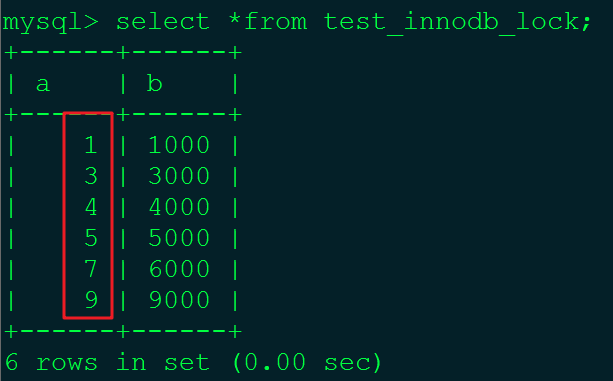
注:a列的值并不连续。
①在A会话中执行如下语句。

②在B会话中执行如下语句。

只有在A会话commit后,B会话才能进行插入操作。
4.如何锁定某一行
利用for update。
①在A会话中执行如下语句。
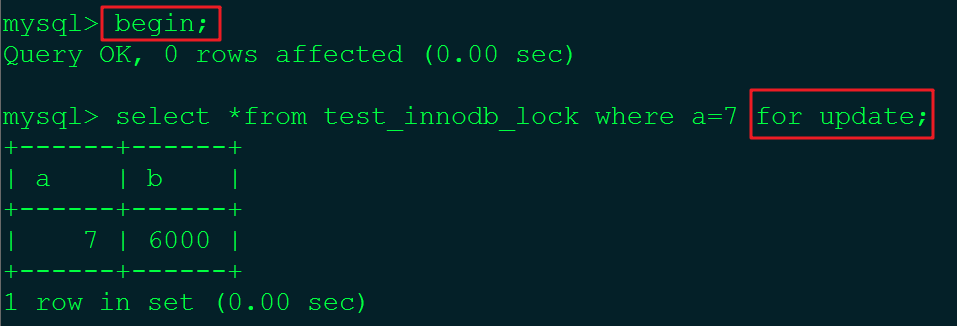
此时就锁定了a=7这一行。
②在B会话中对该行进行更新操作。

只有在A会话中进行了commit后,B会话的更新操作才能执行。

5.行锁分析
#1.使用如下命令。
show status like 'innodb_row_lock%';
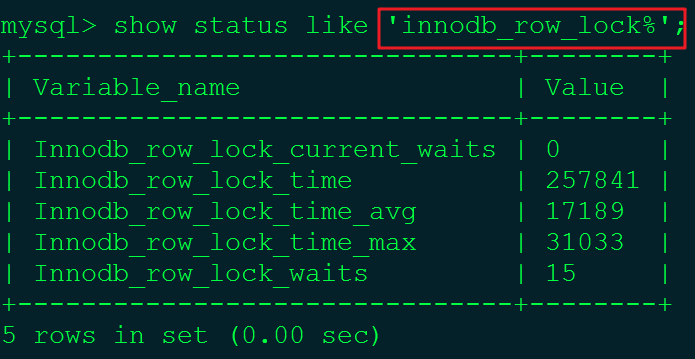
各个状态量说明:
①Innodb_row_lock_current_waits:当前正在等待锁定的数量。
②Innodb_row_lock_time:从系统启动到现在锁定的时长。
③Innodb_row_lock_time_avg:每次等待锁所花平均时间。
④Innodb_row_lock_time_max:从系统启动到现在锁等待最长的一次所花的时间。
⑤Innodb_row_lock_waits:系统启动后到现在总共等待锁的次数。
这个五个状态量中,比较重要的是:
Innodb_row_lock_time、Innodb_row_lock_time_avg和Innodb_row_lock_waits。尤其是等待次数很高,而且每次等待时长不小时,就需要分析优化了。
6.优化建议
①尽可能让所有数据都通过索引来完成,避免无索引行升级为表锁。
②合理设计索引,尽量缩小锁的范围。
③尽可能使用较少的检索条件,避免间隙锁。
④尽量控制事务大小,减少锁定资源量和时间长度。
⑤尽可能降低事务隔离级别。
7.页锁
开销和加锁时间介于表锁和行锁之间,会出现死锁,锁定粒度介于表锁和行锁之间,并发度一般(了解即可)。
总结
①InnoDB存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面所带来的性能损耗可能比表级锁定会更高一些(多个锁,一个锁),但是在整体并发处理能力方面要远远优于MyISAM的表级锁定。当系统处于高并发量的时候,InnoDB的整体性能和MyISAM相比就会有比较明显的优势了。
②InnoDB的行锁定同样尤其脆弱的一面(间隙锁危害),当使用不当时可能会让InnoDB的整体性能表现不仅不能比MyISAM高,甚至可能更差。