一、使用Docker-compose实现Tomcat+Nginx负载均衡
参考资料:
Nginx 配置详解
Nginx服务器之负载均衡策略
nginx负载均衡的常用策略
(1)nginx反向代理原理
1.工作原理
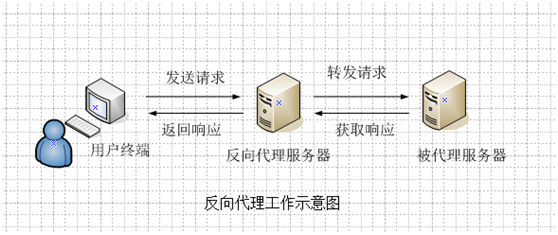
客户端向反向代理发送请求,接着反向代理转发请求至目标服务器,并把获得的内容返回给客户端。
2.正向代理和反向代理的对比
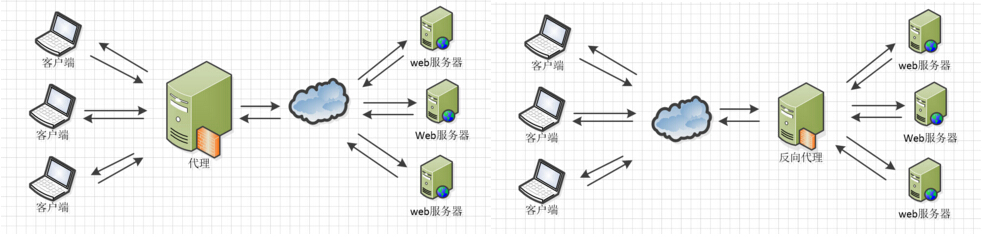
对于正向代理和反向代理的区别,在查阅资料的时候看到了一个通俗易懂的解释:
Nginx正向代理与反向代理
正向代理:客户端 <一> 代理 一>服务端
打个租房的比方:
A(客户端)想租C(服务端)的房子,但是A(客户端)并不认识C(服务端)租不到。
B(代理)认识C(服务端)能租这个房子所以你找了B(代理)帮忙租到了这个房子。
这个过程中C(服务端)不认识A(客户端)只认识B(代理)
C(服务端)并不知道A(客户端)租了房子,只知道房子租给了B(代理)。
反向代理:客户端 一>代理 <一> 服务端
反向代理也用一个租房的例子:
A(客户端)想租一个房子,B(代理)就把这个房子租给了他。
这时候实际上C(服务端)才是房东。
B(代理)是中介把这个房子租给了A(客户端)。
这个过程中A(客户端)并不知道这个房子到底谁才是房东
他都有可能认为这个房子就是B(代理)的
由上的例子和图我们可以知道正向代理和反向代理的区别在于代理的对象不一样,正向代理的代理对象是客户端,反向代理的代理对象是服务端。
(2)nginx代理tomcat集群,代理2个以上tomcat
1.项目结构如下
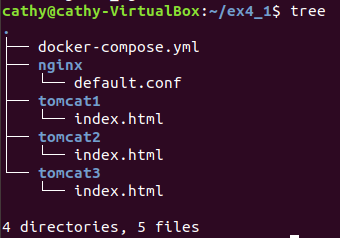
2.编写文档
docker-compose.yml
version: "3"
services:
nginx:
image: nginx
container_name: ex4_nginx
ports:
- "80:80"
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat01
- tomcat02
- tomcat03
tomcat01:
image: tomcat
container_name: ex4_tomcat1
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录
tomcat02:
image: tomcat
container_name: ex4_tomcat2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
tomcat03:
image: tomcat
container_name: ex4_tomcat3
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
default.conf
upstream tomcats {
server ex4_tomcat1:8080; # 主机名:端口号(主机名与yml文档对应)
server ex4_tomcat2:8080; # tomcat默认端口号8080
server ex4_tomcat3:8080; # 默认使用轮询策略
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
以及三个不同的index.html文件,用于区分Tomcat
3.运行sudo docker-compose up -d --build

4.查看配置是否正确
4.1访问浏览器http://localhost
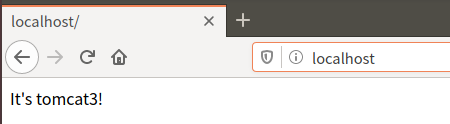
刷新会显示tomcat1和tomcat2的网页内容(tomcat1、tomcat2、tomcat3的内容轮流出现)
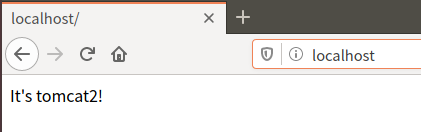
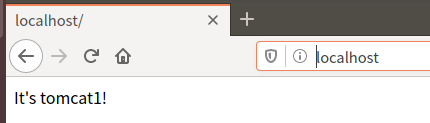
4.2查看容器

容器正常启动,配置正确
(3)负载均衡策略
1.轮询策略
1.1编写python代码用测试轮询策略
ex4_text1.py
import requests
url="http://localhost"
for i in range(0,10):
reponse=requests.get(url)
print(reponse.text)
1.2 运行脚本

2.权重方式
在轮询策略的基础上指定轮询的几率,weight参数用于指定轮询几率,weight的默认值为1,weight的数值与访问比率成正比
2.1 修改default.conf文档
upstream tomcats {
server ex4_tomcat1:8080 weight=3; #设置权重的比值(3:5:1)
server ex4_tomcat2:8080 weight=5;
server ex4_tomcat3:8080 weight=1;
}
2.2 重启nginx容器

2.3 编写python代码用测试轮询策略
ex4_text2.py
import requests
url='http://localhost'
count={}
for i in range(0,99):
response=requests.get(url)
if response.text in count:
count[response.text]+=1;
else:
count[response.text]=1
print(count)
因为权重比值设置为(3:5:1)所以将执行次数设置为9的倍数了
2.4 运行脚本

可以看到执行99次的结果(33:55:11)与设置的权重的比值(3:5:1)是一致的
3.基于客户端IP的分配方式(ip_hash)
3.1 修改default.conf文档
upstream tomcats {
ip_hash; #保证每个访客固定访问一个后端服务器
server ex4_tomcat1:8080 weight=3;
server ex4_tomcat2:8080;
server ex4_tomcat3:8080 max_fails=3 fail_timeout=20s;
}
- weight 权重过大代表承担的负载就越大
- max_fails 失败超过指定次数会暂停或请求转往其它服务器
- fail_timeout 失败超过指定次数后暂停时间
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题
重启nginx容器后运行py脚本

二、使用Docker-compose部署javaweb运行环境
参考资料:
使用docker-compose部署Javaweb项目
tomcat+nginx-mysql
这里使用老师给定的javaweb参考项目
(1)构建镜像服务,部署Javaweb程序
1.项目结构如下
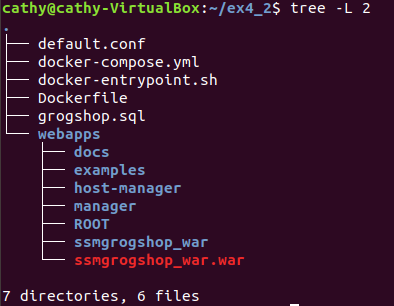
2.添加的文档如下
default.conf
server tomcat1:8080; #默认使用轮询策略
server tomcat2:8080;
}
server {
listen 2020;
server_name localhost;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
proxy_pass http://tomcats;
}
docker-entrypoint.sh
#!/bin/bash
mysql -uroot -p123456 << EOF # << EOF 必须要有
source /usr/local/grogshop.sql;
docker-compose.yml
version: "3" #版本
services: #服务节点
tomcat1: #tomcat 服务
image: tomcat #镜像
hostname: hostname #容器的主机名
container_name: tomcat1 #容器名
ports: #端口
- "5050:8080"
volumes: #数据卷
- "./webapps:/usr/local/tomcat/webapps"
- ./wait-for-it.sh:/wait-for-it.sh
networks: #网络设置静态IP
webnet:
ipv4_address: 15.22.0.15
tomcat2: #tomcat 服务
image: tomcat #镜像
hostname: hostname #容器的主机名
container_name: tomcat2 #容器名
ports: #端口
- "5055:8080"
volumes: #数据卷
- "./webapps:/usr/local/tomcat/webapps"
- ./wait-for-it.sh:/wait-for-it.sh
networks: #网络设置静态IP
webnet:
ipv4_address: 15.22.0.16
mymysql: #mymysql服务
build: . #通过MySQL的Dockerfile文件构建MySQL
image: mymysql:test
container_name: mymysql
ports:
- "3309:3306"
#红色的外部访问端口不修改的情况下,要把Linux的MySQL服务停掉
#service mysql stop
#反之,将3306换成其它的
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_unicode_ci'
]
environment:
MYSQL_ROOT_PASSWORD: "123456"
networks:
webnet:
ipv4_address: 15.22.0.6
nginx:
image: nginx
container_name: "nginx-tomcat"
ports:
- 8080:8080
volumes:
- ./default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
tty: true
stdin_open: true
depends_on:
- tomcat1
- tomcat2
networks:
webnet:
ipv4_address: 15.22.0.7
networks: #网络设置
webnet:
driver: bridge #网桥模式
ipam:
config:
-
subnet: 15.22.0.0/24 #子网
Dockerfile
# 这个是构建MySQL的dockerfile
FROM registry.saas.hand-china.com/tools/mysql:5.7.17
# mysql的工作位置
ENV WORK_PATH /usr/local/
# 定义会被容器自动执行的目录
ENV AUTO_RUN_DIR /docker-entrypoint-initdb.d
#复制gropshop.sql到/usr/local
COPY grogshop.sql /usr/local/
#把要执行的shell文件放到/docker-entrypoint-initdb.d/目录下,容器会自动执行这个shell
COPY docker-entrypoint.sh $AUTO_RUN_DIR/
#给执行文件增加可执行权限
RUN chmod a+x $AUTO_RUN_DIR/docker-entrypoint.sh
# 设置容器启动时执行的命令
#CMD ["sh", "/docker-entrypoint-initdb.d/import.sh"]
3.修改连接数据库的IP
使用如下命令查找Linux本机IP
ifconfig -a
vim ~/ex4_2/webapps/ssmgrogshop_war/WEB-INF/classes/jdbc.properties

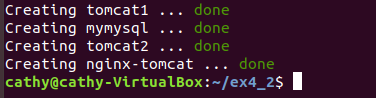
4.启动容器
docker-compose up -d
(2)测试两个tomcat服务器负载均衡,并进行简单的数据库操作
1.使用浏览器访问
http://10.0.2.15:5050/ssmgrogshop_war
用户名sa
密码123
2.测试两个tomcat服务器负载均衡
访问
http://10.0.2.15:5055/ssmgrogshop_war
可以看到5050端口和5055端口都可以访问
3.数据库操作
3.1 新增记录
3.2 修改记录
3.3 删除记录

三、使用Docker搭建大数据集群环境
参考资料:
使用Docker搭建Hadoop分布式集群
(1)在Docker安装Ubuntu系统
1.拉取镜像
sudo docker pull ubuntu
2.在Docker上开启这Ubuntu系统,在启动Ubuntu镜像时,需要先在个人文件下创建一个目录,用于向Docker内部的Ubuntu系统传输文件
cd ~
mkdir build
3.在Docker上运行Ubuntu系统
docker run -it -v /home/hadoop/build:/root/build --name ubuntu ubuntu

(2)Ubuntu系统初始化
1.容器内换源
Ubuntu版本为:Ubuntu 18.04 LTS

2.更新系统软件源
apt-get update
3.安装vim
apt-get install vim
4.安装sshd
apt-get install ssh #在开启分布式Hadoop时,需要用到ssh连接slave
/etc/init.d/ssh start #运行该脚本即可开启sshd服务器
vim ~/.bashrc #将上一行的启动命令写进~/.bashrc文件,这样每次登录Ubuntu系统时,都能自动启动sshd服务
vim编辑器的使用可参考:
Linux中vi编辑器的使用详解
5.配置sshd
需要配置ssh无密码连接本地sshd服务
ssh-keygen -t rsa # 一直按回车即可
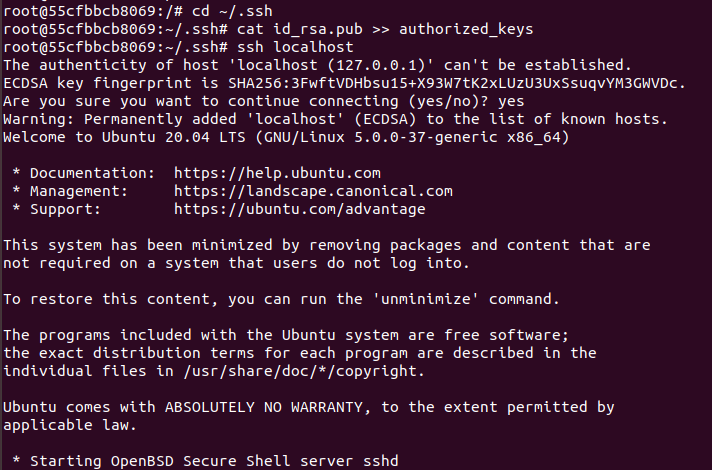
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
免密连接localhost成功
6.安装JDK
apt install openjdk-8-jdk #使用JDK8版本
vim ~/.bashrc # 在文件末尾添加以下两行,配置Java环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
source ~/.bashrc # 使~/.bashrc生效
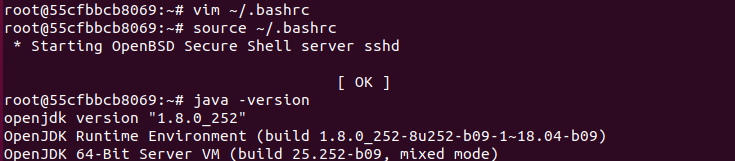
配置成功
7.开一个新终端,保存镜像文件
sudo docker ps #查看当前ubuntu的镜像id
sudo docker commit 容器id ubuntu/jdk8 #保存当前镜像
(3)安装Hadoop
1.开启保存的那份镜像
sudo docker run -it -v /home/cathy/build:/root/build --name ubuntu-jdk8 ubuntu/jdk8
2.把下载下来的Hadoop安装文件放到共享目录/home/cathy/build下面后,执行如下命令进行安装
cd /root/build
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local
3.配置并测试安装
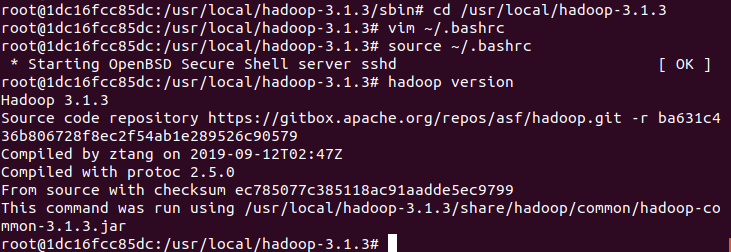
cd /usr/local/hadoop-3.1.3
vim ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop-3.1.3
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin
source ~/.bashrc # 使.bashrc生效
hadoop version
(4)配置Hadoop集群
1.打开hadoop_env.sh文件,修改环境变量
cd /usr/local/hadoop-3.1.3/etc/hadoop #进入配置文件存放目录
vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ #修改环境变量
2.修改core-site.xml
vim core-site.xml
输入以下内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
3.修改hdfs-site.xml
vim hdfs-site.xml
输入以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
4.修改mapred-site.xml
vim mapred-site.xml
输入以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value>
</property>
</configuration>
5.修改yarn-site.xml
vim yarn-site.xml
输入以下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.5</value>
</property>
</configuration>
6.修改脚本
cd /usr/local/hadoop-3.1.3/sbin
6.1修改start-dfs.sh和stop-dfs.sh文件
分别进入两个文件后添加如下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
6.2修改start-yarn.sh和stop-yarn.sh文件
分别进入两个文件后添加如下参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
(5)运行Hadoop集群
1.打开新的终端,保存镜像
sudo docker commit 容器id ubuntu/hadoopinstalled
2.在三个终端上开启三个容器运行ubuntu/hadoopinstalled镜像,分别表示Hadoop集群中的master,slave01和slave02
# 第一个终端
sudo docker run -it -h master --name master ubuntu/hadoopinstalled
# 第二个终端
sudo docker run -it -h slave01 --name slave01 ubuntu/hadoopinstalled
# 第三个终端
sudo docker run -it -h slave02 --name slave02 ubuntu/hadoopinstalled
3.配置master,slave01和slave02的地址信息
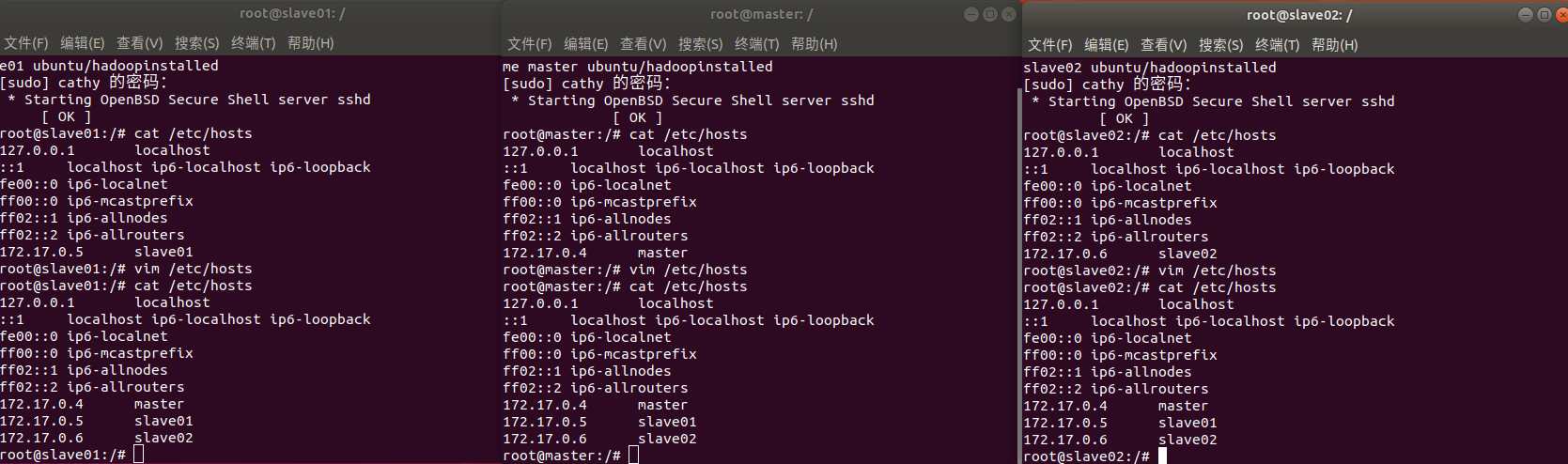
3.1 在三个终端使用cat /etc/hosts可以查看本机的ip和主机名信息,最后得到三个ip和主机地址信息如下
172.17.0.4 master
172.17.0.5 slave01
172.17.0.6 slave02
3.2 使用如下命令上述三个地址信息分别复制到master,slave01和slave02的/etc/hosts
vim /etc/hosts
4.检测是否master是否可以连上slave01和slave02
ssh slave01
exit
ssh slave02
exit
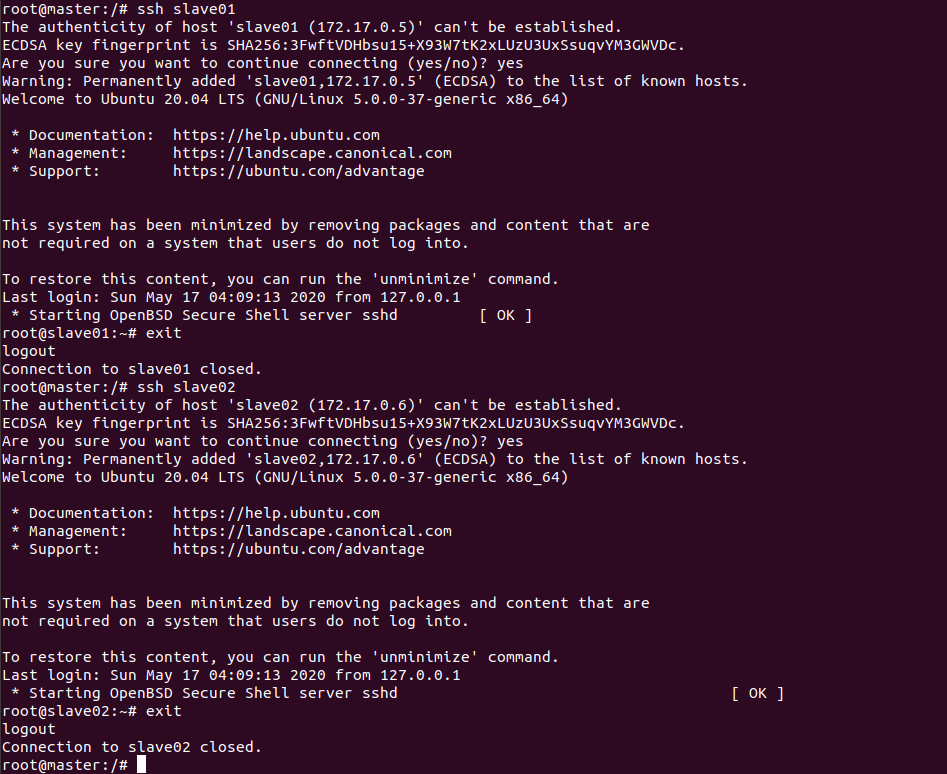
5.打开master上的slaves文件,输入两个slave的主机名
vim etc/hadoop/slaves
# 将localhost替换成两个slave的主机名
slave01
slave02
(6)启动并测试Hadoop集群
1.启动
在master终端执行
cd /usr/local/hadoop-3.1.3
bin/hdfs namenode -format
sbin/start-all.sh #启动所有服务
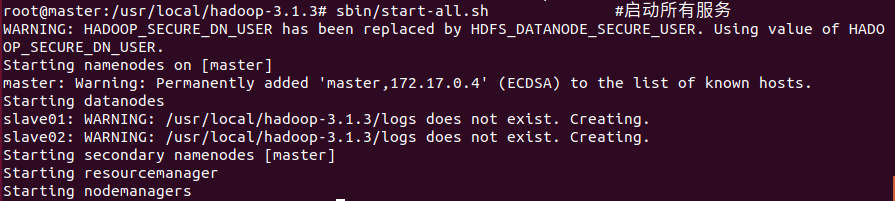
2.在master,slave01和slave02上分别运行命令jps查看运行结果

(7)运行Hadoop实例程序
1.在master终端执行
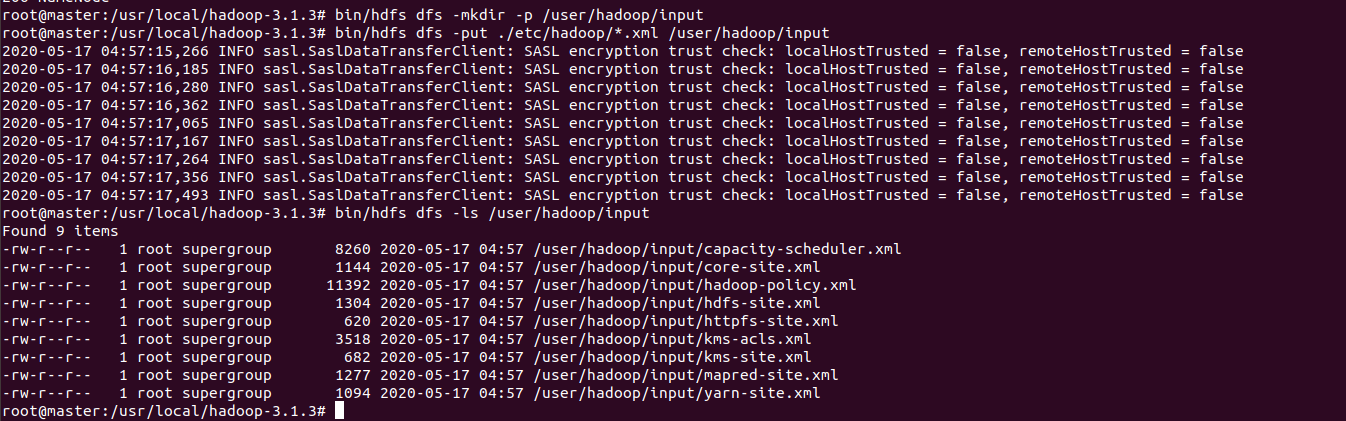
bin/hdfs dfs -mkdir -p /user/hadoop/input
bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
bin/hdfs dfs -ls /user/hadoop/input
2.执行实例并查看运行结果
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep /user/hadoop/input output 'dfs[a-z.]+'
bin/hdfs dfs -cat output/*


四、遇到的问题及解决方法
(1)上学期把virtualbox放在C盘,第三部分做到一半,C盘就剩2G了,所以决定把虚拟机移到E盘
解决方法:
参考:
VirtualBox虚拟机路径迁移方法
VirtualBox 如何快速迁移虚拟机
结合了这两个博客的方法
因为第一个博客的最后一步出错了,接着就用了第二个博客的方法
顺便附上清理ubuntu垃圾的方法
Ubuntu清理硬盘空间的8个技巧
(2)运行Hadoop实例程序的时候遇到了HDFS上传文件异常的问题
倒闭孩子的通宵日常

尝试了很多解决方法,最后决定重做了
原因:配置出了问题
解决方法:重新配置
这一次重做最后就成功啦
(3)在master,slave01和slave02终端无法使用vim等操作,并且没有实现ssh无密码连接本地sshd服务
原因:没有在容器里进行安装和配置
解决方法:重做,安装和配置需要在容器中进行
诸如此类的问题太多啦,基本都是由于疏忽。
五、花费时间
| 作业名称 | 耗时(小时) |
|---|---|
| 使用Docker-compose实现Tomcat+Nginx负载均衡 | 2.5 |
| 使用Docker-compose部署javaweb运行环境 | 3 |
| 使用Docker搭建大数据集群环境 | 16 |
| 博客编写 | 1.5 |
| 总计 | 23 |
六、小结
第三部分从中午做到第二天凌晨五点我真的自闭了,返回前几步重做或者全部重做反复了好几次,中间还把虚拟机移到了E盘,主要是出错的时候不知道究竟哪一步错了,容错率太低了,在重做的边缘试探。最开始看教程忽略了一些要点导致了不必要的周折,好不容易做到最后测试实例,以为就要可以睡觉了,结果还是有问题,最后耐心地看了一些博客再放慢速度重做了一遍就成功啦,真的要在开始的时候就减少一些疏忽,爬坑太累啦,熬夜也好累,不过也在爬坑的过程中也加深了对理论和实践的理解。
通过这次的实践学习了Tomcat+Nginx负载均衡,javaweb的部署运以及使用Docker搭建大数据集群环境,这次的是比较具有综合性的实践,进一步熟悉了前几次实践的相关内容,花了比较多的时间,但是感觉收获满满。