0. 雁字无多
我这两天要是再不学习一下之后可能时间就很少了,期末作业是做了一些了。但是,今天接到一个大任务,今年实验室招标和项目我负责。就在我写这段文字的时候,我老板进来了。正好,我就继续写吧。可是又说了半天招标的事情,说XX所好赚钱好赚钱,流程怎么怎么跑,要去招标局和公司做啥做啥。
这周换了一本书开始看,觉得没有上一本写的好。现在感觉这些书对我帮助不是很大了,书其实没有一些CSDN上的精品博客写的好。今天想写一下CNN的经典网络吧,做图像识别分类的。要具体的讲,自2012年开始,基于CNN用于打ILSVRC图像识别大赛的几大经典网络分别是:AlexNet,VGGNets,GoogLeNet&Inception和ResNets。这几大具有统治力的模型也是每年一更新不断刷新识别率与准确率。具体每个网络的结构、异同点不妨CSDN去看看,可以根据实际需求选择一个。
下面我也就个人的理解对这几大网络做一个背景的简要描述。
AlexNet 在2012年被提出是被认为开创了深度学习的时代,大数据、GPU、ReLu函数(加快收敛速度)和dropout(防止过拟合)等技术也都是为它的出现奠定了基础。它包含5层卷积层和3层全连接层如图1,这是网上的一张经典图形。因为ILSVRC是个千分类问题,所以全连接层最后的softmax输出为1000维向量。不过现在实际应用中现在很难看到AlexNet,毕竟它只是作为LeNet网络的一个历史突破性版本,它具有历史里程意义,但技术价值已经不如后面的新贵们了。
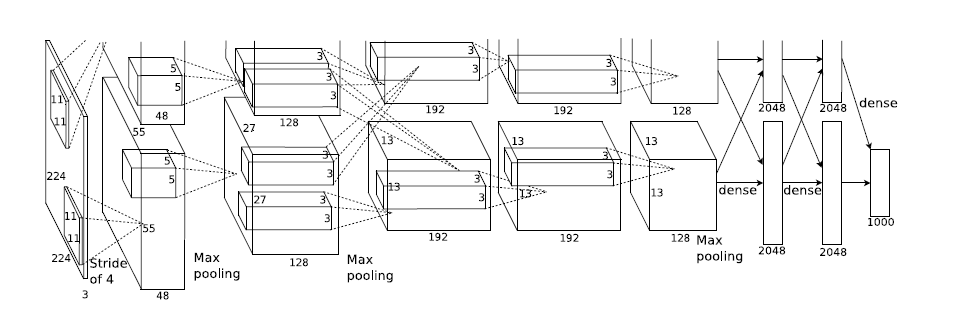
图1 AlexNet
VGGNet 是在AlexNet基础之上提出的,网络结构相似。不同点在于,VGGNet是在每一层卷积层上连续卷积2~4次,结构上与AlexNet相比并没有做什么改变,在此不再赘述。VGGNet对深度学习最大的贡献莫过于:不考虑其他因素(计算存储等),CNN网络的深度不断加深(增加卷积次数,通俗讲就是使计算复杂化)可以提升准确率。这也成为了现在做机器学习提升效果的核心方法之一:加深网络、数据增强和模型融合。另外调参也很重要。虽然VGGNet参数很多,但由于设计上的很多细节,它能够很快收敛,具体原因我需要提一下吗....好吧,主要是卷积核大小比较小。最后还需要说一点,无脑的加深网络深度是不能得到效果的线性提升,这是因为参数变多之后误差函数的梯度弥散问题,导致网络在训练时无法收敛(无论从顺着哪个参数的梯度进行下降都无法使误差减小,因为梯度求导几乎为0)。比如VGGNet在超过20层后就效果就会下降。这个梯度弥散问题在后续的ResNets得到了一定程度的解决。
GoogLeNet 与VGGNet在相比,在内存和计算消耗方面有非常大的优势。AlexNet增多卷积次数,不可避免使其增多了权值参数个数,它共有6000万个权值参数,是AlexNet的三倍以上;而GoogleLeNet只有500万个参数,所以在内存较小的移动端GoogLeNet有着更广泛的应用。当时提出GoogLeNet,就是因为Google的学者们虽然同意像AlexNet那样加深网络深度可以提高识别准确率,但如何更加有效的加深网络深度,使其能够在保证准确率提升的前提下尽可能的“轻量”,所以开启了名为Inception的项目工程。GoogLeNet就是InceptionV1版本,现在已经发布到InceptionV4版本——结合ResNets的GoogLeNet。具体的发展与区别可以百度了解一下。结构图是实在很复杂如图2。
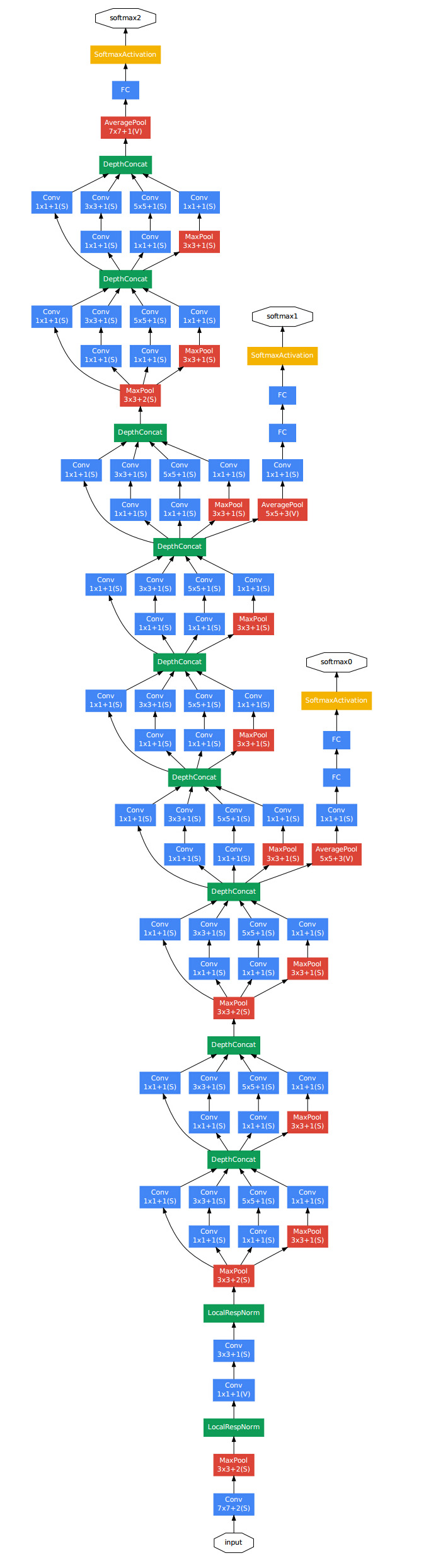
图2 GoogLeNet
ResNets 是2016年微软亚研院的何凯明博士及其团队提出的深度残差网络。其最大的亮点就是通过设计的残差网络结构,避免了随着随着网络层数加深而产生的梯度消失或梯度爆炸的问题(该问题被称为深度网络的退化问题,degradation problem),不但能使深度神经网络的收敛速度更快、精度更高,而且让加深网络深度来提高网络效果成为可能。在学习的时候,很多博客和教材会把ResNets的网络结构同VGG进行对比学习,如图3。
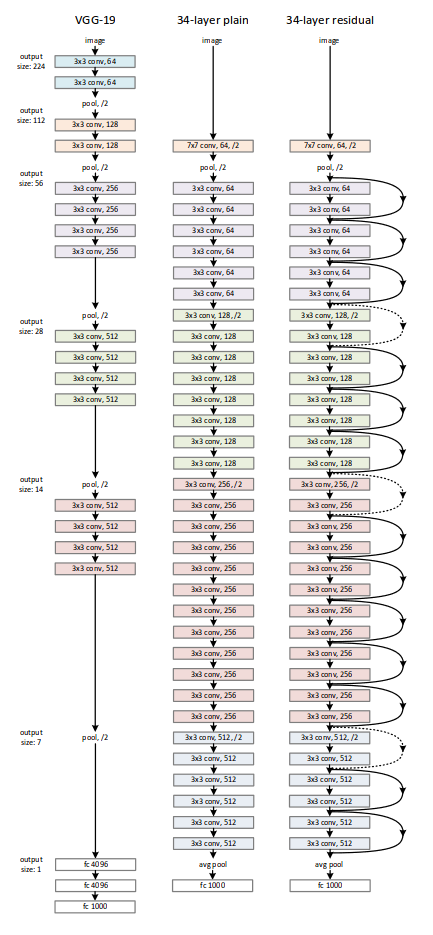
图3 ReNets
1. 写得相思几许
这几大网络github上有很好的项目工程,python3.6+tensorflow1.7亲测可用。贴一个链接吧:https://github.com/MachineLP/train_arch。
这一小节还是得弄一点干货吧哈哈哈,那就上一个我自己调通了把数据集下载这些都合成在一个py文件的GoogLeNet吧。InceptionV3,代码参考上述链接。
|
from __future__ import absolute_import
from __future__ import division from __future__ import print_function import argparse import os.path import re import sys import tarfile import numpy as np from six.moves import urllib import tensorflow as tf FLAGS = None DATA_URL = 'http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz' # NodeLookup类负责将分类器输出的类别编号与人类可读的标签名称对应起来 class NodeLookup(object): def __init__(self, label_lookup_path=None, uid_lookup_path=None): if not label_lookup_path: label_lookup_path = os.path.join( FLAGS.model_dir, 'imagenet_2012_challenge_label_map_proto.pbtxt') if not uid_lookup_path: uid_lookup_path = os.path.join( FLAGS.model_dir, 'imagenet_synset_to_human_label_map.txt') self.node_lookup = self.load(label_lookup_path, uid_lookup_path) # 为每一个softmax节点读取人类可读的类标英文名字 def load(self, label_lookup_path, uid_lookup_path): if not tf.gfile.Exists(uid_lookup_path): tf.logging.fatal('File does not exist %s', uid_lookup_path) if not tf.gfile.Exists(label_lookup_path): tf.logging.fatal('File does not exist %s', label_lookup_path) # Loads mapping from string UID to human-readable string proto_as_ascii_lines = tf.gfile.GFile(uid_lookup_path).readlines() uid_to_human = {} p = re.compile(r'[nd]*[ S,]*') for line in proto_as_ascii_lines: parsed_items = p.findall(line) uid = parsed_items[0] human_string = parsed_items[2] uid_to_human[uid] = human_string # Loads mapping from string UID to integer node ID. node_id_to_uid = {} proto_as_ascii = tf.gfile.GFile(label_lookup_path).readlines() for line in proto_as_ascii: if line.startswith(' target_class:'): target_class = int(line.split(': ')[1]) if line.startswith(' target_class_string:'): target_class_string = line.split(': ')[1] node_id_to_uid[target_class] = target_class_string[1:-2] # Loads the final mapping of integer node ID to human-readable string node_id_to_name = {} for key, val in node_id_to_uid.items(): if val not in uid_to_human: tf.logging.fatal('Failed to locate: %s', val) name = uid_to_human[val] node_id_to_name[key] = name return node_id_to_name def id_to_string(self, node_id): if node_id not in self.node_lookup: return '' return self.node_lookup[node_id] # 从protocol buffer文件中反序列化出inception-v3模型及参数 def create_graph(): # Creates graph from saved graph_def.pb. with tf.gfile.FastGFile(os.path.join( FLAGS.model_dir, 'classify_image_graph_def.pb'), 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def, name='') # 使用v3模型对image图片进行分类,并输出top5置信度的类别预测 def run_inference_on_image(image): if not tf.gfile.Exists(image): tf.logging.fatal('File does not exist %s', image) image_data = tf.gfile.FastGFile(image, 'rb').read() # Creates graph from saved GraphDef. create_graph() with tf.Session() as sess: # Some useful tensors: # 'softmax:0': A tensor containing the normalized prediction across # 1000 labels. # 'pool_3:0': A tensor containing the next-to-last layer containing 2048 # float description of the image. # 'DecodeJpeg/contents:0': A tensor containing a string providing JPEG # encoding of the image. # Runs the softmax tensor by feeding the image_data as input to the graph. softmax_tensor = sess.graph.get_tensor_by_name('softmax:0') predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data}) predictions = np.squeeze(predictions) # Creates node ID --> English string lookup. node_lookup = NodeLookup() top_k = predictions.argsort()[-FLAGS.num_top_predictions:][::-1] for node_id in top_k: human_string = node_lookup.id_to_string(node_id) score = predictions[node_id] print('%s (score = %.5f)' % (human_string, score)) # 下载模型存档并解压 def maybe_download_and_extract(): dest_directory = FLAGS.model_dir if not os.path.exists(dest_directory): os.makedirs(dest_directory) filename = DATA_URL.split('/')[-1] filepath = os.path.join(dest_directory, filename) if not os.path.exists(filepath): def _progress(count, block_size, total_size): sys.stdout.write(' >> Downloading %s %.1f%%' % ( filename, float(count * block_size) / float(total_size) * 100.0)) sys.stdout.flush() filepath, _ = urllib.request.urlretrieve(DATA_URL, filepath, _progress) print() statinfo = os.stat(filepath) print('Successfully downloaded', filename, statinfo.st_size, 'bytes.') tarfile.open(filepath, 'r:gz').extractall(dest_directory) def main(_): maybe_download_and_extract() image = (FLAGS.image_file if FLAGS.image_file else os.path.join(FLAGS.model_dir, 'cropped_panda.jpg')) run_inference_on_image(image) if __name__ == '__main__': parser = argparse.ArgumentParser() # classify_image_graph_def.pb: # Binary representation of the GraphDef protocol buffer. # imagenet_synset_to_human_label_map.txt: # Map from synset ID to a human readable string. # imagenet_2012_challenge_label_map_proto.pbtxt: # Text representation of a protocol buffer mapping a label to synset ID. parser.add_argument( '--model_dir', type=str, default='/tmp/imagenet', help=""" Path to classify_image_graph_def.pb, imagenet_synset_to_human_label_map.txt, and imagenet_2012_challenge_label_map_proto.pbtxt. """ ) parser.add_argument( '--image_file', type=str, default='', help='Absolute path to image file.' ) parser.add_argument( '--num_top_predictions', type=int, default=5, help='Display this many predictions.' ) FLAGS, unparsed = parser.parse_known_args() tf.app.run(main=main, argv=[sys.argv[0]] + unparsed) |
运行效果如下:

图4 运行结果
简要分析下吧。程序使用InceptionV3的存档模型对一张可爱的滚滚(熊猫)图片进行识别。结果显示该图片属于panda的概率为89.1%,Indir的概率为0.8%,lesser panda的概率为0.3%等等。
哈哈哈哈,当把照片换成我家小天使时。小家伙你也太鼠头鼠脑的了吧哈哈哈:

