一.简介和概述
主要版本:2.6.24
1.1内核任务
- 抽象计算机:抽象计算机硬件
- 资源管理:分配资源和保证完整性
- 库:系统调用
1.2实现策略
- 微内核
- 宏内核
1.3内核的组成部分
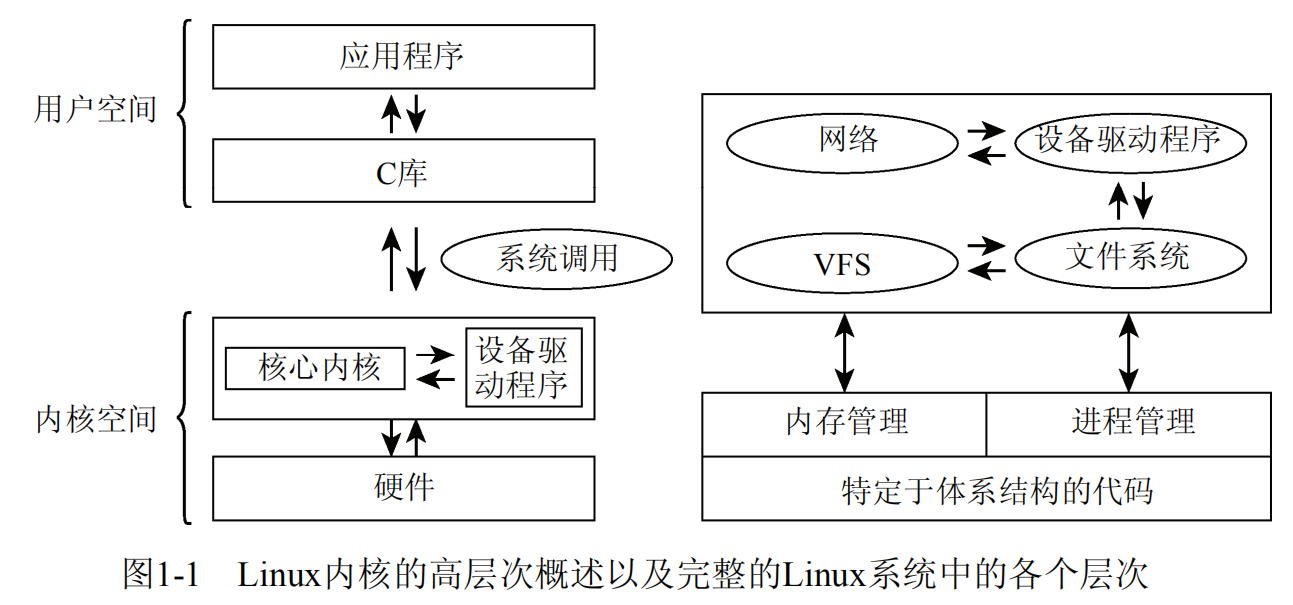
1.3.1 进程、进程切换、调度
通过虚拟技术,进程感觉自己是唯一的,内核保障这一点
内核保存、恢复进程状态,在切换时
内核保障进程共享CPU时间
1.3.2UNIX进程
init是第一个进程,负责进一步的系统初始化
新进程创建,两种方式:
- fork,cow,继承父进程内存,需要写的时候再复制内存
- exec,新程序,刷掉原程序内存页
1.线程
两种程序执行形式
- 重量级进程:UNIX进程
- 线程:轻量级线程
线程是与主程序并行的函数或者例程
clone方法创建线程
检查资源,哪些是线程独占哪些是与父进程共享
2.命名空间
全局资源分到不同的组
每个命名空间包含特定PID集合
通过成为容器的命名空间提供多个系统视图,多个容器实例虚拟化物理计算机(一个容器看起来就是一个真正的计算机,实际上是个假的虚拟计算机)
不是所有内核子系统都支持命名空间
1.3.3 地址空间与特权级别
用户空间虚拟地址范围:0~TASK_SIZE
1.特权级别:
禁止访问某些内存地址和使用某些汇编指令
通过系统调用完成状态转换,由系统检查权限后代替用户态应用执行某些操作
中断也可以完成状态转换,在中断上下文中执行,不能睡眠,不能访问普通进程的内存
内核线程也是运行在内核态,可睡眠但是不可访问用户数据
内核线程名字存在于方括号【】中,名字斜线后的数字表明内核线程绑定运行的CPU
2.虚拟和物理地址空间
页表将虚拟地址映射到物理地址
虚拟地址划分空间,物理地址寻找内存
- 页帧:物理内存
- 页:虚拟内存
1.3.4页表
页表:用来将虚拟地址空间映射为物理地址空间的数据结构
有些内存不需要页表项,压缩页表项数量大小,页表要分级
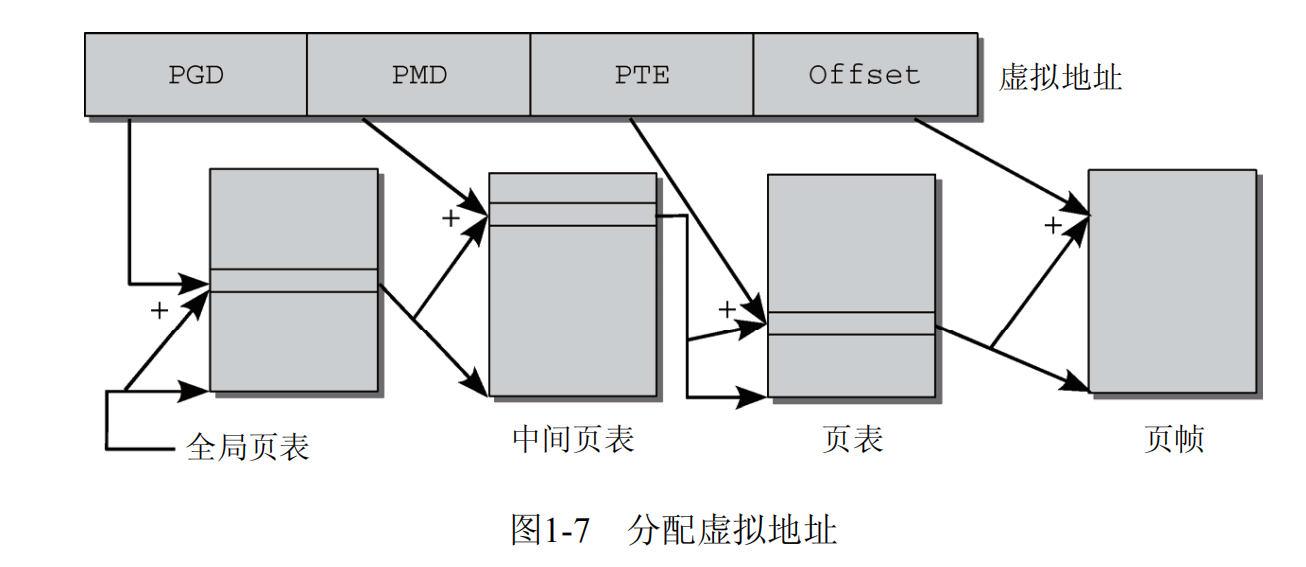
Linux用4级页表
优点:不需要映射的地址没有页表项
缺点:多级转换效率低
优化:MMU硬件优化和TLB缓存专门存放最频繁转换的地址群
页表内容变化要是TLB无效,使用CPU专用指令,硬件完成就是空指令
1.与CPU交互
CPU不支持多层页表需要Linux进行空页表仿真
2.内存映射
可以将任意内容映射到虚拟地址空间
1.3.5物理内存的分配
分配页帧速度要快,是大块分配
用户空间标准库进行小段分配
1.伙伴系统
为了分配连续页帧而存在
地址相邻空闲内存块两两作为伙伴,使用数组标记相同页帧数目的内存块。有空闲的时候两个伙伴就合并,链接到上一个大小数组项
伙伴系统用来控制内存碎片化
2.slab缓存
内核没有标准库管理内存,要用slab缓存管理伙伴系统的内存,分配小对象
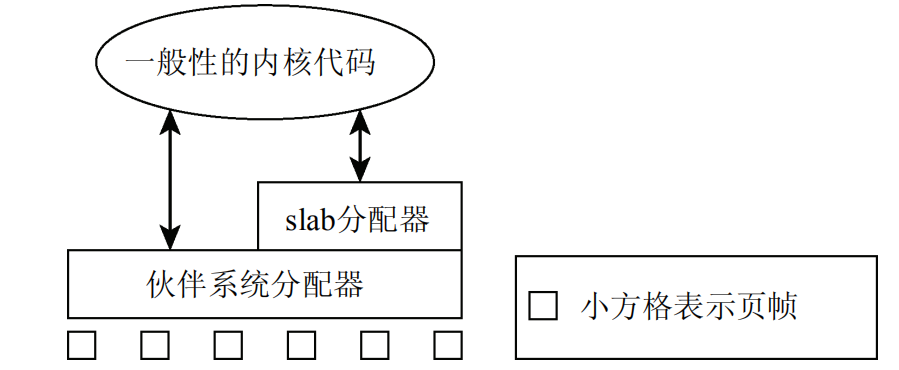
slab提供频繁使用对象的缓存和一般使用小对象的缓存(类似kmalloc和kfree)
3.页面交换和页面回收
页面交换:不常用内存放在外存,特殊标记,用到了产生缺页异常,内核自动载入
页面回收:被映射的内存与块设备同步。同步完了可以将该内存用作他用,需要再重新分配
1.3.6 计时
jiffies按照恒定的时间间隔自动递增
定时器中断更改jiffies数值
HZ决定jiffies递增数值
1.3.7 系统调用
系统调用大致分为以下组别:
- 进程管理
- 信号
- 文件
- 目录和文件系统
- 保护机制
- 定时器函数
有些功能只能内核做,所以没有用户空间库
1.3.8 设备驱动程序、块设备和字符设备
设备驱动通过设备文件完成用户空间程序与设备硬件通信
- 字符设备:顺序读写,按照字符流式读写,不能随机读取
- 块设备:按块读,可以随机寻址,不支持按照字符寻址
块设备设计缓存机制,复杂很多
1.3.9 网络
网卡不能利用设备文件直接访问,涉及到层层协议的封装、打包、解包
使用socket抽象作为应用、文件、内核实现间代理
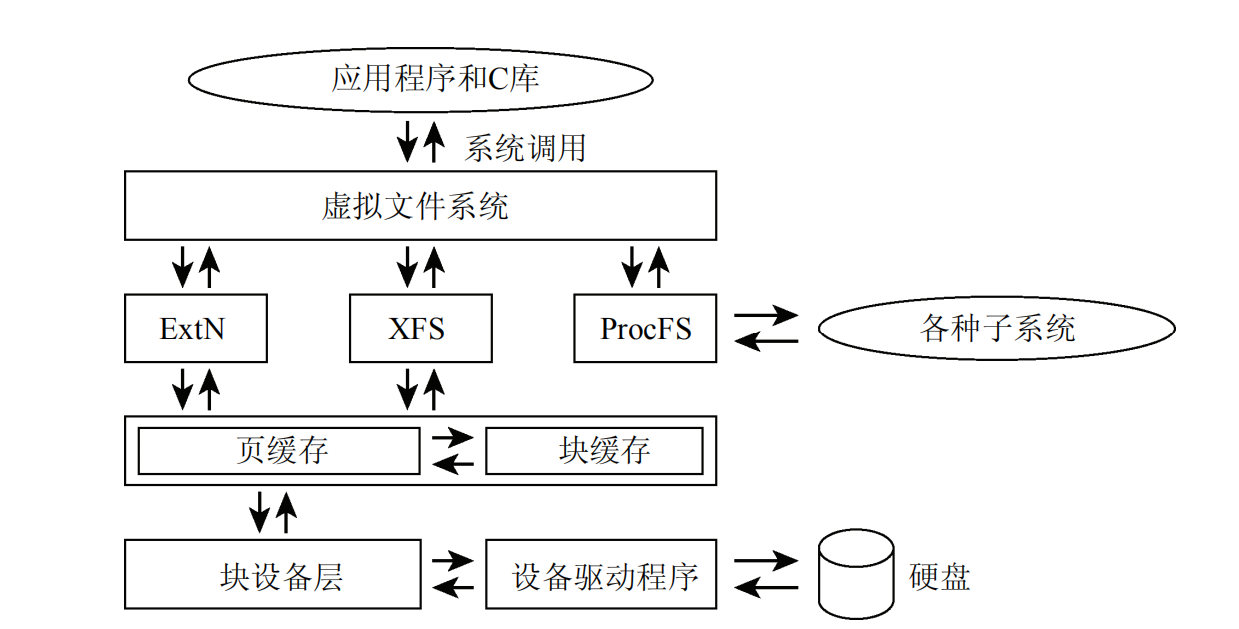
1.3.10 文件系统
存储使用了层次式文件系统
使用目录结构组织存储的数据,将元数据与数据本身通过关联
ext2中,文件inode存储数据地址和元信息,目录inode存储文件inode指针,层次由此形成
VFS是中间层,将文件系统和应用隔离开
所有文件系统要实现VFS的接口,应用程序通过VFS调用到底层文件系统
1.3.11 模块和热插拔
不膨胀内核,动态增加、删除驱动、协议
1.3.12 缓存
缓存按页组织,称为页缓存
页缓存替代了块缓存
缓存可以绕过低俗设备的限制
1.3.13 链表处理
双链表将任何类型的数据彼此链接起来
要被链接的数据类型,其内部要被嵌入一个叫做list_head的成员变量
LIST_HEAD 宏声明初始化链表头,链表头也是一个list_head类型
常用API:
- list_add
- list_add_tail
- list_empty
- list_entry
- list_del
- list_splice
- list_for_each
1.3.14 对象管理和引用计数
一般性的内核对象机制,进行以下操作:
- 引用技术
- 集合对象链表管理、
- 对象加锁
- 对象属性通过sysfs导出到用户空间
各个子系统中的对象通用
1.一般性内核对象
kobject对象嵌入替他对象,即可提供对象管理功能
kref管理引用计数
操作API:
- kobject_put/get
- kobject_init
- kobject_cleanup
- kobject_add
- kobject_registger/unregistger
2.对象集合
kset结构将不同对象通过链表链接在一起,提供sysfs共用操作,以及自身操作指针函数,本身也通过kobject管理
kobj_type提供sysfs接口
3.引用计数
提供kobject_init,kobject_put,kobject_get等原子操作
1.3.15 数据类型
1.类型定义
为适配不同体系结构,用typedef自定义类型,并且类型数据不能直接操作,要用提供的函数,防止没搞清类型误操作
2.字节序
cpu_to_le64和le64_to_cpu将数据转为小端,小端转为大端,本身是小端则为空操作
3.per_cpu变量
每个CPU都分配的一个变量
DEFINE_PER_CPU定义该变量
get_cpu获取该变量
smp_processor_id获取cpu id
多核同时读取一个变量,可以不用在缓存间转移
4.访问用户空间
__user标记指针指向的是用户空间的虚拟地址,不要轻易访问
1.3.16 本书的局限性
只是讲解了共性问题
1.4 为什么内核是特别的
使用非常干净的抽象设计,保证内核的模块化和易管理性
为了性能、兼容性、并发性,有很多magic代码
1.5 行文注记
自顶向下介绍,先概念,再数据结构,最后代码
代码分析省略细节、次要任务,阐述主题
1.6 小结
已给出内核全局图景,包括各部职责分配、所处理问题、组件交互
二. 进程管理和调度
内核和处理器建立多任务的错觉,是通过在短时间内切换任务执行做到的
进程管理带来两个问题:
- 隔离资源
- 调度公平
调度主要有两个方面
- 调度策略,与平台无关
- 进程场景切换
2.1 进程优先级
分为实时进程与非实时进程
- 硬实时进程
为保证响应时间,以下策略:
-
- 可抢占的内核机制
- 实时互斥量
- 全完公平调度器
- 软实时进程
- 普通进程,有优先级
抢占式多任务处理:
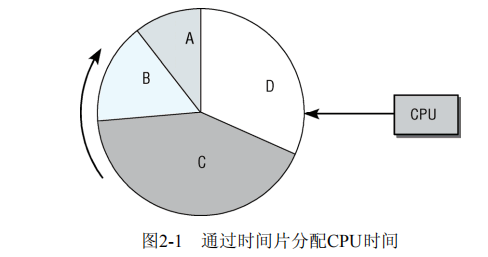
要考虑进程状态是否是可运行的,进程分为是否实时,是否可抢占
完全公平调度器取代了之前的调度器,也可以先分配用户时间再分配进程时间
2.2 进程生命周期
进程如果在等待外部事件,则调度运行也没有意义
进程状态有:
- 运行
- 等待
- 睡眠(分为可否被信号中断)
- 终止
- 僵尸(只收到信号SIGTERM、SIGKILL,但是父进程没有调用wait4向内核确认删除,所以还有进程表项)
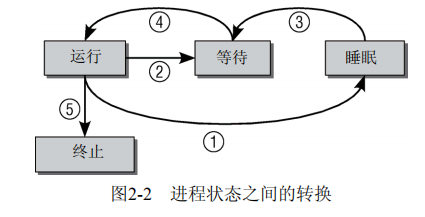
进程还有两种状态
- 用户态
- 核心态
通过系统调用、中断转变状态
可抢断进程调度分三层:
- 普通进程,可以被随便抢占
- 在处理系统调用的内核状态(重要内核操作可以禁止中断发生),中断可以抢占
- 中断,执行时间要短
内核抢占选项:支持系统调用内核态被普通进程抢占,进程执行更平滑
2.3 进程表示
linux/sched.h里,task_struct用来表示进程
进程和其他子系统的联系基本都在这个数据结构中
包含的信息很多,主要可以分类如下:
- 状态和执行信息,比如PID,待决信号,父进程(还有其他相关进程),优先级,文件格式,CPU使用时间等
- 已分配的虚拟内存信息
- 进程身份凭据,比如UID、GID、权限
- 所处理文件的文件系统信息、二进制执行相关文件信息
- 线程信息(与绑定的CPU有关)
- IPC信息
- 信号处理相关
state指定进程状态,有以下值:
TASK_RUNNING:可运行状态
TAST_INTERRUPTIBLE:等待外部事件或资源而睡眠,可被唤醒
TASK_UNINTERRUPTIBLE:被内核主动沉睡,不可唤醒,只能内核自己唤醒
TASK_STOPPED:停止运行,比如因调试而暂停
TASK_TRACED:用来区分被ptrace跟踪的进程和普通停止运行进程
EXIT_ZOMBIE:僵尸态进程,没有父进程调用wait4
EXIT_DEAD:wait4已发出,等待被释放的进程。主要应对多个wait4调用
Resouce Limit:限制进程相关资源,放在一个数组里,索引就是资源项ID

分为软限制和硬限制,current是软限制,max是硬限制

无限制为RLIM_INFINITY
init进程的限制为INIT_RLIMITS
/proc/self/limits可查看本进程限制
2.3.1 进程类型
典型的包括:二进制代码、线程、资源(文件、内存、信号量、锁等)
复制进程API:
fork:当前进程副本,cow技术优化
exec:不会新增进程,替换代码
clone:不是独立的进程,有些资源共享,可用来创建线程
2.3.2 命名空间
1.概念
轻量级虚拟化技术,一些资源隔离的就像在不同计算机,一些资源共享(比如文件)
一个内核就可以完成虚拟资源配置,不同用户跑在同一个内核上却都以为自己是独一份
命名空间抽象全局资源
命名空间建立了系统的不同视图
一组进程可以放进一个容器中,每个同层级的容器是互相隔离的,互相不知道,就像一台真实的计算机,但是其在父空间中是共存的,在子空间中重新分配
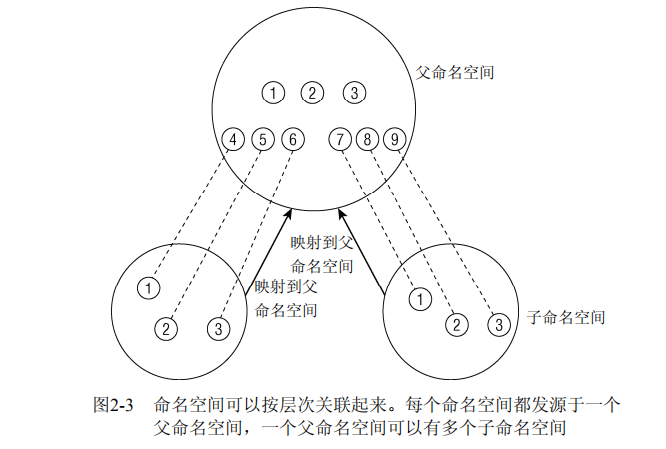
除了在全局空间外,其他资源在子空间中有一个自己的ID,可能与其他子空间的重复
命名空间比较简单的话可以是没有层级关系的,比如chroot
两种方法创建新的命名空间:
- 1.fork、clone添加参数
- 2.unshare将自己从父命名空间剥离
2.实现
struct nsproxy汇集了所有可以感知ns的子系统的命名空间指针,子系统包括:
- uts_ns
- ipc_ns
- mnt_ns
- pid_ns
- user_ns
- net_ns
要实现两个任务:
- 将全局资源映射到各个ns
- 将进程关联到各个ns
以下标志用来在fork的时候标识怎么创建命名空间

task_struct中包含到ns_proxy的指针

使用了指针,多个进程共享一个命名空间
int_nsproxy是初始的全局命名空间

UTS命名空间
包含了简单的系统信息


初始信息在init_unt_ns里

copy_utsname生成新的uts_namespace,这样保证了隔离,各个进程修改各自的,不会互相影响
用户命名空间
包括了用户相关进程的统计综合数据

每个用户空间都是统计自己相关用户的信息,互相不影响

2.3.3 进程ID号
fork和clone的时候生成pid
1.进程ID
id有:
- pid:标志进程
- tgid:线程组,一个组的id都是主线程的
- pgrp:进程组,一个组的id都是进程组长的,方便了发送信号
- session id:进程组会话id
各种id在各个命名空间可能重复,但是在全局空间、初始空间中唯一
定义位置:
全局pid和tgid直接在task_struct

session id在task_struct->signal->__session
pgrd id在task_struct->signal->__pgrp
2. 管理id
内核提供小型系统分配pid,并提供pid与task_struct查找功能与内核表现形式和用户空间可见形式转换的辅助函数
数据结构
pid命名空间定义如下:

child_repeater是子空间的init进程,level是子空间层级优先级,parent是父命名空间
struct upid:特定的命名空间中可见信息

struct pid:pid的内核表示

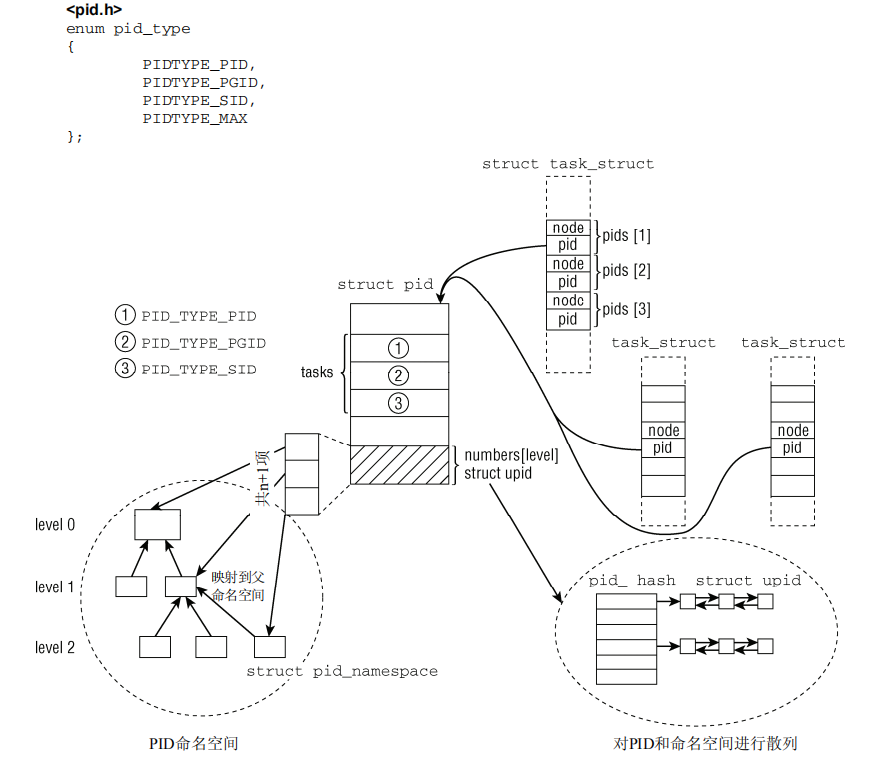
numbers形式上是一个元素,但是因为在尾部,可以无限扩容
共享同意ID的task_struct实例都挂在一个hlist散列表上



task_struct和pid发生关联建立双向连接

函数
通过task_struct找到id:




通过id找到task_struct


所有其他类型ID都可以映射到PID
3.生成唯一PID
分配PID就是在位图里找到第一个为0的然后置1


每一层ns都要生成一个pid,更新到相应upid中

每一层的 upid都要更新,并重新hash加入相应pid_hash中

2.3.4 进程关系
除了ID连接关系,还有父子、兄弟关系
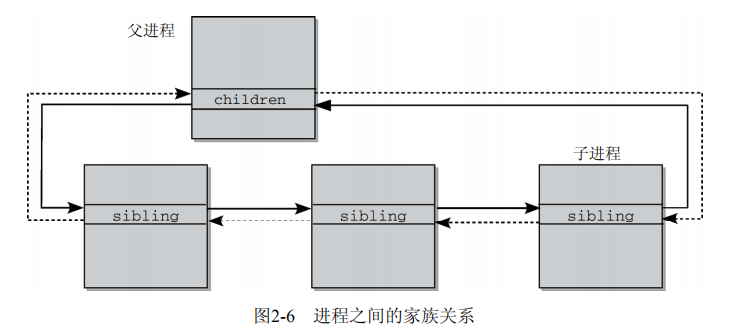

2.4 进程管理相关的系统调用
内核是由C标准库使用的工具库。
fork、exec系列系统调用一般有由C标准库调用
2.4.1 进程复制
3个api:
- fork:重量级复制,cow技术
- vfork:共享数据
- clone:精确控制复制
1.写时复制
进程经常访问的页的集合成为工作区
cow避免浪费内存和时间
只拷贝页表,设为只读
不能随便写彼此的页
父子进程写允许写的页报缺页错误
2.执行系统调用
fork、vfork、clonde的系统调用入口点sys_fork,sys_vfork,sys_clone最后都会调用do_fork函数

cow会分配栈副本
SIGCHLD标志:子进程结束向父进程发送进信号,fork默认标志
vork默认标志:CLONE_VFORK,CLONE_VM
clone根据用户标志传递
3.do_fork实现
与结构体系无关
4.复制线程
5.创建线程时的特别问题
2.4.2 内核线程
2.4.3 启动新程序
2.4.4 退出进程
2.5 调度器的实现
2.6 完全公平调度类
2.7 实时调度类
2.8 调度器增强
2.9 小结