注:初入职场,作为一个程序员,要融入项目组的编程风格,渐渐地觉得系统地研究下如何写出整洁而高效的代码还是很有必要的。与在学校时写代码的情况不同,实现某个功能是不难的,需要下功夫的地方在于如何做一些防御性的代码设计等,以使得自己写出的代码能够应对各种意外的情况。
BTW,通过阅读发现了“整洁代码之道”相关的几篇写得还不错的文章,挑出一些感兴趣的地方以提醒自己,提升代码的健壮性、高效性等。
(1)整洁代码之道——重构
(文章来源:http://www.infoq.com/cn/articles/clean-code-refactor 作者 )
写在前面
现在的软件系统开发难度主要在于其复杂度和规模,客户需求也不再像Winston Royce瀑布模型期望那样在系统编码前完成所有的设计满足用户软件需求。在这个信息爆炸技术日新月异的时代,需求总是在不断的变化,随之在2001年业界17位大牛聚集在美国犹他州的滑雪胜地雪鸟(Snowbird)雪场,提出了“Agile”(敏捷)软件开发价值观,并在他们的努力推动下,开始在业界流行起来。在《代码整洁之道》一书中提出:一种软件质量,可持续开发不仅在于项目架构设计,还与代码质量密切相关,代码的整洁度和质量成正比,一份整洁的代码在质量上是可靠的,为团队开发,后期维护,重构奠定了良好的基础。
接下来笔者将结合自己之前的重构实践经验,来探讨平时实际开发过程中我们注重代码优化实践细节之道,而不是站在纯空洞的理论来谈论代码整洁之道。
在具体探讨如何进行代码优化之前,我们首先需要去探讨和明确下何谓是“代码的坏味道”,何谓是“整洁优秀代码”。因为一切优化的根源都是来自于我们平时开发过程中而且是开发人员自己产生的“代码坏味道”。
代码的坏味道
“如果尿布臭了,就换掉它。”-语出Beck奶奶,论抚养小孩的哲学。同样,代码如果有坏味道了,那么我们就需要去重构它使其成为优秀的整洁代码。
谈论到何谓代码的坏味道,重复代码(Duplicated Code)首当其冲。重复在软件系统是万恶的,我们熟悉的分离关注点,面向对象设计原则等都是为了减少重复提高重用,Don’t repeat yourself(DRY)。关于DRY原则,我们在平时开发过程中必须要严格遵守。
其次还有其他坏味道:过长函数(Long Method)、过大的类(Large Class)、过长参数列表(Long Parameter List)、冗余类(Lazy Class)、冗余函数(Lazy Function)无用函数参数(Unused Function Parameter)、函数圈复杂度超过10(The Complexity is over 10)、依恋情结(Feature Envy)、Switch过多使用(Switch Abuse)、过度扩展设计(Over-extend design)、不可读或者可读性差的变量名和函数名(unread variable or function name)、异曲同工类(Alternative Classes with Different Interfaces)、过度耦合的消息链(Message Chains)、令人迷惑的临时字段(Temporary Field)、过多注释(Too Many Comments)等坏味道。
整洁代码
什么是整洁代码?不同的人会站在不同的角度阐述不同的说法。而我最喜欢的是Grady Booch(《面向对象分析与设计》作者)阐述:
“整洁的代码简单直接。整洁的代码如同优美的散文。整洁的代码从不隐藏设计者的意图,充满了干净利落的抽象和直截了当的控制语句。”
整洁的代码就是一种简约(简单而不过于太简单)的设计,阅读代码的人能很清晰的明白这里在干什么,而不是隐涩难懂,整洁的代码读起来让人感觉到就像阅读散文-艺术的沉淀,作者是精心在意缔造出来。
整洁代码是相对于代码坏味道的,如何将坏味道代码优化成整洁代码,正是笔者本文所探讨的重点内容:整洁代码之道-重构,接下来笔者将从几个角度重点描述如何对软件进行有效有技巧的重构。
重构 — Why
在软件开发过程中往往开发者不经意间就能产生代码的坏味道,特别是团队人员水平参差不齐每个人的经验和技术能力不同的情况下更容易产生不同阶段的代码坏味道。并且随着需求的迭代和时间推移,代码的坏味道越来越严重,甚至影响到团队的开发效率,那么遇到这个问题该如何去解决。
在软件开发Coding之前我们不可能事先了解所有的需求,软件设计肯定会有考虑不周到不全面的地方,而且随着项目需求的Change,很有可能原来的代码设计结构已经不能满足当前需求。
更何况,我们很少有机会从头到尾参与并且最终完成一个项目,基本上都是接手别人的代码,即使这个项目是从头参与的,也有可能接手团队其他成员的代码。我们都有过这样的类似的抱怨经历,看到别人的代码时感觉就像垃圾一样特别差劲,有一种强烈的完全想重写的冲动,但一定要压制住这种冲动,你完全重写,可能比原来的好一点,但浪费时间不说,还有可能引入原来不存在的Bug,而且,你不一定比原来设计得好,也许原来的设计考虑到了一些你没考虑到的分支或者异常情况。
我们写的代码,终有一天也会被别人接手,很可能到时别人会有和我们现在一样的冲动,所以开发者在看别人代码时候,要怀着一颗学习和敬畏之心,去发现别人的代码之美,在这个过程中挑出写的比较好的优秀代码,吸取精华,去其糟粕,在这个基础上,我们再去谈重构,那么你的重构会是一个好的开端。
总之,我们要做的是重构不是重写,要先从小范围的局部重构开始,然后逐步扩展到整个模块。
重构 — 作用
重构,绝对是软件开发写程序过程中最重要的事之一。那么什么是重构,如何解释重构。名词:对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。动词:使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
重构不只可以改善既有的设计结构,还可以帮助我们理解原来很难理解的流程。比如一个复杂的条件表达式,我们可能需要很久才能看明白这个表达式的作用,还可能看了好久终于看明白了,过了没多长时间又忘了,现在还要从头看,如果我们把这个表达式运用Extract Method抽象出来,并起一个易于理解的名字,如果函数名字起得好,下次当我们再看到这段代码时,不用看逻辑我们就知道这个函数是做什么的。
如果对这个函数内所有难于理解的地方我们做了适当的重构,把每个细小的逻辑抽象成一个小函数并起一个容易理解的名字,当我们看代码时就有可能像看注释一样,不用再像以前一样通过看代码的实现来猜测这段代码到底是做什么的,我一直坚持和秉持这个观点:好的代码胜过注释,毕竟注释还是有可能更新不及时的,不及时最新的注释容易更其他人带来更多的理解上的困惑。
此外重构可以使我们增加对代码和业务逻辑功能的理解,从而帮助我们找到Bug;重构可以帮助我们提高编程速度,即重构改善了程序结构设计,并且因为重构的可扩展性使添加新功能变得更快更容易。
重构 — 时机
理解了重构的意义和作用,那么我们何时开始重构呢?笔者一直坚持这种观点:重构是一个持续的系统性的工程,它是贯穿于整个软件开发过程中,我们无需专门的挑出时间进行重构,重构应该随时随地的进行,即遵循三次法则:事不过三,三则重构。这个准则表达的意思是:第一次去实现一个功能尽管去做,但是第二次做类似的功能设计时会产生反感,但是还是会去做,第三次还是实现类似的功能做同样的事情,那你就应该去重构。三次准则比较抽象,那么对应到我们具体的软件开发流程中,一般可以在这三个时机去进行:
(1) 当添加新功能时如果不是特别容易,可以通过重构使添加特性和新功能变得更容易。在添加新功能的时候,我们就先清理这个功能所需要的代码。花一点时间,用滴水穿石的方法逐渐清理代码,随着时间的推移,我们的代码就会越来越干净,开发速度也会越来越快。
(2) 修改Bug的时候去重构,比如你在查找定位Bug的过程中,发现以前自己的代码或者别人的代码因为设计缺陷比如可扩展性、健壮性比较差造成的,那么此时就是一个比较好的重构时机。可能这个时候很多同学就有疑问了,认为我开发要赶进度,没有时间去重构,或者认为我打过补丁把Bug解决不就行了,不需要去重构。根据笔者之前多年的经验得出的结论:遇到即要解决即那就是每遇到一个问题,就马上解决它,而不是选择绕过它。完善当前正在使用的代码,那些还没有遇到的问题,就先不要理它。在当前前进的道路上,清除所有障碍,以后你肯定还会再一次走这条路,下次来到这里的时候你会发现路上不再有障碍。
软件开发就是这样。或许解决这个问题需要你多花一点时间。但是从长远来看,它会帮你节省下更多的时间。也就是重构是个循序渐进的过程,经过一段时间之后,你会发现之前所有的技术债务会逐步都不见了,所有的坑相继都被填平了。这种循序渐进的代码重构的好处开始显现,编程的速度明显会加快。
(3)Code Review时去重构,很多公司研发团队都会有定期的Code Review,这种活动的好处多多,比如有助于在开发团队中传播知识进行技术分享,有助于让较有经验的开发者把知识传递给欠缺经验的人,并帮助更多的人对软件的其他业务模块更加熟悉从而实现跨模块的迭代开发。Code Review可以让更多的人有机会对自己提出更多优秀好的建议。同时重构可以帮助审查别人的代码,因为在重构前,你需要先阅读代码得到一定程度的理解和熟悉,从而提出一些建议和好的idea,并考虑是否可以通过重构快速实现自己的好想法,最终通过重构实践你会得到更多的成就感满足感。为了使审查代码的工作变得高效有作用,据我以前的经验,我建议一个审查者和一个原作者进行合作,审查者提出修改建议,然后两人共同判断这些修改是否能够通过重构轻松实现,如果修改成本比较低,就在Review的过程中一起着手修改。
如果是比较大型比较复杂的设计复查审核工作,建议原作者使用UML类序列图、时间序列图、流程图去向审查者展现设计的具体实现细节,在整个Code Review中,审查者可以提出自己的建议或者修改意见。在这种情景下,审查者一般由团队里面比较资深的工程师、架构师、技术专家等成员组成。
关于Code Review的形式,还可以采取极限编程中的“结对编程”形式。这种形式可以采取两个人位置坐在一起去审查代码,可以采取两个平台比如IOS 和android 的开发人员一起去审查,或者经验资深的和经验不资深的人员一起搭配去审查。
重构的这三个时机要把握好原则,即什么时候不应该重构,比如有时候既有代码实现太混乱啦,重构它还不如重新写一个来得简;此外,如果你的项目已经进入了尾期,此时也应该避免重构,这时机应该尽可能以保持软件的稳定性为主。
理解了重构是做什么,重构的作用,为什么要重构,以及重构的时机,我们对重构有了初步认识,接下来笔者重点篇幅来讲解如何使用重构技巧去优化代码质量达成Clean Code .
重构技巧 — 函数重构
重构的源头一切从重构函数开始,掌握函数重构技巧是重构过程中很关键的一步,接下来我们来探讨下函数重构有那些实用技巧。
-
重命名函数(Rename Function Name) : Clean Code要求定义的变量和函数名可读性要强,从名字就可以知道这个变量和函数去做什么事情,所以好的可读性强的函数名称很重要,特别是有助于理解比较复杂的业务逻辑。
-
移除参数(Remove Parameter): 当函数不再需要某个参数时,要果断移除,不要为了某个未知需求预留参数,过多的参数会给使用者带来参数困扰。
-
将查询函数和修改函数分离:如果某个函数既返回对象值,又修改对象状态。这时候应该建立两个不同的函数,其中一个负责查询,另一个负责修改。如果查询函数只是简单的返回一个值而没有副作用,就可以无限次的调用查询函数。对于复杂的计算也可以缓存结果。
-
令函数携带参数:如果若干函数做了类似的工作,只是少数几个值不同导致行为略有不同,合并这些函数,以参数来表达不同的值。
-
以明确函数取代参数:有一个函数其中的逻辑完全取决于参数值而采取不同行为,针对该参数的每一个可能值建立一个单独的函数。
-
保持对象完整性:如果你需要从某个对象取若干值,作为函数的多个参数传进去,特别是需要传入较多参数比如5个参数或者更多参数时,这种情况建议直接将这个对象直接传入作为函数参数,这样既可以减少参数的个数,增加了对象间的信赖性,而且这样被调用者需要这个对象的其他属性时可以不用人为的再去修改函数参数。
-
以函数取代参数:对象调用某个函数,并将所得结果作为参数传递给另外一个函数,而那个函数本身也能够调用前一个函数,直接让那个函数调用就行,可以直接去除那个参数,从而减少参数个数。
-
引入参数对象:某些参数总是同时出现,新建一个对象取代这些参数,不但可以减少参数个数,而且也许还有一些参数可以迁移到新建的参数类中,增加类的参数扩展性。
-
移除设值函数(Setting Method):如果类中的某个字段应该在对象创建时赋值,此后就不再改变,这种情景下就不需要添加Setting method。
-
隐藏函数:如果有一个函数从来没有被其他类有用到,或者是本来被用到,但随着类动态添加接口或者需求变更,之后就使用不到了,那么需要隐藏这个函数,也就是减小作用域。
-
以工厂函数取代构造函数:如果你希望创建对象时候不仅仅做简单的构建动作,最显而易见的动机就是派生子类时根据类型码创建不同的子类,或者控制类的实例个数。
重构技巧 — 条件表达式
-
分解条件表达式:如果有一个复杂的条件语句,if/else语句的段落逻辑提取成一个函数。
-
合并条件表达式:一系列条件测试,都得到相同的测试结果,可以将这些测试表达式合并成成一个,并将合并后的表达式提炼成一个独立函数,如果这些条件测试是相互独立不相关的,就不要合并。
-
合并重复的条件片段:在条件表达式的每个分支上有着相同的一段代码,把这段代码迁移到表达式之外。
-
移除控制标记:不必遵循单一出口的原则,不用通过控制标记来决定是否退出循环或者跳过函数剩下的操作,直接break或者return。
-
以卫语句替代嵌套条件表达式:条件表达式通常有两种表现形式,一:所有分支都属于正常行为;二:只有一种是正常行为,其他都是不常见的情况。对于一的情况,应该使用if/else条件表达式;对于二这种情况,如果某个条件不常见,应该单独检查条件并在该条件为真时立即从函数返回,这样的单独检查常常被称为卫语句。
-
以多态取代条件表达式:如果有个条件表达式根据对象类型的不同选择而选择不同的行为,将条件表达式的每个分支放进一个子类内的覆写函数中,将原始函数声明为抽象函数。
-
引入Null对象:当执行一些操作时,需要再三检查某对象是否为NULL,可以专门新建一个NULL对象,让相应函数执行原来检查条件为NULL时要执行的动作,除NULL对象外,对特殊情况还可以有Special对象,这类对象一般是Singleton.
-
引入断言:程序状态的一种假设
-
以MAP取代条件表达式:通过HashMap的Key-Value键值对优化条件表达式,条件表达式的判断条件作为key值,value值存储条件表达式的返回值。
-
通过反射取代条件表达式:通过动态反射原理
重构技巧 — 案例
Map去除if条件表达式
关于该技巧的实现方法,上章节有讲述,我们直接看代码案例如下代码所示:
原始的条件表达式代码如下图1所示:
public static int getServiceCode(String str){
int code = 0;
if(str.equals("Age")){
code = 1;
}else if(str.equals("Address")){
code = 2;
}else if(str.equals("Name")){
code = 3;
}else if(str.equals("No")){
code = 4;
}
return code;
}
重构后的代码如下所示:
public static void initialMap(){
map.put("Age",1);
map.put("Address",2);
map.put("Name",3);
map.put("No",4);
}
上述代码是直接通过Map结构,将条件表达式分解, Key 是条件变量,Value是条件表达式返回值。取值很方便,显然高效率O(1)时间复杂度取值。这种重构技巧适合于比较简单的条件表达式场景,下面是比较复杂的没有返回值的条件表达式场景,我们去看看如何处理。
反射去除分支结构
原始的条件表达式代码如下图1所示:
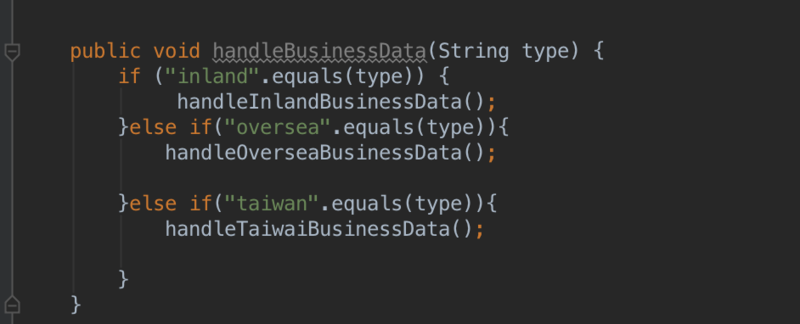
图1 条件表达式示范

图2 通过Map和反射重构示范
如上图2所示,通过Map和反射去分解条件表达式,将条件表达式分支的逻辑抽取到子类中的覆写函数中,提取了共同的抽象类,里面包含抽象接口 handleBusinessData,子类继承实现它。
多态取代条件表达式
图3 重构后的案例结果图

图4 重构后的案例-多态如何使用

图5 重构后的代码结构图
(点击放大图像)

图6 重构-抽象类、简单工厂模式思想去实现条件表达式的分解
如上图6所示,在原始的条件表达式中,有两个条件表达式分支(分支逻辑):
-
中文入住人操作HotelCNPasserngerOperaton类
-
英文入住人操作HotelEnPassengerOperation 类
共同抽取了基类抽象类:AbstractPassengerOperation,其两个分支子类去继承抽象类。
为了分解条件表达式,笔者采取了多态的重构技巧去实现,具体有两种实现方式,第一种实现方式是采用抽象类去实现多态,代码结构图如图5 passenger文件夹,UML类图如上图6所示。第二种实现方式是采用接口去实现多态,代码结构如图5 passenger2 文件夹,UML类图如上图7所示。

图7重构-接口状态者模式思想去实现条件表达式的分解
如上图7所示,在原始的条件表达式中,有两个条件表达式分支(分支逻辑),其分支逻辑分别放在了子类HotelCNPassengerState 和 HotelENPassengerState中,统一提取了接口类 PassengerState类,里面包含子类都需要实现的两个基础接口。从图7,可以看出,是使用了状态者模式。
经过了上述重构之后,我们达成了什么效果:
-
逻辑清晰
-
主逻辑代码行数减少
-
业务逻辑,更好的封装解藕,无需关注具体的业务细节
-
采用了多态、抽象、状态模式、工厂模式、Build模式的等不同的思想和方法,很多不同的重构技巧去重构一个功能,值得推广和借签;
(2)【读书笔记】--代码整洁之道
(文章来源:http://www.cnblogs.com/stoneniqiu/p/4815259.html 作者stoneniqiu)
“相对于任何宏伟景愿,对细节的关注甚至是更为关键的专业性基础。首先,开发者通过小型实践获得可用于大型实践的技能和信用度。其次,宏伟建筑中最细小的部分,比如关不紧的门,有点儿没有铺平的地板,甚至是凌乱的桌面,都会将整个大局的魅力毁灭殆尽。这就是整洁代码之所系”----没有比书中的这段话更能说明这本书的意义了。

《代码整洁之道》是第1期书山有路活动选出的读本。相对于记住那些如何写出整洁代码的那些法则,养成保持代码整洁、提高代码质量的习惯和思维更为重要。全书大致分为三个部分,第一部分1-10章都是介绍如函数、类、命名、单元测试等保持整洁的建议。第二部分11-13章从系统设计的层面提倡用AOP、IOC等方式保持整洁,或者合适的时候使用并发编程。第三部分14-17章以及后面的附录,作者以JAVA源码(全书都是以JAVA代码示例)来实际讲解如何保持整洁。
later equals never
我们都曾经瞟一眼自己亲手造成的混乱,决定弃之不顾,走向新的一天。我们都曾经看到自己的烂程序居然能运行,然后断言能运行的烂程序总比什么都没有强,我们都曾经说过有朝一日再回头清理。当然,在那些日子里。我们都没有听过布朗法则:later equals never 稍后等于永不.
ps:看到这句话确实有点惭愧。印象最深的感觉就是,我们去看一两年前自己的代码。那是写的什么玩意,真的是自己都看不下去。要让我改,我情愿再实现一个。所以时刻保持好的习惯是多么重要。不要想着以后再解决。就像领导说,这个事情以后再考虑,然后就没有然后了。
第一章 整洁代码
int d;// 消失的时间,以日计。 int elapsedTimeInDays;
2.避免误导。比如不是List类型,就不要用个accountList来命名,这样形成误导。
Public static void copyChars(char a1[],char a2[]){
for(int i=0;i<a1.length;i++)
{
a2[i]=a1[i];
} }
如果参数名称改为source和destination ,这个函数就会像样很多。废话都是冗余的,Variable一词 永远不应当出现在变量名中。Table一词永远不应当出现在表名中。NameString 会比 Name好吗,难道Name 会是一个浮点数不成?如有一个Customer的类,有又一个CustomerObject的类。是不是就凌乱了。
4.使用便于搜索的的名称
单个字母或者数字常量是很难在一大堆文章中找出来。比如字母e,它是英文中最常用的字母。长名胜于短名称,搜得到的名称胜于自编的名称。 窃以为单字母的名称仅用于短方法中的本地变量。名称长短应与其作用域大小相对应。
// returen an instance of the Responder being tested protected abstract Responder responderInstance();
不过作者认为将函数名重新命名为 responderBeingTested,注释就是多余的。
assertTrue(bb.compareTo(ba)==1);//bb>aa assertTrue(a.compareTo(b)==-1);//a<b
直接看方法可能不明确,但有注释就明白多了。我看这2,3,4都是一个意思。就是说明是干嘛的。
5.警示,告诉别人要注意这个方法之类的。
6.放大。有的代码可能看着有点多余,但编码者当时是有他自己的考虑,这个时候需要注释下这个代码的重要性。避免后面被优化掉。
第五章 格式
1.一行的长度,作者建议是上限是120个字符
PS 平时我们都是按照自己的屏幕大小来决定,当然太长了,自己也不便阅读,又不是压缩的js文件
a = b ;
第六章 对象和数据结构
2.德墨忒尔律:模块不应该了解它所操作对象内部情形。比如C的方法f只能调用以下对象的方法。
- C
- 由f创建的对象
- 作为参数传递给f的对象
- C的实体变量持有的变量
var outpath=cxt.getOptions().getScart().getAbsolutePath();
这个代码就违反了上面的德墨忒尔律,调用了返回值的方法。这样就是暴露了内部结构。
第七章 异常处理
1.try代码就像是事务,catch代码块将程序维持在一种持续状态。在编写可能抛出异常的代码时,最好先写出try-catch-finally 语句。
2.根据需要定义异常类。对错误分类的方式有多种,可以依据来源,是组件还是其他地方,或者依据类型,是设备错误还是网络错误。不过在我们定义异常类的时候,最重要的考虑是如何捕获它们。
3.别返回null值。程序中不断的看到检测null值的代码,一处漏掉检测就可能会失控。返回Null,作者认为这种代码很糟糕。建议抛出异常 或者返回特定对象(默认值)。更早的发现问题。同理,也应该避免传递Null值给其他的方法。
PS:在大多数的编程语言中,没有良好的方法能对付由调用者意外传入的null值。我们发布产品应该有容错的机制,程序不能轻易的就崩掉,有异常应该及时记录下来或给出提示。
第八章 边界
有时候我们在使用第三方程序包或者开源代码的时候,或者依靠公司其他团队的代码,我们都得干净利落的的整合进自己的代码中。这一章就是介绍保持保持软件边界整洁的实践手段和技巧。
1.对第三方进行学习性测试,当第三方程序包发布了新的版本,我们可以允许学习性测试,看看程序包的行为有没有发生改变。
- 除非这能让失败的单元测试通过,否则不允许去编写任何的生产代码。
- 只允许编写刚好能够导致失败的单元测试。 (编译失败也属于一种失败)
- 只允许编写刚好能够导致一个失败的单元测试通过的产品代码。
int size(); bool isEmpty();
这两个方法可以分别实现,但可以在isEmpty中使用size消除重复。
bool isEmpty(){
return size()==0;
}
不但是从代码行的角度,也要从功能上消除重复。
第十三章: 并发编程
并发是一种解耦策略,它帮助我们把做什么(目的)和何时(时机)做分解开。在单线程应用中,目的与时机紧密耦合,很多时候只要查看堆栈追踪即可断定应用程序的状态。而解耦目的与时机能明显地改进应用程序的吞吐量和结构。从结构的角度看,应用程序看起来更像是许多台协同工作的计算机,而不是一个大循环。单线程程序许多时间花在等待Web套接字I/O结束上面。
- 并发会在性能和编写额外代码上增加一些开销。
- 正确的并发是复杂的,即使对于简单的问题也是如此。
- 并发缺陷并非总能重现,所以常被看做偶发事件而忽略,而未被当做真的缺陷看待。
- 并发常常需要对设计策略的根本性修改。
一些基础定义:

在并发编程中用到的几种执行模型:
