接着上一节,继续计算神经网络的梯度。
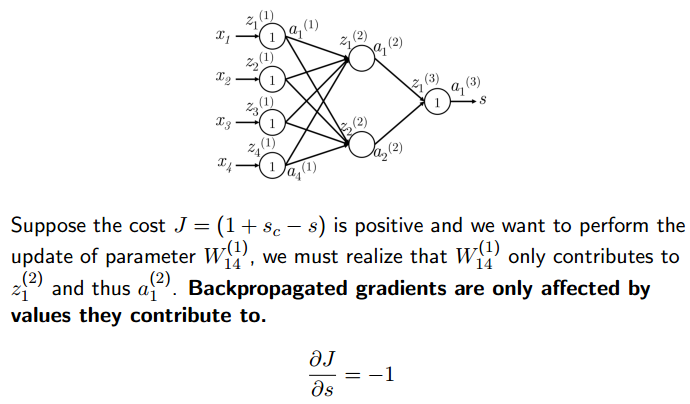
如上图所示,计算损失函数J对W14(1)的导数,这是为了更新W14(1)的值。

如上图所示,损失函数J就是S,S对W14(1)进行求导。首先看,W14(1)的变化导致了一号神经元的变化,而2号神经元没有发生变化。所以,对W14(1)的求导,与2号神经元没有关系,可以简化为上图中的下半部分。因此,s可表示为W1(2)与a1(2)的乘积。而W1(2)是个常数,可以提出。上图中的σ代表激活函数。最后的结果可表示为上节课最后所定义的δ函数。
那什么是δ呢?它是损失函数J对z的梯度,a4(1)是输入。
从误差分布的角度解释反向传播:

那从δ(k)到δ(k-1)是怎么传播的呢?如下图所示:

所谓的反向传播,其实质就是传播的误差。为什么是反向的?因为误差是从后往前计算的。就是从δ(k)到δ(k-1)的计算。
2. 常用的激活函数:
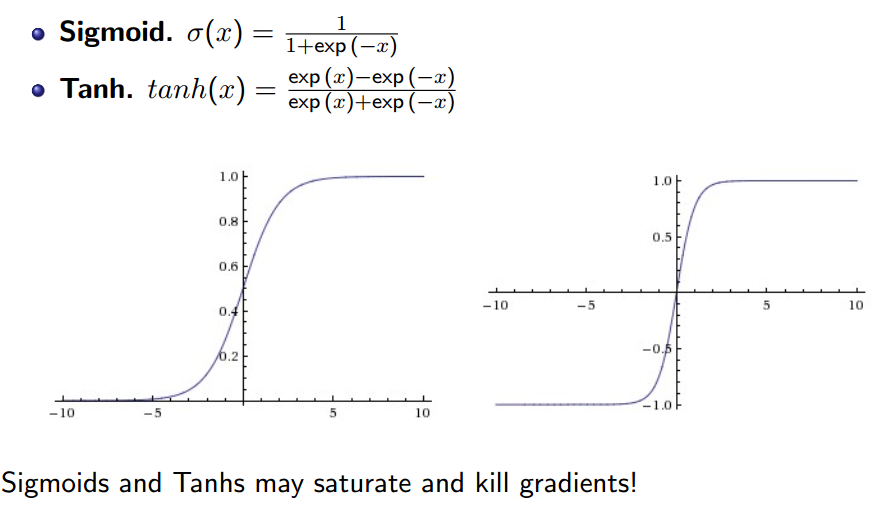
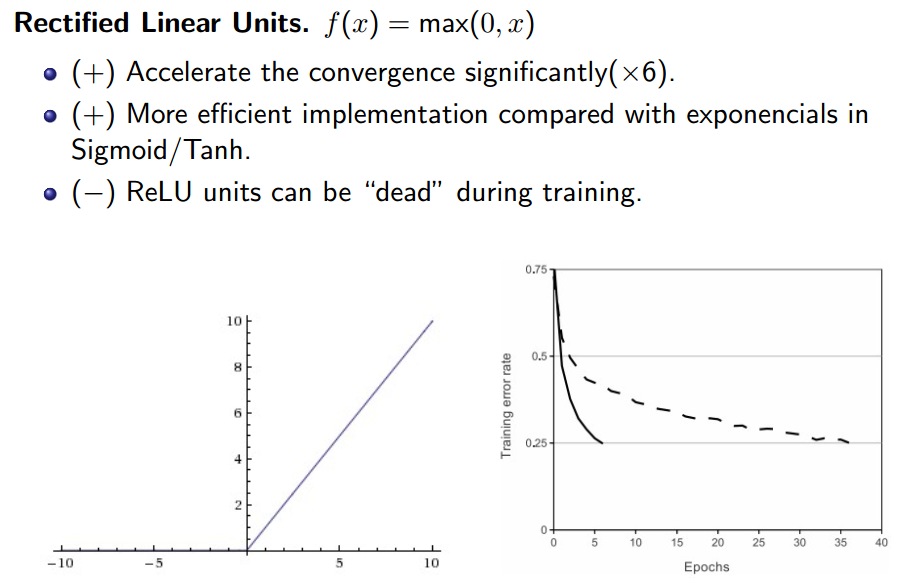
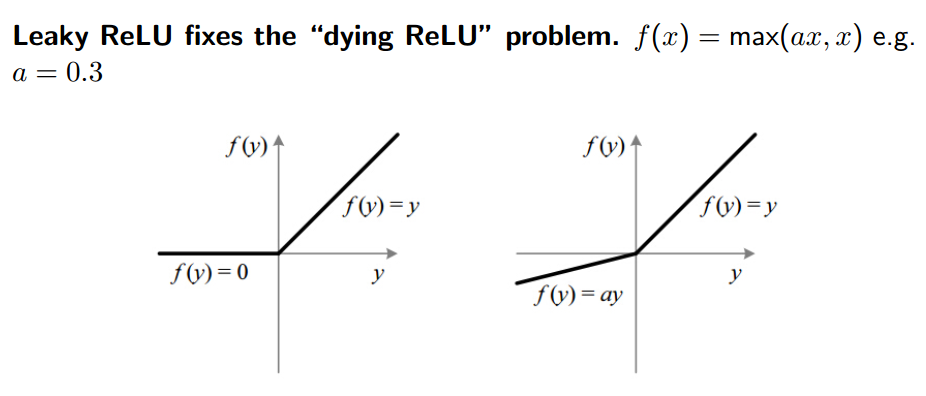
3.正则化:

正则化:将左边正常的神经网络中的一些神经元剔除掉,如果右边剩余的有缺失结构神经元还能够训练出不错的成绩和结果来,并且能够进行信息还原的话,那原网络有很大的鲁棒性,效果很好。
调参:
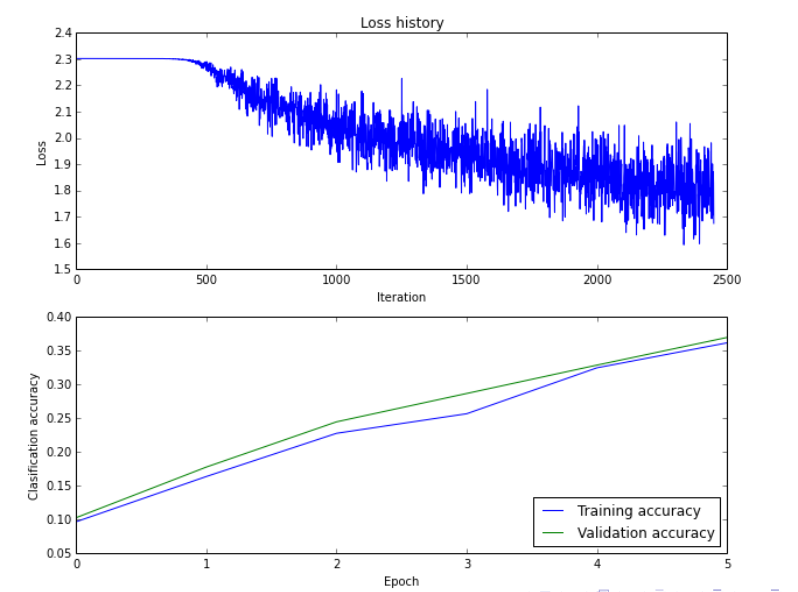
你训练完神经网络之后,会得到以上两幅图像。第一幅图是随着训练次数的增加,你的损失函数变化的关系。第二幅图是测试集和训练集分类准确率的关系。
那请问你如何根据上述两幅图调参?
首先,你希望你的损失函数是什么样的呢?你希望的肯定是下图总红色部分的形式,看着确实舒坦。
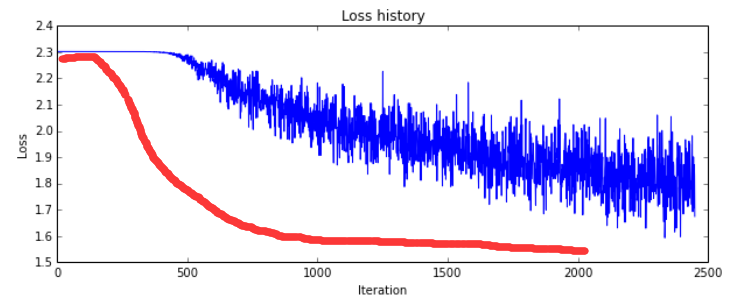
那如何把上述损失函数调到你所希望的形式呢?该调哪个参数呢?没错,调学习率。学习率调大还是调小呢?应该先调大后调小。如果你先调小,应该会使一开始更加的平缓,而不是更加的陡峭。后边调大的画会更加震荡,而我们后边要趋于平稳,所以后边应该调小。
那还应该调什么参数呢?你想想,震荡的原因是什么?是gradient不够稳定对吧。为什么不够稳定?是因为可能你对训练数据进行了采样,你没用到全部的训练数据。那batch_size(http://m.elecfans.com/article/566619.html)是调大还是调小呢?如果把整个数据集喂给它,那可能会趋于稳定了,所以应该把batch_size调大。可是实际情况下这很花钱的,靠GPU容量来称的。
那回到上边那幅图中的下半部分,是什么现象呢?是欠拟合现象。而不是过拟合。过拟合应该是对测试集结果表现不佳,而且两条线之间的差距比较大。欠拟合对训练数据就表现不佳,对测试集的效果和训练集的效果差不太大。那怎样解决欠拟合的问题呢?
有两种方法,一是说明你这个网络的表征能力不够强悍,你会换一个比较更厉害的特征提取的网络。第二个方法,说明你的训练数据不够,增大训练集,可是你要增加训练数据的话,你是要消耗更多的硬件gpu资源的,你的老板肯定不会同意的。在计算机视觉领域,有一种方法叫做数据增强,叫Data Augmentation(https://blog.csdn.net/l_xyy/article/details/71516071)就行啦,会使数据集猛然增强。