后台几个留言问:既然httprunner3这么多坑,为什么要学这个啊?
学这个不一定你熟练应用,但是要学习httprunner的设计思想。httprunner是兼容了pytest/json/yaml的。也就是目前比较火的框架基本都能用上,即使不会使用,也要了解到底是怎么回事。我的httprunner版本是3.1.6。
------------正文------------
.env文件的应用
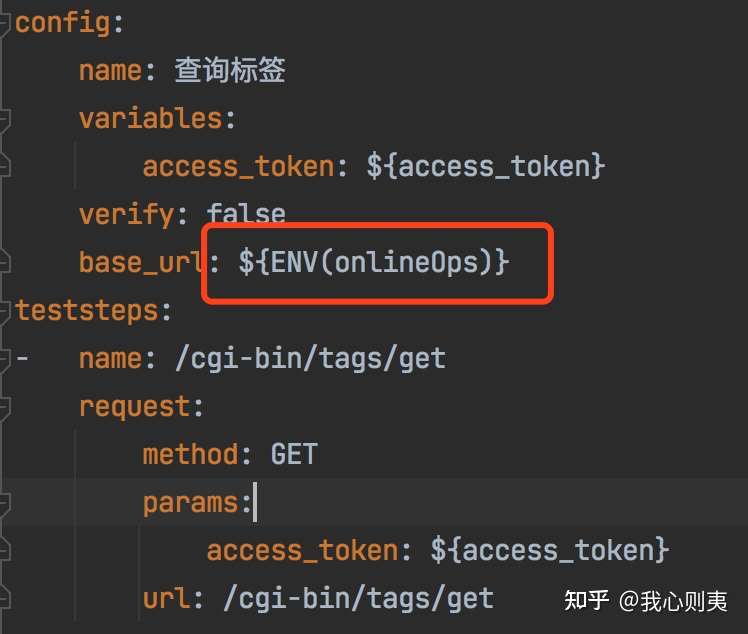
# .env文件 # onlineOps=192.168.0.1 # onlineOps=192.168.0.2 onlineOps=https://api.weixin.qq.com
我们将开发环境、测试环境、生产环境分别配置到.env文件中,然后再yaml文件通过${ENV(环境名)}进行引用。当需要修改环境的时候只需要去.env文件修改一下配置就可以了,不需要去动代码。
2、批量执行
之前我们执行的方式都是先转到对应的目录然后hrun执行单个yml文件
cd 文件夹
hrun -s xxx.yml
如果要批量执行可以新建一个all.py文件,然后通过命令执行
# coding: utf-8 import os if __name__ == '__main__': os.system("hrun testsuites/tags_suits.yml")
3、数据驱动
httprunner实现数据驱动必须要安装3.x版本。2.x版本没有实现数据驱动。
使用parameterize关键字定义数据源应用于测试套件层,只能是套件层!有两种方式实现数据驱动:
方式一:直接在套件脚本里指定参数列表
当数据量比较小的时候,可以直接在脚本里指定参数列表,实现数据驱动。
在执行的时候看不到输出,很头疼,改一下all.py,增加一个生成报告:
all.py文件
# coding: utf-8 import os if __name__ == '__main__': os.system("hrun testsuites/tags_suits.yml --html=reports/report.html")
这样就可以在报告里查看返回值了。
在testsuites下面的文件里通过
parameters: grant_type-appid-secret: - ["数据","数据","数据"] - ["数据","数据","数据"]
实现数据驱动;注意变量名要跟parameters变量名一致。
tags_suits.yml文件
config:
name: 获取access_token
parameters:
grant_type-appid-secret:
- ["client_credential","wx4d8f7a501","d096e2数据改了哈246"]
- [ "","wx4d8f501","d096e22数据改了哈7246" ]
teststeps:
- name: 获取access_token
testcase: testcases/get_access_token_case_params.yml
get_access_token_case_params.yml文件
config:
name: get_access_token
teststeps:
- name: 获取access_token
api: api/get_access_token.yml
get_access_token.yml文件
这里要把variables取值改成去变量模式
config: name: 获取access_token variables: grant_type: $grant_type appid: $appid secret: $secret verify: False base_url: ${ENV(onlineOps)} teststeps: - name: /cgi-bin/token request: method: GET params: appid: $appid grant_type: $grant_type secret: $secret url: /cgi-bin/token extract: access_token: content.access_token
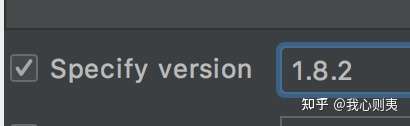
这里还有一个坑,就是你的pydantic版本要求是1.8.2的。一旦高于这个版本,数据就只能读取第一行了。这也是不管在用例文件还是CSV等做数据驱动时,用例数据只读取第一行数据的解决办法。
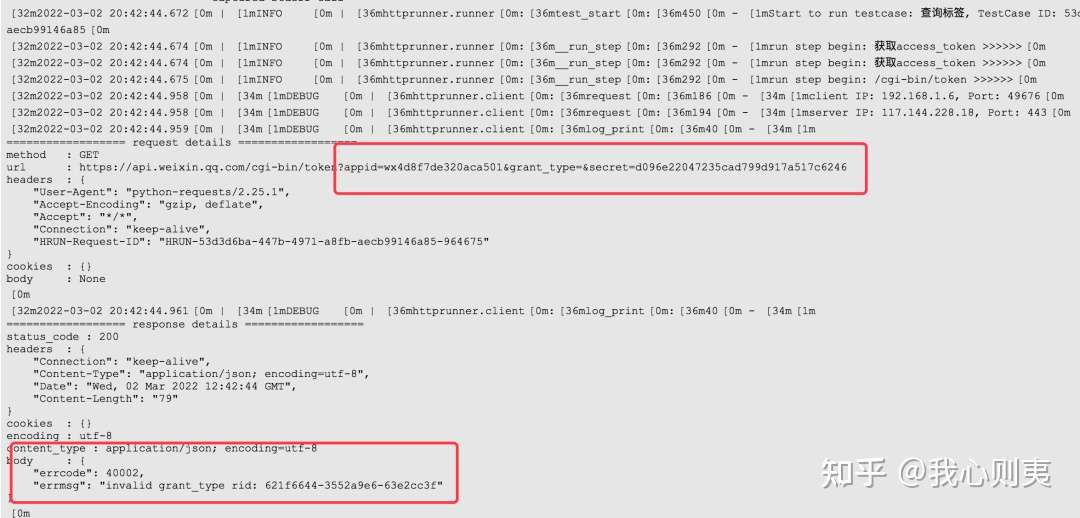
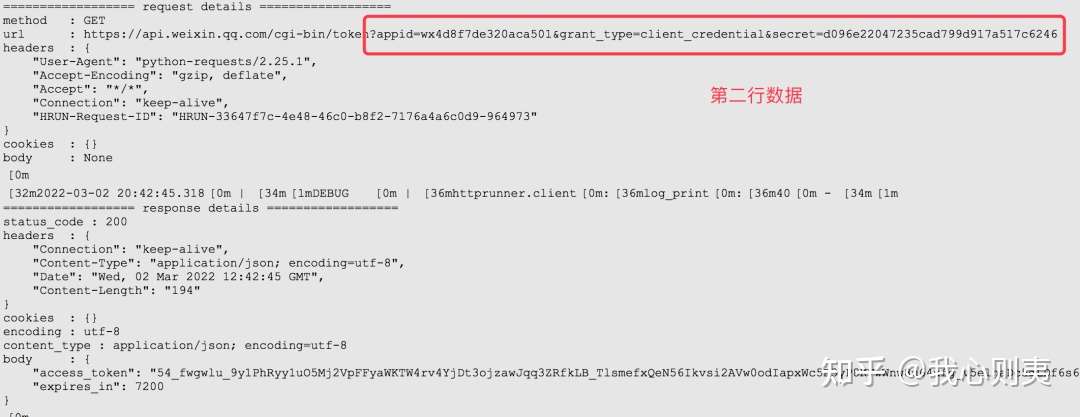
然后执行all.py文件,就可以在测试报告中看到结果了

点开下面Passed就能看到具体数据了
第二个
为了方便判断,我们加上断言
断言可以参考这里httprunner 3.x 入门 -1
这里断言比较适合用contains;断言既不能放到testsuites里也不能放在testcases里,放这两个任何一个都会报错,只能放在api文件夹下的对应文件里。
config: name: 获取access_token variables: grant_type: $grant_type appid: $appid secret: $secret verify: False base_url: ${ENV(onlineOps)} teststeps: - name: /cgi-bin/token request: method: GET params: appid: $appid grant_type: $grant_type secret: $secret url: /cgi-bin/token extract: access_token: content.access_token validate: - contains: - body - $assert_txt
我们在最后添加了包含断言。然后修改一下tags_suits.yml数据,变量之间加个 -
config: name: 数据驱动 parameters: grant_type-appid-secret-assert_txt: - ["","wx4d8appaca501","d096e2值9d917a517c6246",40002] - [ "client_credential","wx4d8ppaca501","d096e22047key246","access_token"] teststeps: - name: 获取access_token testcase: testcases/get_access_token_case_params.yml
这里还是有几个坑:
首先看一下接口文档的返回
{'errcode': 40002, 'errmsg': 'invalid grant_type rid: 621f8c59-2e45c94d-06149b34'}
可以看到40002是一个int类型,所以我在数据最后一个没有加双引号,这样做是没问题的。但是执行后仍然会报错
E httprunner.exceptions.ValidationFailure: assert body contains 40002(int) ==> fail E check_item: body E check_value: {'errcode': 40002, 'errmsg': 'invalid grant_type rid: 621f8c59-2e45c94d-06149b34'}(dict) E assert_method: contains E expect_value: 40002(int)
这是因为这个contains关键字也是有问题的,就像pydantic新版本有问题一样,这个关键字虽然判断是包含,但是它只能判断key值,不判断values值
所以只能判断那个key,第一组数据最后改成这样:
- ["","wx4d省略a501","d096e省略6246","errcode"]
再去执行就成功了。
方式二:使用CSV文件
这种方式也是用的比较多的
先在data文件夹新建一个get_token_data.csv文件,写用例数据
grant_type,appid,secret,assert_txt "client_credential","wx4d8省略a501","d096e2省略46","access_token" "","wx4d8省略501","d096e省略c6246","errcode"
注意
1、csv文件第一行必须放参数名称,并且参数名称必须和测试用例里面的名称一致;
2、csv第二行开始放数据,并且每一组数据占一行
3、tags_suits.yml文件里的parameters下的变量名顺序没有要求。
然后将tags_suits.yml文件改成调用CSV文件内容
config:
name: 获取access_token
parameters:
grant_type-appid-secret-assert_txt: ${P(data/get_token_data.csv)}
teststeps:
- name: 获取access_token
testcase: testcases/get_access_token_case_params.yml
${P(csv文件路径)}进行调用。P是大写的,代表parameterize,写${parameterize(csv文件路径)}也可以。get_access_token.yml文件内容不变
config: name: 获取access_token variables: grant_type: $grant_type appid: $appid secret: $secret verify: False base_url: ${ENV(onlineOps)} teststeps: - name: /cgi-bin/token request: method: GET params: appid: $appid grant_type: $grant_type secret: $secret url: /cgi-bin/token extract: access_token: content.access_token validate: - contains: - body - $assert_txt
执行一下也是通过的

方式三:使用函数生成数据
适用于数据变化比较大的情况,跟热加载差不多
我们这里举个简单的例子
我们在debugtalk.py文件新建一个方法:
def get_access_token(): return [ {"grant_type": "client_credential","appid": "wx4d8f7de320aca501", "secret": "d096e22047235cad799d917a517c6246", "assert_txt": "access_token"}, {"grant_type": "", "appid": "wx4d8f7de320aca501", "secret": "d096e22047235cad799d917a517c6246", "assert_txt": "errcode"} ]
为了方便大家看我都换行了。其实就是返回一个dict列表。然后修改一下tags_suits.yml文件变量调用${方法名()}这种就是热加载方式。config: name: 获取access_token parameters: grant_type-appid-secret-assert_txt: ${get_access_token()} # grant_type-appid-secret-assert_txt: ${parameterize(data/get_token_data.csv)} teststeps: - name: 获取access_token testcase: testcases/get_access_token_case_params.yml
执行以后也是成功的。
公众号:自动化测试实战