1.Action Recognition Using Local Visual Descriptors and Inertial Data
(pdf)[https://link.springer.com/chapter/10.1007/978-3-030-34255-5_9]
使用视觉和惯性数据来做动作识别
2.(Image representation of pose-transition feature for 3D skeleton-based action recognition)[https://www.sciencedirect.com/science/article/pii/S0020025519310151]
对3D骨架数据,使用两种方式来提取特征,一方面是:使用x,y,z每一个维度来度量各个点之间的距离信息,还有一个是使用角度来衡量点之间的关系,把这两个特征叠加一起。
综合的大F包括四个部分:【1.同一时间节点i和节点j之间的距离信息,2.相隔一帧,节点i和节点j之间的距离信息,3.同一时间节点i和节点j之间的角度信息,4.相隔一帧,节点i和节点j之间的角度信息】
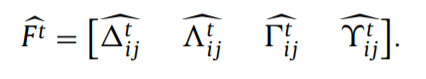
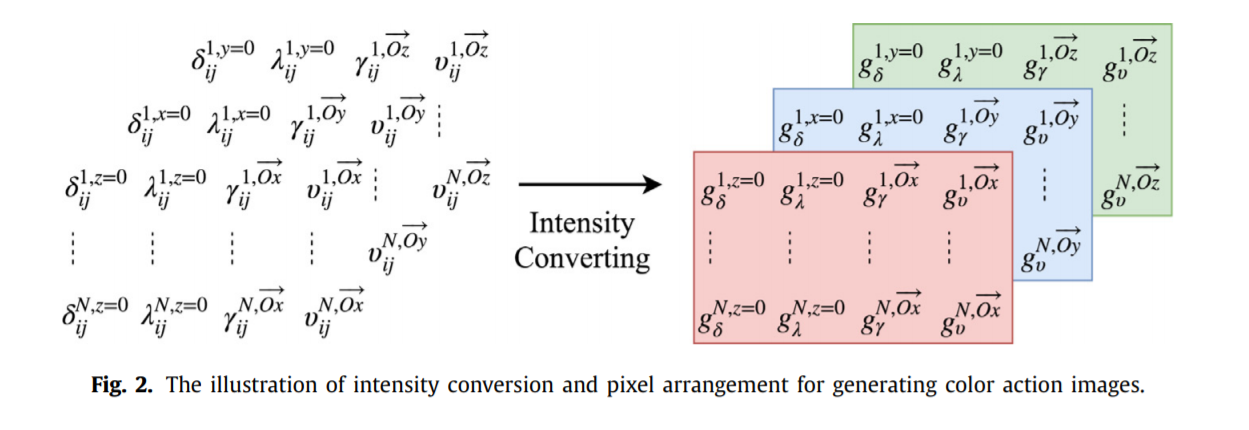
再在时间维度上,增加一个维度,就实现特征的提取
对这些信息,转化成对应XYZ的三个方向(“RGB”三色图)
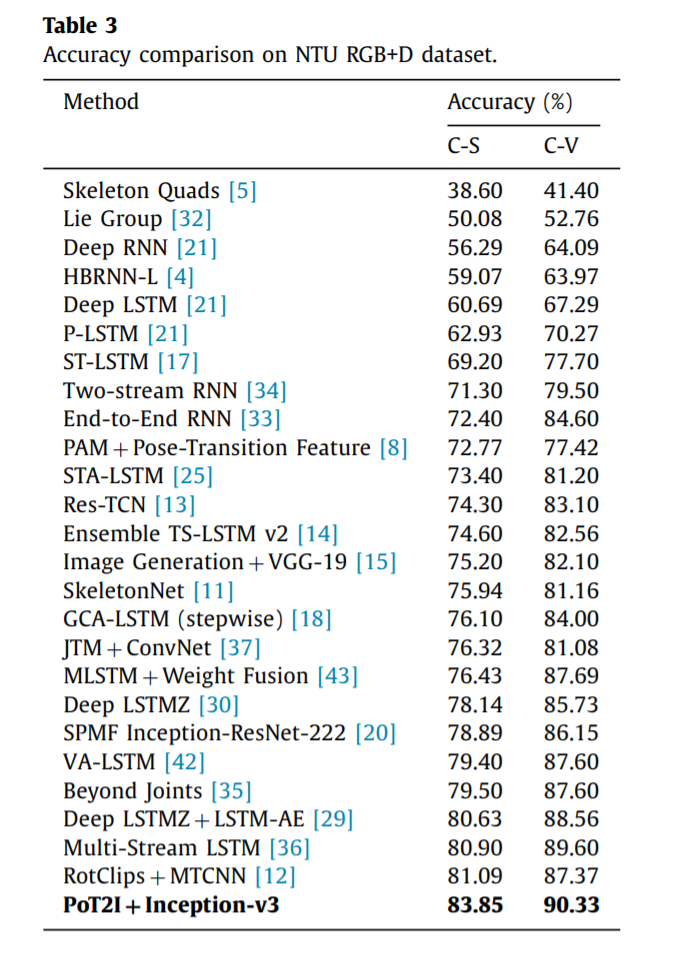
结果,实现83%和 90%
3.(Action recognition in freestyle wrestling using silhouette-skeleton features)[sciencedirect.com/science/article/pii/S2215098619303052]
主要是对两人格斗信息,进行分类。
读取图片,使用剪影提取图片的谷骨骼信息,骨骼映射在图像的格子上(bin),然后统计各个bin上面的条纹数量,从而用作分类的特征。
最后使用SVM分类。
4.(Using Aesthetics and Action Recognition-based Networks for
the Prediction of Media Memorability)[]
对于读取的TSN和I3D特征,采用其他组合的方法,再次利用起来。
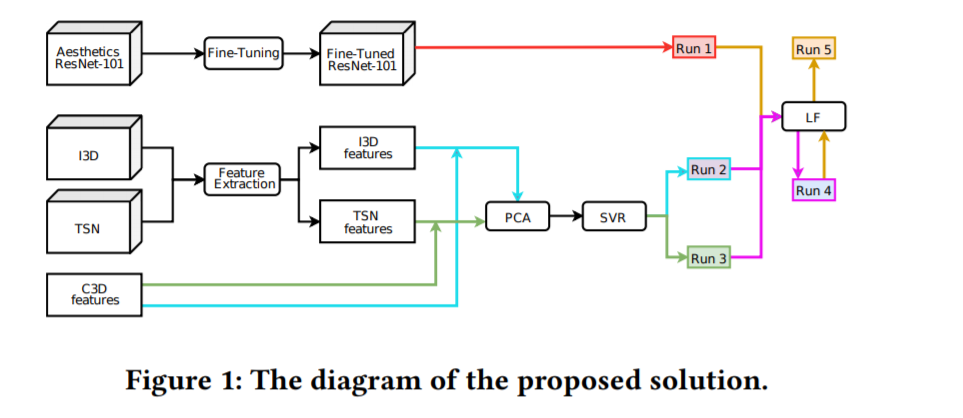
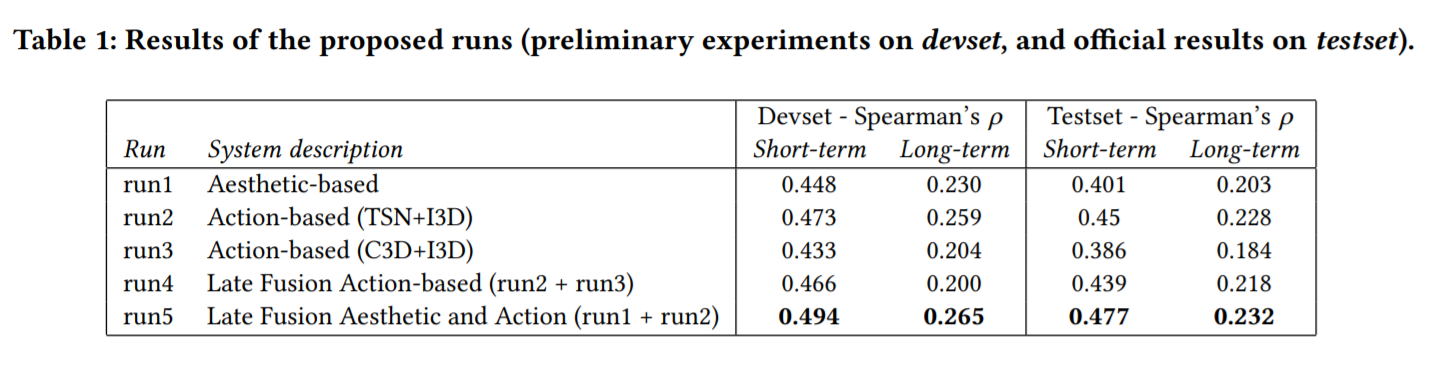
这个文章有点水,基本就是使用了一下原来的模型。
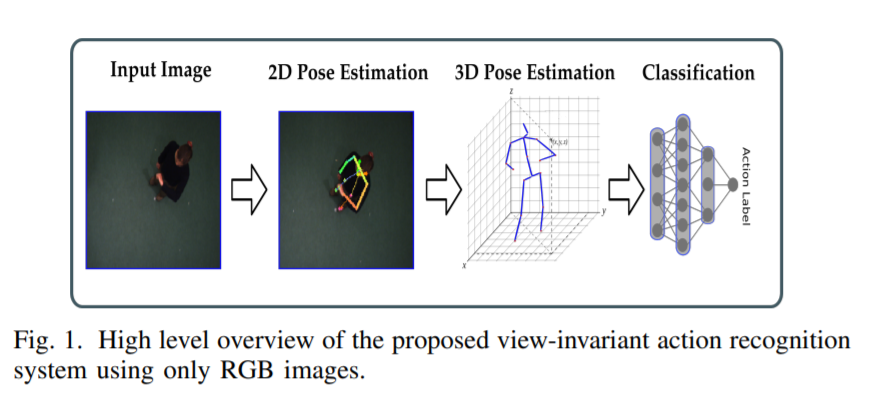
5.(Temporal 3D Human Pose Estimation for Action
Recognition from Arbitrary Viewpoints)[https://www.researchgate.net/publication/336891012_Temporal_3D_Human_Pose_Estimation_for_Action_Recognition_from_Arbitrary_Viewpoints]
从图片中提取二维骨架,然后估计3D骨架,最后使用TSN进行时间维度卷积操作。
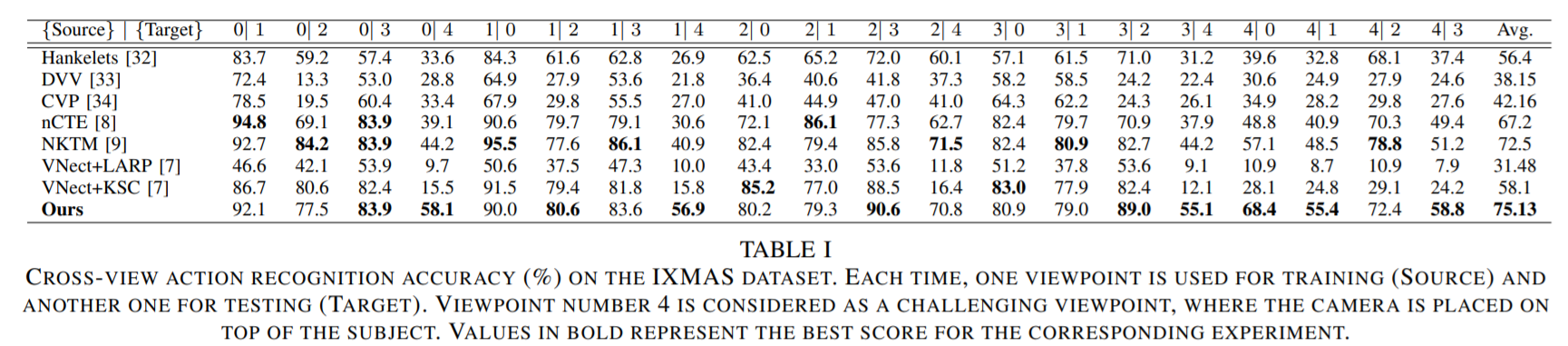
对一些常见算法的对比