论文标题:
来源/作者机构情况:
北京交通大学
解决问题/主要思想贡献:
- 使用特征金字塔
- 对时间采用时间不同粗细度来提取特征
成果/优点:
- 动作识别率有所提升
缺点:
感觉在搬其他人现有的方法
反思改进/灵感:
这个时间段划分的大小,能不能自动学习得到,而不是自己调整的
论文主要内容与关键点:
- 1.前沿
- 2相关工作
- 3.提出的模型

- spatial:网络初试参数来自Res_net34,为了可以Deep
- 对采样的图片,low层2828,mid层1414,high层7*7
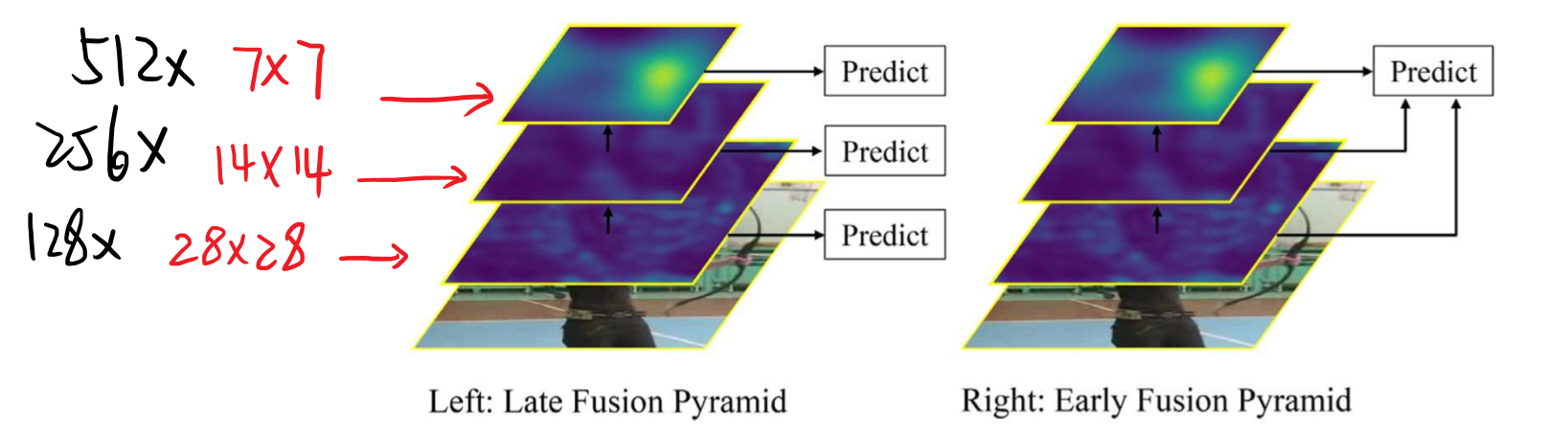
- 采用global pooling,并且后面接1*1的Conv,为了改变CHANEL的数量
- temple:采用组集的采样,分为三种情况(每组两帧,三帧,四帧)然后在每一组使用max pooling。后面直接把各个组的情况concat。这样就得到三组大的特征组
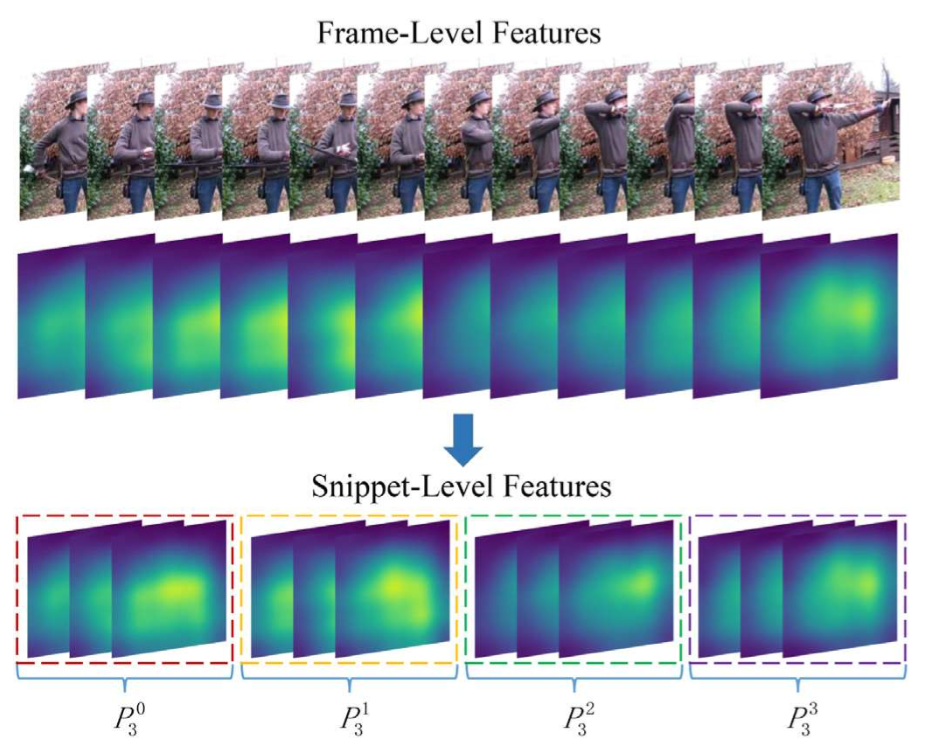

- 最后使用加权平均,把这些特征组变成混合特征,
- 4.讲了一些权值的设置,和数据集的介绍
- 5.实验
- 5.1 不同时间间隔的结果,会发现针对长时间的动作,粗的时间推理好;短时间动作,精细时间推理好!
- 5.2 later fusion比其他的特征融合会稍微好一些
- 5.3 有空间卷积,可以提升4%
- 5.4 目前sof的结果对比,作者的方法不是最好的,原因是硬件和图像的大小方面都有所牺牲
- 6.总结