论文标题:Action recognition based on 2D skeletons extracted from RGB videos
发表时间:02 April 2019
解决问题/主要思想:来源:谷歌最新论文推荐,来自全球排名大概550名的蒙斯大学
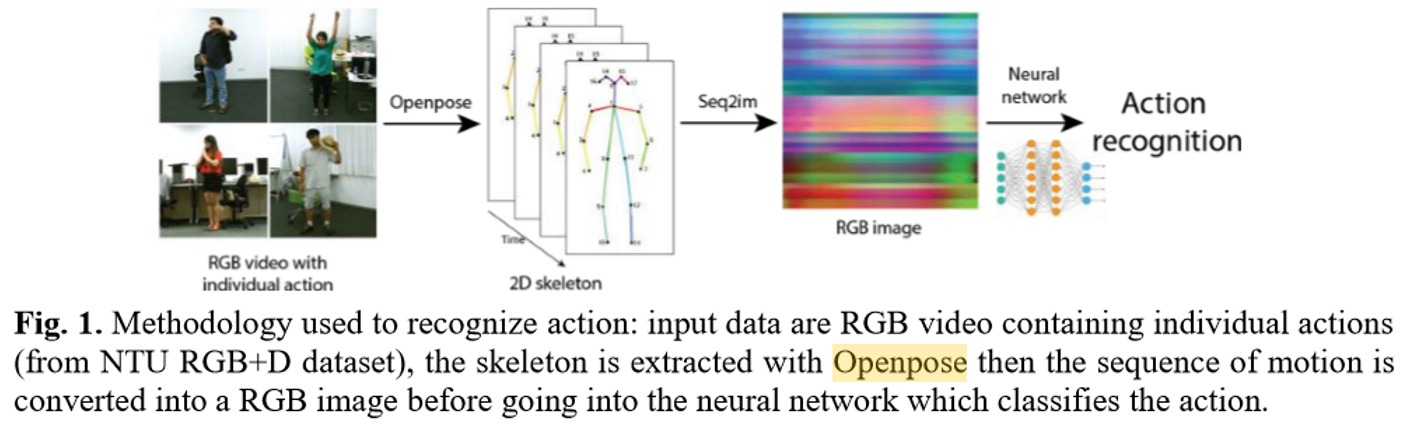
使用openPose对图像提取关键点,然后计算关键点的信息,分成三个矩阵,输入网络训练,从而对动作进行分类
成果/优点:
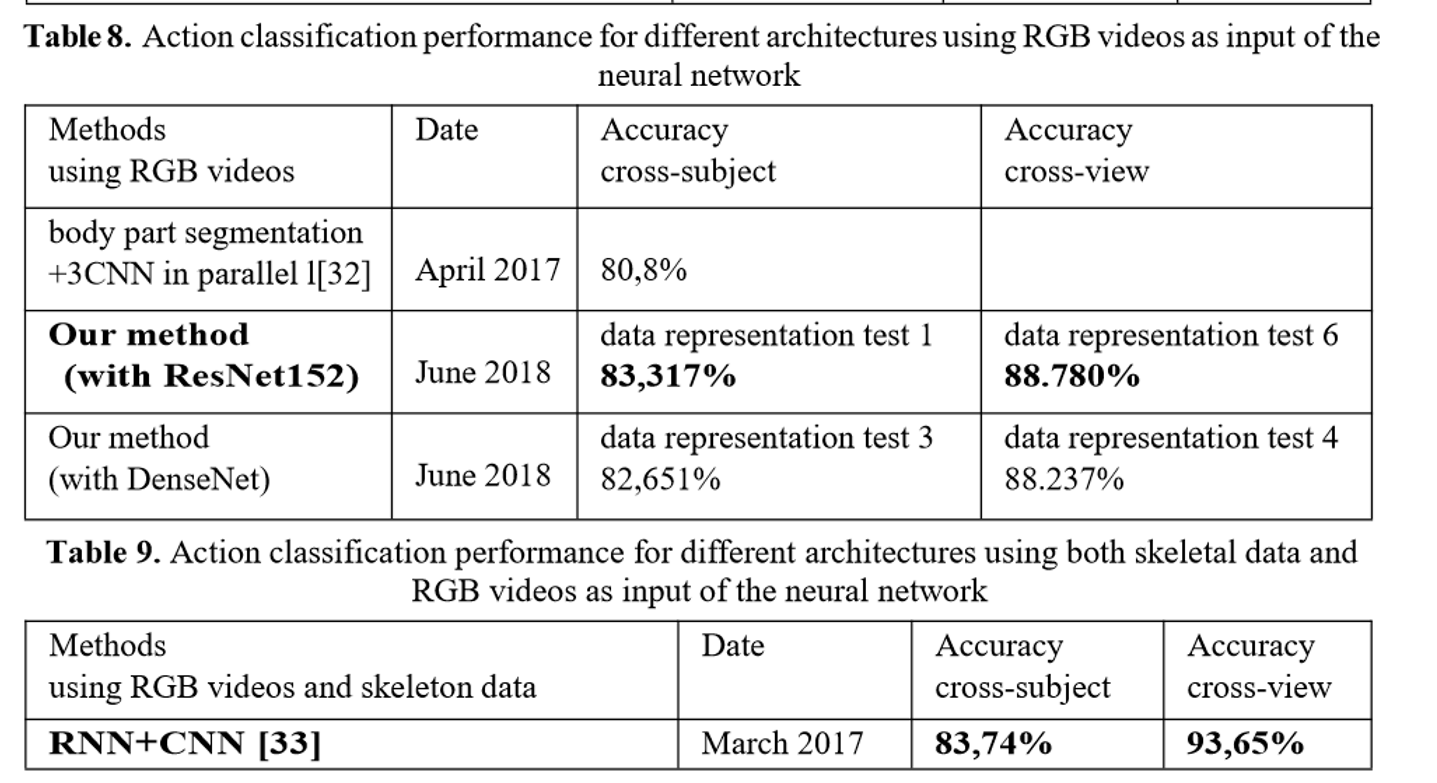
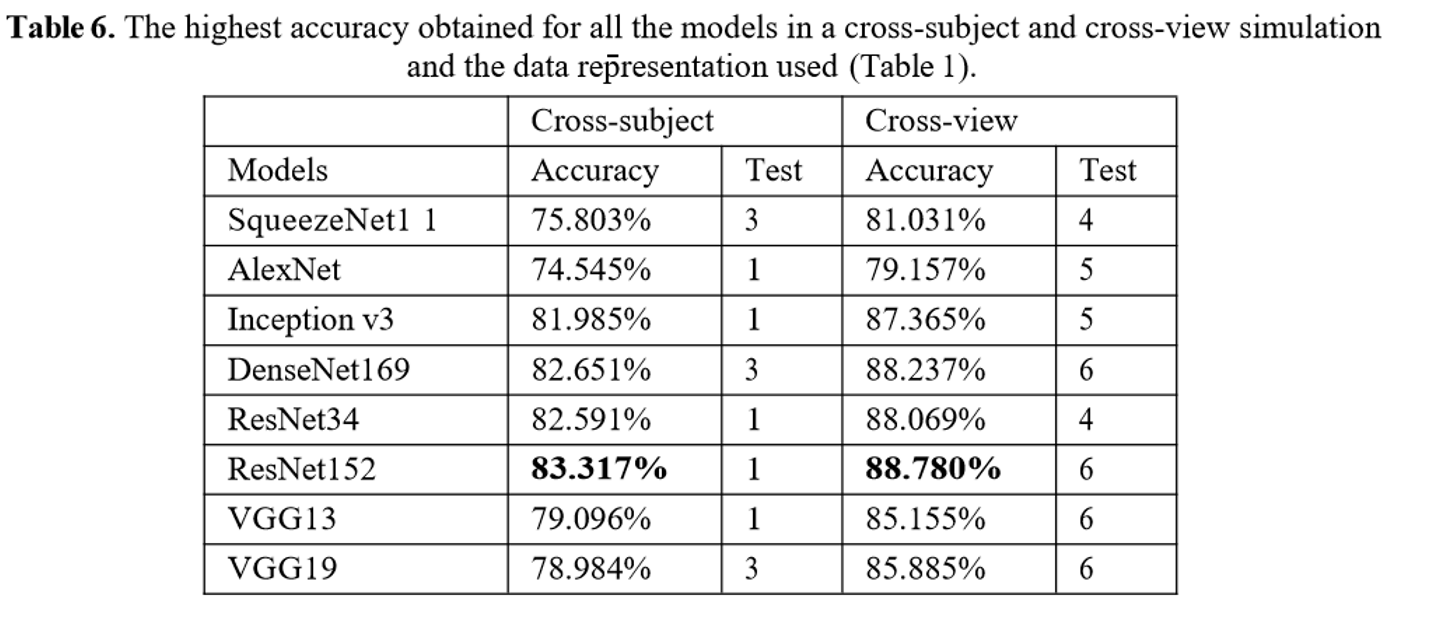
the highest accuracy which is 83.317% with ResNet152 in cross- subject.
缺点:
具体内容:


openPose还没有研究的很深入,下次阅读一下

七个目前基于pose方面的动作识别的前沿进展:



3.1.使用openPose抓取人物关键点

3.2.数据的转换
提取出关键点位置信息和置信度信息之后,对这些数据进行结构上的调整,XYC分别属于一个矩阵,每一行是时间变化,每一列是每一个关键点对应的x
这样安排,估计是把每一个结点的位置信息和时间信息放在一起,这样的话,对网络可以用到位置和时间特征。

3.3各类测试
1.把c换成 (x+y)/2

2.去掉信息量小的眼睛耳朵信息
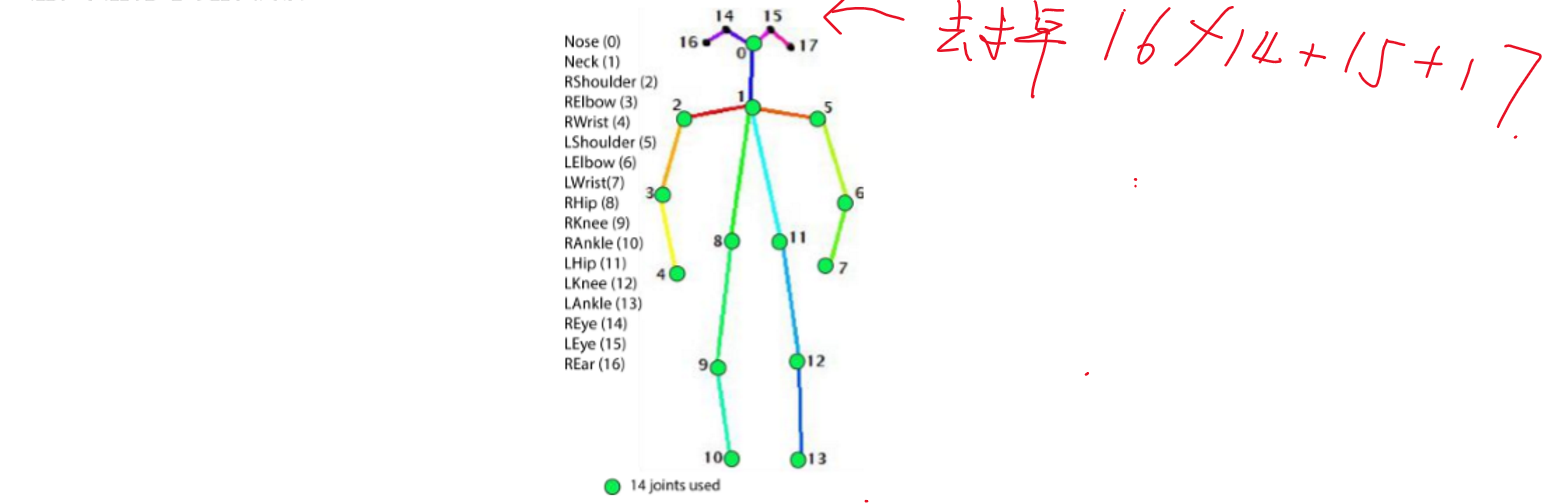
3.改变训练时的结点组合情况

最终测试结果:

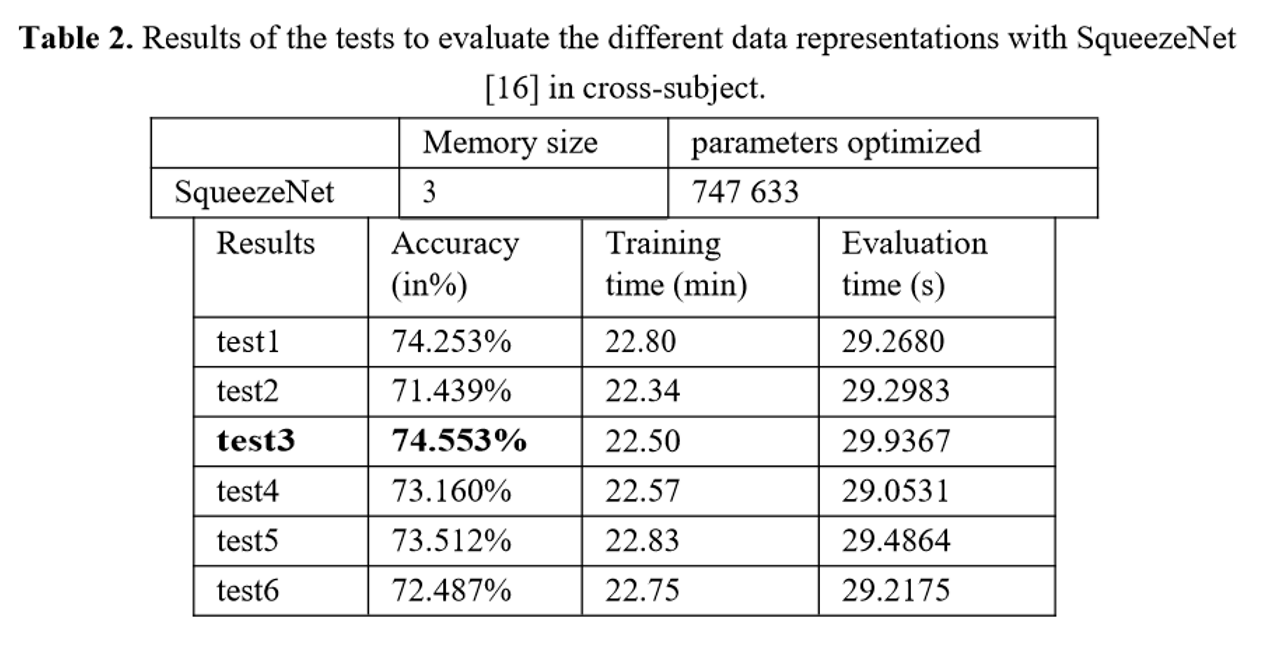

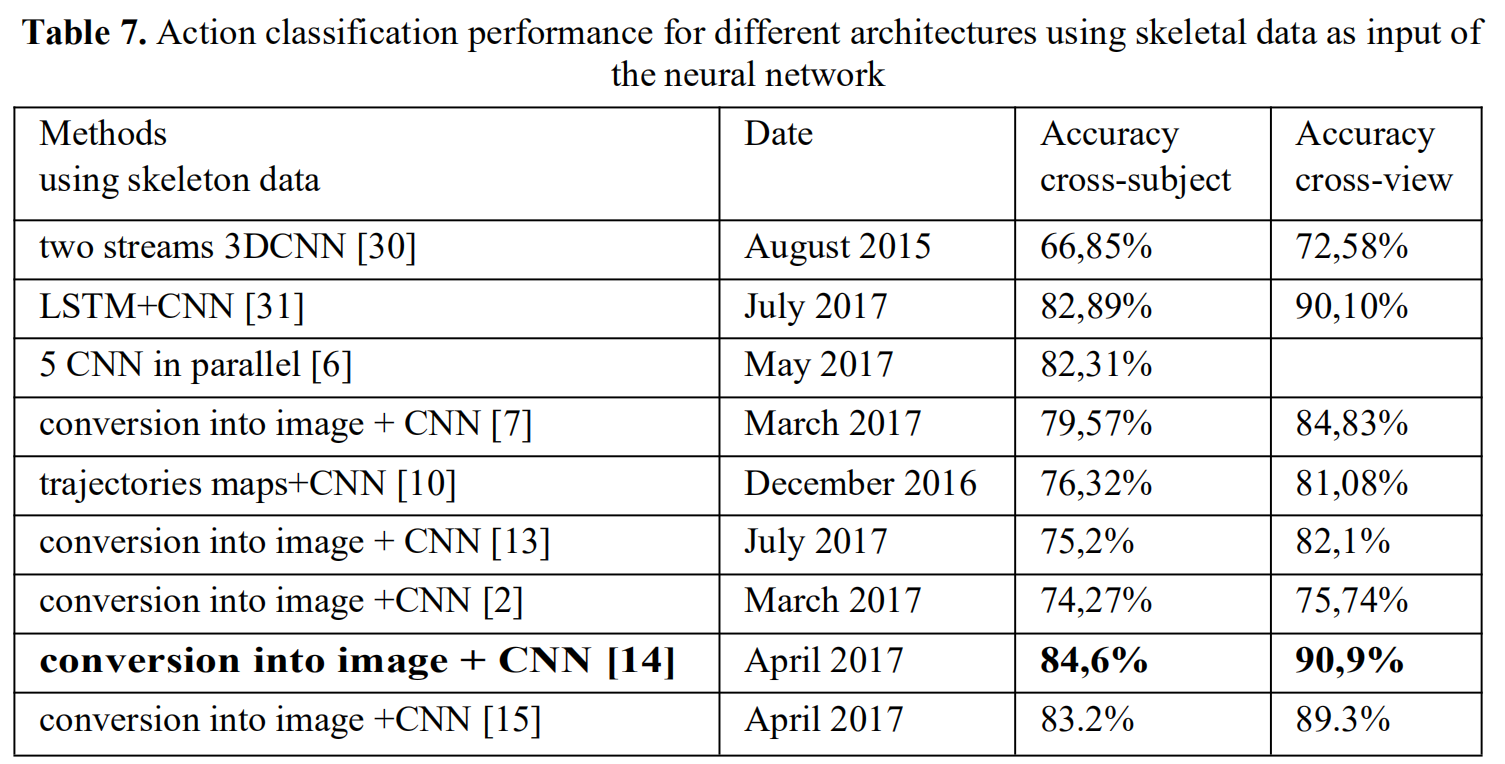
5.1模型比较

5.2 深层网络还是浅层
深层表示训练全部的层
浅层表示:冻结底层的参数,只训练最后的分类层
结果显示,深层比较好

5.3物体交叉,视觉交叉
cross subject,即测试集中的人和训练集中的人没有交集
另一种是cross view,即测试数据的拍摄角度和训练数据不同。
![]()